flink 1.11.2 学习笔记(2)-Source/Transform/Sink
一、flink处理的主要过程
从上一节wordcount的示例可以看到,flink的处理过程分为下面3个步骤:
1.1 、添加数据源addSource,这里的数据源可以是文件,网络数据流,MQ,Mysql...
1.2、数据转换(或者称为数据处理),比如wordcount里的处理过程,就是把一行文本,按空格拆分成单词,并按单词计数
1.3、将处理好的结果,输出(或下沉)到目标系统,这里的目标系统,可以是控制台、MQ、Redis、Mysql、ElasticSearch...
可能有同学有疑问,上节wordcount里,最后的结果只是调用了1个print方法,好象并没有addSink的过程?
org.apache.flink.streaming.api.datastream.DataStream#print() 可以看下这个方法的源码:
/**
* Writes a DataStream to the standard output stream (stdout).
*
* <p>For each element of the DataStream the result of {@link Object#toString()} is written.
*
* <p>NOTE: This will print to stdout on the machine where the code is executed, i.e. the Flink
* worker.
*
* @return The closed DataStream.
*/
@PublicEvolving
public DataStreamSink<T> print() {
PrintSinkFunction<T> printFunction = new PrintSinkFunction<>();
return addSink(printFunction).name("Print to Std. Out");
}
其实最后1行,就已经调用了addSink
二、kafka基本操作
下面将把之前WordCount的流式处理版本,其中的Source与Sink改成常用的Kafka:
注:不熟悉kafka的同学,可以参考下面的步骤学习kafka的常用命令行(kafka老手可跳过)
到kafka官网下载最新的版本,并解压到本机。


1 <dependency>
2 <groupId>org.apache.flink</groupId>
3 <artifactId>flink-connector-kafka-0.11_2.12</artifactId>
4 <version>1.11.2</version>
5 </dependency>
代码:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("zookeeper.connect", "localhost:2181");
props.put("group.id", "test-read-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "latest"); DataStreamSource<String> text = env.addSource(new FlinkKafkaConsumer011<>(
"test1",
new SimpleStringSchema(),
props));
添加Transform
DataStream<Tuple2<String, Integer>> counts = text.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
//将每行按word拆分
String[] tokens = value.toLowerCase().split("\\b+");
//收集(类似:map-reduce思路)
for (String token : tokens) {
if (token.trim().length() > 0) {
out.collect(new Tuple2<>(token.trim(), 1));
}
}
}
})
//按Tuple2里的第0项,即:word分组
.keyBy(value -> value.f0)
//然后对Tuple2里的第1项求合
.sum(1);
添加Sink
counts.addSink(new FlinkKafkaProducer010<>("localhost:9092", "test2",
(SerializationSchema<Tuple2<String, Integer>>) element -> ("(" + element.f0 + "," + element.f1 + ")").getBytes()));
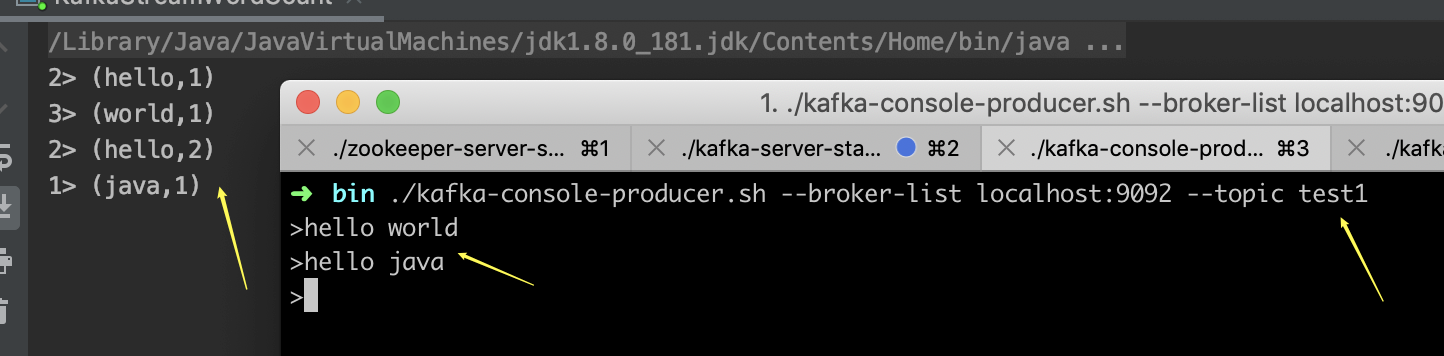
如上图,程序运行起来后,在kafka的proceduer终端,随便输入一些word,相当于发送消息给flink,然后idea的console控制台,输出的统计结果。
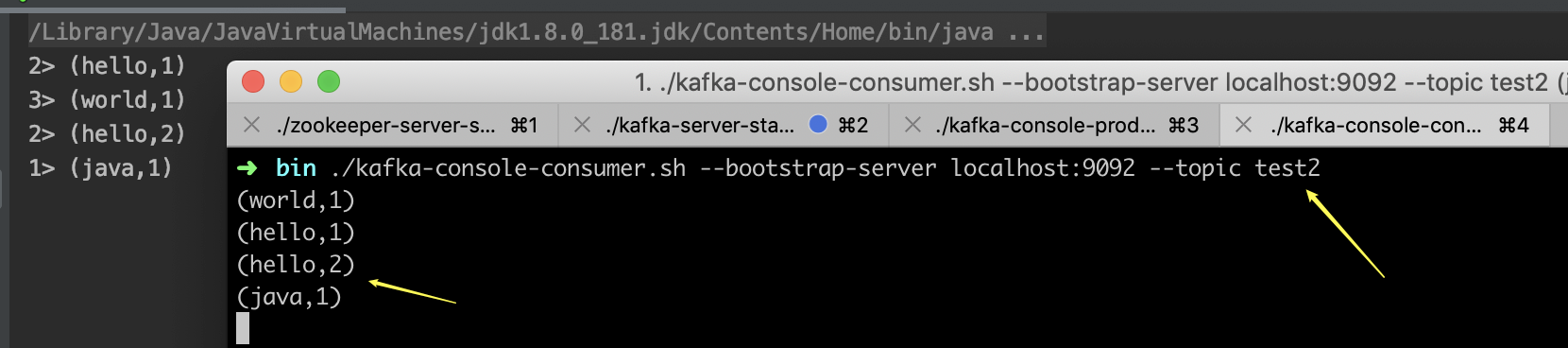
