大数据开源项目,一站式全自动化全生命周期运维管家ChengYing(承影)走向何方?
原文链接:三分钟走进袋鼠云一站式全自动化全生命周期运维管家ChengYing(承影)
课件获取:关注公众号 ** “数栈研习社”,后台私信 “ChengYing”** 获得直播课件
视频回放:点击这里
ChengYing 开源项目地址:github 丨 gitee 喜欢我们的项目给我们点个** STAR!STAR!!STAR!!!**(重要的事情说三遍)
技术交流钉钉qun:30537511
2022年5月30日,袋鼠云对外开源了一站式全自动化运维管家ChengYing(承影),为了帮助社区同学更好的使用ChengYing,自开源之后我们就紧锣密鼓的筹备直播相关事宜,从6月开始,我们将每月为大家组织一次直播,和大家分享ChengYing的相关内容,欢迎大家持续关注。
一、ChengYing简介
ChengYing(承影)——承袭于袋鼠云开源项目名剑家族的概念,取自十大名剑之承影剑。
ChengYing(承影)作为一站式全自动化全生命周期运维管家,提供大数据产品的一站式部署、运维、监控服务,其可实现产品部署、产品升级、版本回滚、扩缩节点、日志诊断、集群监控、实时告警等功能,致力于最大化节省运维成本,降低线上故障率与运维难度,为客户提供安全稳定的产品部署与监控。
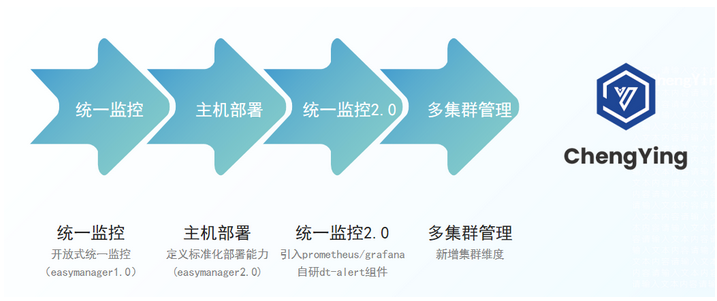
ChengYing脱胎于袋鼠云数栈自主研发的一站式运维管家EasyManager,从开放式统一监控、到定义标准化部署能力,而后引入Prometheus/Grafana/自研dt-alert组件,完成统一监控2.0的功能优化,再到新增多集群管理能力,最后完成了内部孵化,成功开源ChengYing。
二、ChengYing功能特性
在介绍ChengYing的功能特性之前,我们先熟悉几个概念:
名词概念
- 产品
指用ChengYing部署的大数据产品,如数栈(DTinsight)、云日志(EasyLog)等,作为ChengYing最高级别的组织单位。
- 组件
一般和"组件安装包"等同,指产品下包含多个组件,即产品下包含多个组件安装包,如数栈(DTinsight)产品下包含Hadoop、DTBase、DTCommon、DTBatch、DTStream等多个组件,代表不同的应用。
- 服务组
组件下的服务分类,如Hadoop组件下包含HDFS、Spark、Yarn、Flink、Default等服务组,进行服务区分。
- 服务
指服务组下的具体服务,如HDFS服务组下包含hdfs_datanode、hdfs_journalnode、hdfs_namenode、hdfs_zkfc等组件;Spark服务组下包含hivemetastore、spark_historyserver、thriftserver等组件。
