大数据之路Week08_day02 (Flume的使用举例(从控制台输入数据,从本地打数据到HDFS,从java代码中进行捕获打入到HDFS,flume监控http source))
在使用之前,提供一个大致思想,使用Flume的过程是确定scource类型,channel类型和sink类型,编写conf文件并开启服务,在数据捕获端进行传入数据流入到目的地。
实例一、从控制台打入数据,在控制台显示
1、确定scource类型,channel类型和sink类型
确定的使用类型分别是,netcat source, memory channel, logger sink.
2、编写conf文件
#a代表agent的名称,r1代表source的名称。c1代表channel名称,k1代表的是sink的名称
#声明各个组件
a.sources=r1
a.channels=c1
a.sinks=k1
#定义source类型,这里是试用netcat的类型
a.sources.r1.type=netcat
a.sources.r1.bind=192.168.230.50
a.sources.r1.port=8888
#定义source发送的下游channel
a.sources.r1.channels=c1
#定义channel
a.channels.c1.type=memory
#缓存的数据条数
a.channels.c1.capacity=1000
#事务数据量
a.channels.c1.transactionCapacity=1000
#定义sink的类型,确定上游channel
a.sinks.k1.channel=c1
a.sinks.k1.type=logger
3、开启服务,我们重新开启复制一个客户端进行开启服务
命令:
flume-ng agent -n a -c ../conf -f ./netcat.conf -Dflume.root.logger=DEBUG,console (注意:-n 后面跟着的是你在conf文件中定义好的,-f 后面跟着的是编写conf文件的路径)
在另一个客户端输入命令:
telnet master 8888 (注意:这里的master和8888是在conf文件中设置好的ip地址和端口)
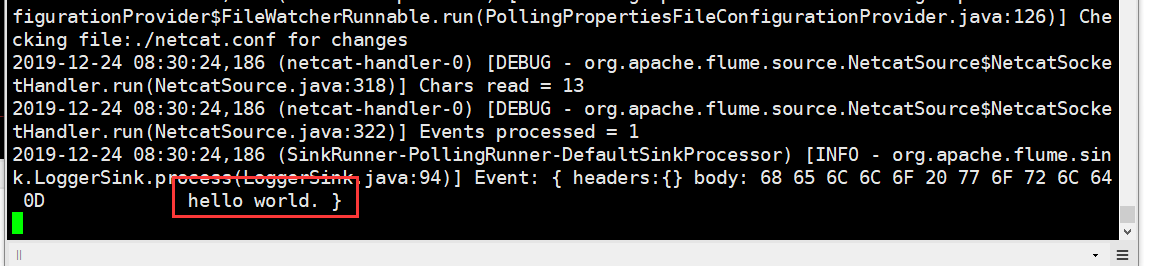
在输入第二个命令的窗口中输入数据,回车,在服务端就会接收到数据。如图

接收的数据:
实例二、从本地指定路径中打入数据到HDFS
1、同样,我们需要先确定scource类型,channel类型和sink类型
我们确定使用的类型分别是,spooldir source, memory channle, hdfs sink