如果此时,再开一个kafka的consumer,可以看到统计结果,也同步发送到了test2这个topic,即实现了kafka的sink.
附:
完整pom文件
1 <?xml version="1.0" encoding="UTF-8"?>
2 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
3 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
4 <modelVersion>4.0.0</modelVersion>
5
6 <groupId>com.cnblogs.yjmyzz</groupId>
7 <artifactId>flink-demo</artifactId>
8 <version>0.0.1-SNAPSHOT</version>
9
10 <properties>
11 <java.version>1.8</java.version>
12 <flink.version>1.11.2</flink.version>
13 </properties>
14
15 <dependencies>
16
17 <!-- flink -->
18 <dependency>
19 <groupId>org.apache.flink</groupId>
20 <artifactId>flink-core</artifactId>
21 <version>${flink.version}</version>
22 </dependency>
23
24 <dependency>
25 <groupId>org.apache.flink</groupId>
26 <artifactId>flink-java</artifactId>
27 <version>${flink.version}</version>
28 </dependency>
29
30 <dependency>
31 <groupId>org.apache.flink</groupId>
32 <artifactId>flink-scala_2.12</artifactId>
33 <version>${flink.version}</version>
34 </dependency>
35
36 <dependency>
37 <groupId>org.apache.flink</groupId>
38 <artifactId>flink-clients_2.12</artifactId>
39 <version>${flink.version}</version>
40 </dependency>
41
42 <!--kafka-->
43 <dependency>
44 <groupId>org.apache.flink</groupId>
45 <artifactId>flink-connector-kafka-0.11_2.12</artifactId>
46 <version>1.11.2</version>
47 </dependency>
48
49 <dependency>
50 <groupId>org.apache.flink</groupId>
51 <artifactId>flink-test-utils-junit</artifactId>
52 <version>${flink.version}</version>
53 </dependency>
54 </dependencies>
55
56 <repositories>
57 <repository>
58 <id>central</id>
59 <layout>default</layout>
60 <url>https://repo1.maven.org/maven2</url>
61 </repository>
62 <repository>
63 <id>bintray-streamnative-maven</id>
64 <name>bintray</name>
65 <url>https://dl.bintray.com/streamnative/maven</url>
66 </repository>
67 </repositories>
68
69 <build>
70 <plugins>
71 <plugin>
72 <artifactId>maven-compiler-plugin</artifactId>
73 <version>3.1</version>
74 <configuration>
75 <source>1.8</source>
76 <target>1.8</target>
77 </configuration>
78 </plugin>
79
80 <!-- Scala Compiler -->
81 <plugin>
82 <groupId>net.alchim31.maven</groupId>
83 <artifactId>scala-maven-plugin</artifactId>
84 <version>4.4.0</version>
85 <executions>
86 <execution>