2、编写conf文件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#指定spooldir的属性
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /usr/local/soft/flumedata
#时间拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = timestamp
#指定sink的类型
a1.sinks.k1.type = hdfs
#指定hdfs的集群地址和路径,路径如果没有创建会自动创建
a1.sinks.k1.hdfs.path =hdfs://master:9000/usr/test/log_s/dt=%Y-%m-%d
#指定hdfs路径下生成的文件的前缀
a1.sinks.k1.hdfs.filePrefix = log_%Y-%m-%d
#手动指定hdfs最小备份
a1.sinks.k1.hdfs.minBlockReplicas=1
#设置数据传输类型
a1.sinks.k1.hdfs.fileType = DataStream
#如果参数为0,不按照条数生成文件。如果参数为n,就是按照n条生成一个文件
a1.sinks.k1.hdfs.rollCount = 1000
#这个参数是hdfs下文件sink的数据size。每sink 32MB的数据,自动生成一个文件
a1.sinks.k1.hdfs.rollSize =0
#每隔n 秒 将临时文件滚动成一个目标文件。如果是0,就不按照时间进行生成目标文件。
a1.sinks.k1.hdfs.rollInterval =0
a1.sinks.k1.hdfs.idleTimeout=0
#指定channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#组装
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
3、开启服务
flume-ng agent -n a1 -c ../conf -f ./spool2hdfs2.conf -Dflume.root.logger=DEBUG, console
将文件复制到指定的目录下
cp commodity.csv /usr/local/soft/flumedata/
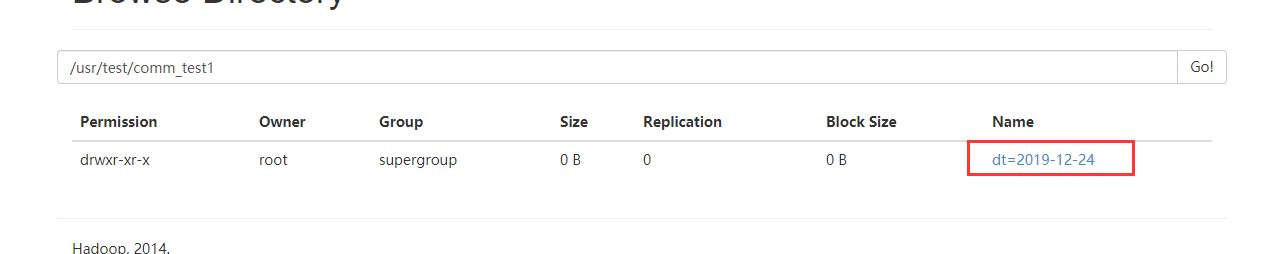
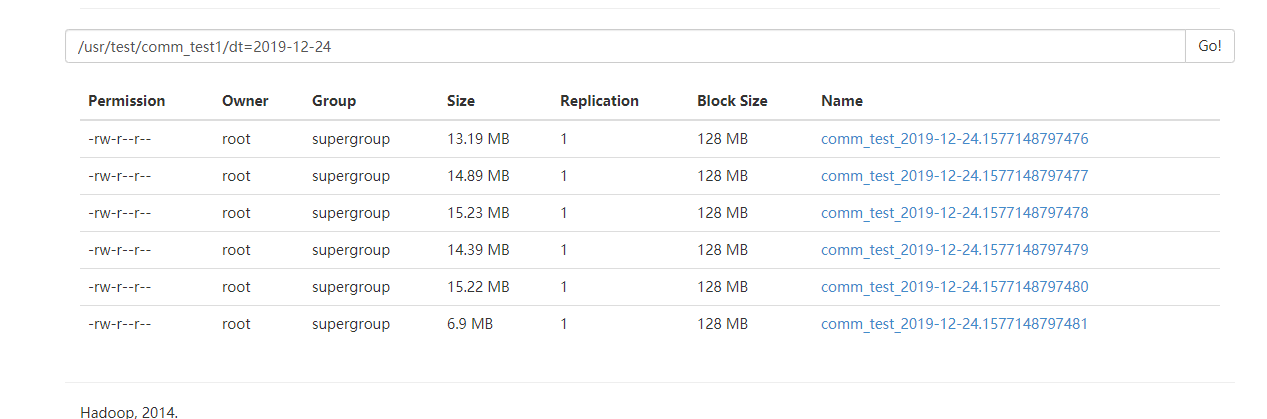
去HDFS上查看结果

实例三、从java代码中进行捕获打入到HDFS
1、先确定scource类型,channel类型和sink类型
确定的三个组件的类型是,avro source, memory channel, hdfs sink.