87 <id>scala-compile-first</id>
88 <phase>process-resources</phase>
89 <goals>
90 <goal>compile</goal>
91 </goals>
92 </execution>
93 </executions>
94 <configuration>
95 <jvmArgs>
96 <jvmArg>-Xms128m</jvmArg>
97 <jvmArg>-Xmx512m</jvmArg>
98 </jvmArgs>
99 </configuration>
100 </plugin>
101
102 </plugins>
103 </build>
104
105 </project>
完整java文件
package com.cnblogs.yjmyzz.flink.demo; import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.serialization.SerializationSchema;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer010;
import org.apache.flink.util.Collector; import java.util.Properties; /**
* @author 菩提树下的杨过(http://yjmyzz.cnblogs.com/)
*/
public class KafkaStreamWordCount { public static void main(String[] args) throws Exception { // 1 设置环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2. 定义数据
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("zookeeper.connect", "localhost:2181");
props.put("group.id", "test-read-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "latest"); DataStreamSource<String> text = env.addSource(new FlinkKafkaConsumer011<>(
"test1",
new SimpleStringSchema(),
props)); // 3. 处理逻辑
DataStream<Tuple2<String, Integer>> counts = text.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
//将每行按word拆分
String[] tokens = value.toLowerCase().split("\\b+"); //收集(类似:map-reduce思路)
for (String token : tokens) {
if (token.trim().length() > 0) {
out.collect(new Tuple2<>(token.trim(), 1));
}
}
}
})
//按Tuple2里的第0项,即:word分组
.keyBy(value -> value.f0)
//然后对Tuple2里的第1项求合
.sum(1); // 4. 打印结果
counts.addSink(new FlinkKafkaProducer010<>("localhost:9092", "test2",
(SerializationSchema<Tuple2<String, Integer>>) element -> ("(" + element.f0 + "," + element.f1 + ")").getBytes()));
counts.print(); // execute program
env.execute("Kafka Streaming WordCount"); }
}
flink 1.11.2 学习笔记(2)-Source/Transform/Sink的更多相关文章
- 1-1 maven 学习笔记(1-6章)
一.基础概念 1.Maven作为Apache组织中颇为成功的开源项目,主要服务于基于Java平台的项目构建,依赖管理和项目信息管理.从清理,编译,测试到生成报告,到打包部署,自动化构建过程. 还可以跨 ...
- Linux(10.5-10.11)学习笔记
3.2程序编码 unix> gcc -01 -o p p1.c p2.c -o用于指定输出(out)文件名. -01,-02 告诉编译器使用第一级或第二级优化 3.2.1机器级代码 机器级编程两 ...
- (11)学习笔记 ) ASP.NET CORE微服务 Micro-Service ---- Thrift高效通讯 (完结)
一. 什么是 RPC Restful 采用 Http 进行通讯,优点是开放.标准.简单.兼容性升级容易: 缺点是性能略低.在 QPS 高或者对响应时间要求苛刻的服务上,可以用 RPC(Remote P ...