2、打开maven项目,添加依赖
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.6.0</version>
</dependency> <dependency>
<groupId>org.apache.flume.flume-ng-clients</groupId>
<artifactId>flume-ng-log4jappender</artifactId>
<version>1.6.0</version>
</dependency>
3、设置log4J的内容
log4j.rootLogger=INFO,stdout,flume log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c] [%p] - %m%n log4j.appender.flume = org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.flume.Hostname = 192.168.230.50
log4j.appender.flume.Port = 41414
log4j.appender.flume.UnsafeMode = true
log4j.appender.flume.layout=org.apache.log4j.PatternLayout
log4j.appender.flume.layout.ConversionPattern=%m%n
4、编写conf文件
#定义agent名, source、channel、sink的名称
a.sources = r1
a.channels = c1
a.sinks = k1 #具体定义source
a.sources.r1.type = avro
a.sources.r1.bind = 192.168.230.50
a.sources.r1.port = 41414 #具体定义channel
a.channels.c1.type = memory
a.channels.c1.capacity = 10000
a.channels.c1.transactionCapacity = 100 #具体定义sink
a.sinks.k1.type = hdfs
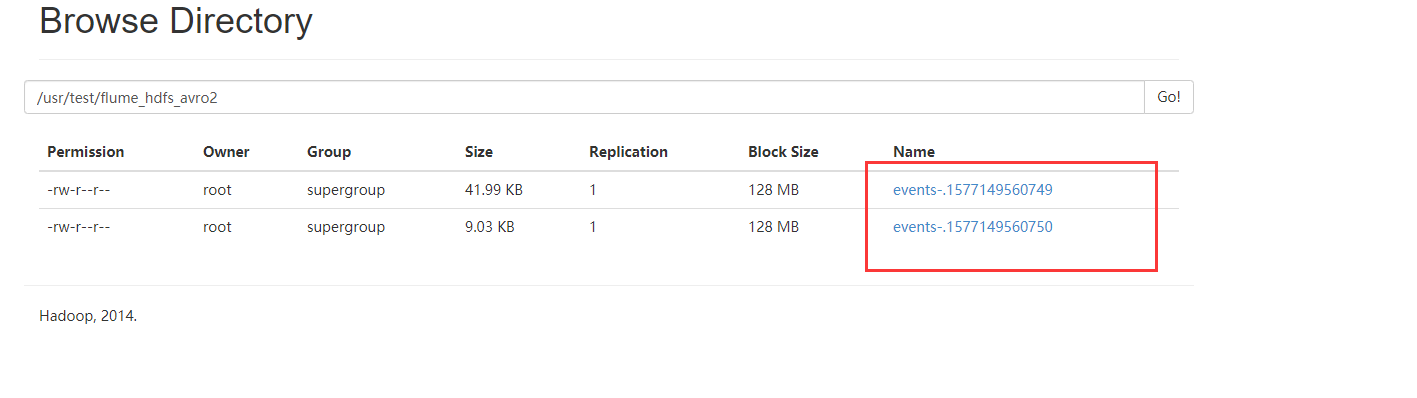
a.sinks.k1.hdfs.path =hdfs://master:9000/usr/test/flume_hdfs_avro2
a.sinks.k1.hdfs.filePrefix = events-
a.sinks.k1.hdfs.minBlockReplicas=1
a.sinks.k1.hdfs.fileType = DataStream
#a.sinks.k1.hdfs.fileType = CompressedStream
#a.sinks.k1.hdfs.codeC = gzip
#不按照条数生成文件
a.sinks.k1.hdfs.rollCount = 1000
a.sinks.k1.hdfs.rollSize =0
#每隔N s将临时文件滚动成一个目标文件
a.sinks.k1.hdfs.rollInterval =0
a.sinks.k1.hdfs.idleTimeout=0
#组装source、channel、sink a.sources.r1.channels = c1
a.sinks.k1.channel = c1
5、开启服务,命令:
flume-ng agent -n a -c ../conf -f ./avro2hdfs2.conf -Dflume.root.logger=DEBUG,console

6、运行Java代码

7、查看HDFS

实例四、flume监控Http source
1、先确定scource类型,channel类型和sink类型
确定的三个组件的类型是,http source, memory channel, logger sink.
2、编写conf文件
a1.sources=r1
a1.sinks=k1
a1.channels=c1 a1.sources.r1.type=http
a1.sources.r1.bind=duan140
a1.sources.r1.port=50000
a1.sources.r1.channels=c1 a1.sinks.k1.type=logger
a1.sinks.k1.channel=c1 a1.channels.c1.type=memory
a1.channels.c1.capacity=10000
a1.channels.c1.transactionCapacity=100
3、启动服务
flume-ng agent -f ./http.conf -n a1
4、复制一个窗口进行打数据
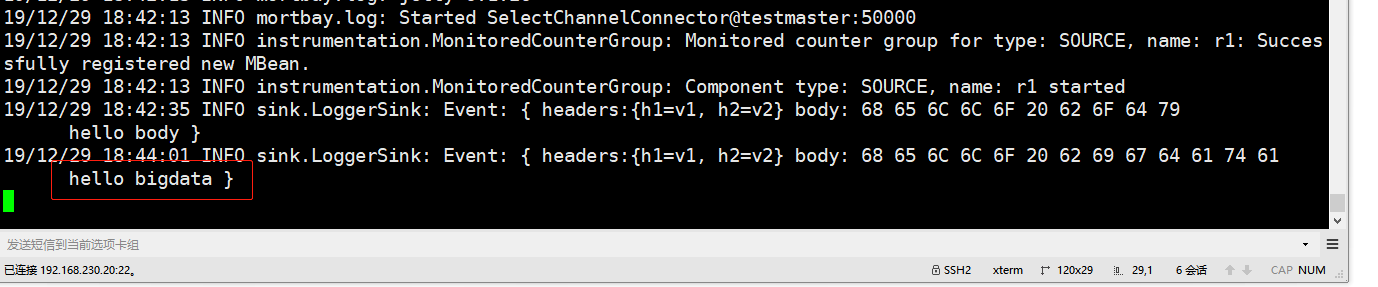
curl -X POST -d'[{"headers":{"h1":"v1","h2":"v2"},"body":"hello bigdata"}]' http://192.168.230.20:50000
5、查看结果
大数据之路Week08_day02 (Flume的使用举例(从控制台输入数据,从本地打数据到HDFS,从java代码中进行捕获打入到HDFS,flume监控http source))的更多相关文章
- 大数据之路week07--day01(HDFS学习,Java代码操作HDFS,将HDFS文件内容存入到Mysql)
一.HDFS概述 数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统 ...
- 大数据之路week06--day07(Hadoop生态圈的介绍)
Hadoop 基本概念 一.Hadoop出现的前提环境 随着数据量的增大带来了以下的问题 (1)如何存储大量的数据? (2)怎么处理这些数据? (3)怎样的高效的分析这些数据? (4)在数据增长的情况 ...
- C#码农的大数据之路 - 使用C#编写MR作业
系列目录 写在前面 从Hadoop出现至今,大数据几乎就是Java平台专属一般.虽然Hadoop或Spark也提供了接口可以与其他语言一起使用,但作为基于JVM运行的框架,Java系语言有着天生优势. ...
- 胖子哥的大数据之路(6)- NoSQL生态圈全景介绍
引言: NoSQL高级培训课程的基础理论篇的部分课件,是从一本英文原著中做的摘选,中文部分参考自互联网.给大家分享. 正文: The NoSQL Ecosystem 目录 The NoSQL Eco ...
- 大数据之路week01--day02我实在时被继承super这些东西搞的头疼,今天来好好整理以下。
这一周的第一天的内容是面向对象的封装,以及对方法的调用.实在时没法单独拿出来单说,就结合这一节一起说了. 我实在是被继承中的super用法给弄的有点晕,程序总是不能按照我想的那样,不是说结果,而是实现 ...
- 大数据之路week01--自学之集合_1(Collection)
经过我个人的调查,发现,在今后的大数据道路上,集合.线程.网络编程变得尤为重要,为什么? 因为大数据大数据,我们必然要对数据进行处理,而这些数据往往是以集合形式存放,掌握对集合的操作非常重要. 在学习 ...
- 大数据之路day04_1--数组 and for循环进阶
Java数组 在开始之前,提一个十分重要的一点:注意:在给数组分配内存空间时,必须指定数组能够存储的元素来确定数组大小.创建数组之后不能修改数组的大小,可以使用length属性获取数组的大小.在jav ...