- 1-1.flutter学习笔记(一)git入门(msysgit图文安装)
1.下载git-for-windows (1)常用的GitHub客户端msysgit,也就是git-for-windows. (2)登录官网 https://git-for-windows.githu ...
- c++11多线程学习笔记之一 thread基础使用
没啥好讲的 c++11 thread类的基本使用 #include "stdafx.h" #include <iostream> #include <thre ...
- 机器学习11—Apriori学习笔记
votesmart下载 https://pypi.python.org/pypi/py-votesmart test11.py #-*- coding:utf-8 import sys sys.pa ...
- 11.Laravel5学习笔记:扩展 Validator 类
简单介绍 在 Laravel5 中,本身已经提供了丰富的验证规则供我们使用,可是天下应用奇葩多,做为程序猿你会发现永远都有新的验证规则诞生,光是组合已经解救不了你的项目了.这个时候就须要我们扩展 Va ...
- c++11多线程学习笔记之四 生产消费者
#ifndef MY_QUEUE_H__ #define MY_QUEUE_H__ #include<list> #include<mutex> #include<thr ...
- c++11多线程学习笔记之三 condition_variable使用
从windows角度来说,condition_variable类似event. 阻塞等待出发,不过condition_variable可以批量出发. 代码如下: // 1111111.cpp : 定义 ...
- c++11多线程学习笔记之二 mutex使用
// 1111111.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include <iostream> #include ...
随机推荐
- 使用PowerShell开发脚本程序进行批量SVN提交
使用PowerShell开发脚本程序进行批量SVN提交 随着软件开发的不断进步,版本控制系统如Subversion (SVN) 成为了团队协作和代码管理的重要工具.当需要一次性提交大量文件时,手动操作 ...
- 3.4K star!全能PDF处理神器开源!文档转换/OCR识别一键搞定
嗨,大家好,我是小华同学,关注我们获得"最新.最全.最优质"开源项目和高效工作学习方法 PDF-Guru 是一款开箱即用的全能型PDF处理工具,支持跨平台文档转换.智能OCR识别. ...
- 【经验】VMware|Win11的Ubuntu虚拟机启动虚拟化,报错此平台不支持虚拟化的 Intel VT-x/EPT(方案汇总+自己的解决方案)
2024/04/24说明:这篇暂时修改为粉丝可见,因为正在冲粉丝量,等到我弄完了粉丝量的要求,我就改回来!不方便看到全文的小伙伴不好意思!! 我开虚拟化是为了在虚拟机中运行VirtualBox,如果不 ...
- Web前端入门第 52 问:JavaScript 的应用领域
截至目前,您应该对前端的 HTML + CSS 应该有了很清楚的认知,至少实现一个静态网页已经完全不在话下了. 当然,CSS 功能绝不止这些,一些不太常用的 CSS 相关知识,后续将通过案例进行分享. ...
- Linux安装Libevent
环境 Ubuntu 20.04.2 64位 软件包安装 通过apt-get 命令可以直接安装Libevent,这种方式方便快捷,省时省力. 安装命令如下: sudo apt-get install l ...
- 问题描述:libGL.so.1: cannot open shared object file: No such file or directory
问题截图: 在实验室服务器上跑代码,报如上错误 解决方案: sudo apt update sudo apt install libgl1-mesa-glx 因遇见多次该错误,特此记录下 (据说该问题 ...
- Pycomcad实现Autocad橡皮线效果
import sys sys.path.append(r'F:\PycharmProject\PycomCAD') from pycomcad import * def tryit(): acad.I ...
- TEA密码与逆向工程
前置信息 TEA系列概述:TEA算法是一种分组密码算法,由剑桥大学计算机实验室的David Wheeler和Roger Needham于1994年发明.它使用64位的明文分组和128位的密钥进行加 ...
- 2、Java语言基础知识
数据类型及范围 四种:整型(byte,short,int,long).浮点型(float,double).字符型(char).布尔型(true,false) 类型 byte short int lon ...
- Java线程状态和状态切换
背景 先来探讨一个关于多线程的基础知识:java线程有多少种状态?根据JDK定义,答案是六种!为什么很多人给出的答案却是五种呢?这极有可能是将操作系统层面的线程状态和Java线程状态混为一谈了.因 ...