- 大数据之路week07--day06 (Sqoop 将关系数据库(oracle、mysql、postgresql等)数据与hadoop数据进行转换的工具)
为了方便后面的学习,在学习Hive的过程中先学习一个工具,那就是Sqoop,你会往后机会发现sqoop是我们在学习大数据框架的最简单的框架了. Sqoop是一个用来将Hadoop和关系型数据库中的数据 ...
- 大数据之路week04--day03(网络编程)
哎,怎么感觉自己变得懒了起来,更新博客的频率变得慢了起来,可能是因为最近得知识开始变得杂变得难了起来,之前在上课的时候,也没有好好听这一方面的知识,所以,现在可以说是在学的新的知识,要先去把新的知识思 ...
- 大数据之路week02 List集合的子类
1:List集合的子类(掌握) (1)List的子类特点 ArrayList: 底层数据结构是数组,查询快,增删慢. 线程不安全,效率高. Vector: 底层数据结构是数组,查询快,增删慢. 线程安 ...
随机推荐
- 手撕vector
Myclass.h #pragma once #include<iostream> #include<Windows.h> #define SUCCESS 1 // 成功 #d ...
- COSBrowser文件编辑-随时随地在线编辑
本文介绍如何通过COSBrowser文件在线编辑功能更方便的使用云上存储的数据. 痛点分析 日常工作和生活中,我们需要把记录的文档.编写的文案.音视频文件保存管理好,又担心设备损坏.文件丢失或是更换设 ...
- java -jar命令运行jar包时指定外部依赖jar包
你们都知道一个java应用项目能够打包成一个jar,固然你必须指定一个拥有main函数的main class做为你这个jar包的程序入口.具体的方法是修改jar包内目录META-INF下的MANIFE ...
- 动态改变shiro的Principal属性
因为要保存一些用户名之外的内容在shiro中,所以创建了一个ShiroUser的类,当用户修改了某些属性后,如何动态保存到shiro中: Subject subject = SecurityUtils ...
- Karmada v1.12 版本发布!单集群应用迁移可维护性增强
本文分享自华为云社区<Karmada v1.12 版本发布!单集群应用迁移可维护性增强>,作者:云容器大未来. Karmada 是开放的多云多集群容器编排引擎,旨在帮助用户在多云环境下部署 ...
- Qt/C++音视频开发71-指定mjpeg/h264格式采集本地摄像头/存储文件到mp4/设备推流/采集推流
一.前言 用ffmpeg采集本地摄像头,如果不指定格式的话,默认小分辨率比如640x480使用rawvideo格式,大分辨率比如1280x720使用mjpeg格式,当然前提是这个摄像头设备要支持这些格 ...
- Qt/C++摄像头采集/二维码解析/同时采集多路/图片传输/分辨率帧率可调/自动重连
一.前言 本地摄像头的采集可以有多种方式,一般本地摄像头会通过USB的方式连接,在嵌入式上可能大部分是CMOS之类的软带的接口,这些都统称本地摄像头,和网络摄像头最大区别就是一个是通过网络来通信,一个 ...
- Qt/C++开发经验小技巧291-295
国内站点:https://gitee.com/feiyangqingyun 国际站点:https://github.com/feiyangqingyun 关于在pro中区分linux系统,在Qt4套件 ...
- Qt音视频开发18-海康sdk回调
一.前言 海康sdk显示实时视频流除了支持句柄方式以外,也支持回调的方式拿到每一张图片自己绘制处理,当然回调除了拿到视频数据,其实音频数据也一块拿到了,自行调用音频设备播放就行,关于海康sdk回调这块 ...
- Element库的Vue版本ElementUI的本地引入方法
最近刚接触ElementUI,发现官方介绍的使用方法中只有npm安装和CDN引入这两种方式,没有本地引入的方法. 因为我的学习环境有时候是断网状态的,所以自己研究了一下本地引入的方法,记录在此. 1. ...