- 主机分组
指对主机进行人为分组,当主机数量过多时可进行分组,方便管理。
- 主机
指服务器,包含物理机、虚拟机,指产品部署时需要的硬件资源,通常以主机IP或主机名称进行区分。
功能特性
ChengYing具备六大功能特性:
- 统一的Schema定义
抽象化产品包定义,用一套标准的Schema定义一个产品包的完整的生命周期,包括安装、启动、配置、升级、卸载等。
- 集群管理
支持多集群设置,便于在一套ChengYing系统中部署多套资源隔离的服务;支持对集群中所有产品包、所有主机、集群资源的管理。
- 安装部署
支持产品包的快速安装与部署。
- 服务管理
支持查看各服务及服务实例的运行、健康检查状态;
支持服务的配置修改下发;
支持服务的滚动重启;
支持服务的配置查看。
- 监控告警
集成prometheus/grafana组件作为可视化仪表盘组件监控集群、主机、服务性能检测;支持邮件、短信、钉钉以及自定义告警通道发送告警信息。
- 节点扩容/缩容
支持根据集群运行状况,产品化支持主机资源扩充与缩减。
三、ChengYing系统架构设计
- ChengYing系统架构
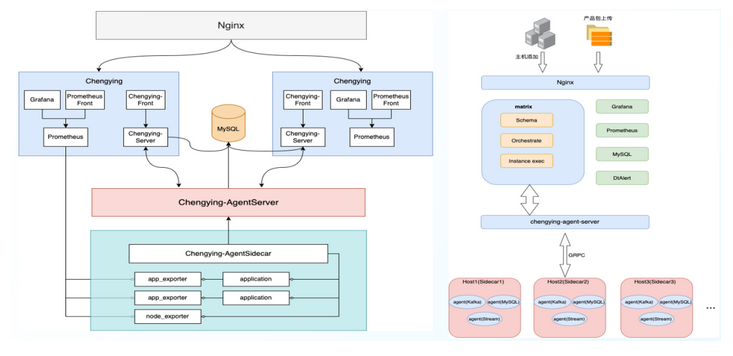
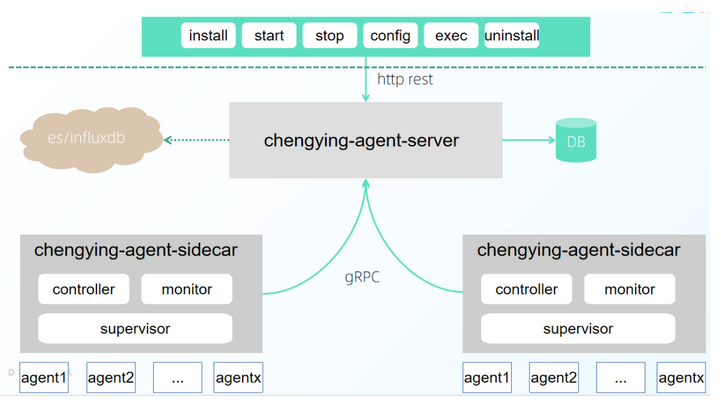
- ChengYing Agent设计
- 统一Schema设计

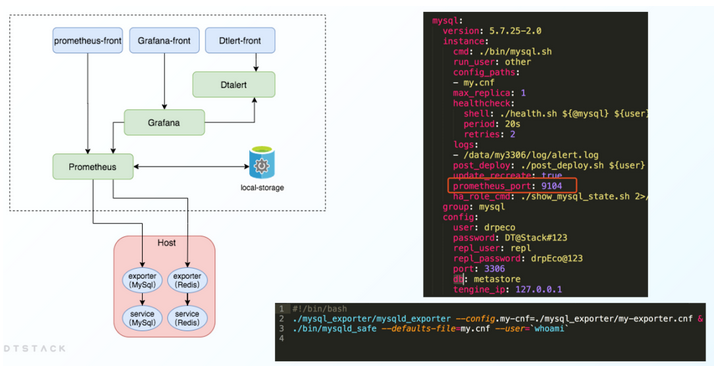
- 监控设计
- 架构设计讲解
由于架构设计讲解的内容比较多,在此我们不做具体回顾,大家可以观看视频进行详细了解。
B站直播回顾地址:
https://www.bilibili.com/video/BV1Ht4y187xo?spm_id_from=333.999.0.0
四、ChengYing快速入门
接下来为大家介绍如何快速部署ChengYing:
- 环境要求

- 快速部署
下载安装包:
https://github.com/DTStack/chengying/releases/download/v1.0.0/chengying-release-1.0.tar.gz
解压安装包:
tar zxvf chengying-release-1.0.tar.gz
cd chengying-release-1.0
运行安装脚本:
sh install.sh local_ip(local_ip为Chengying所在机器ip)
查看页面:
http://local_ip

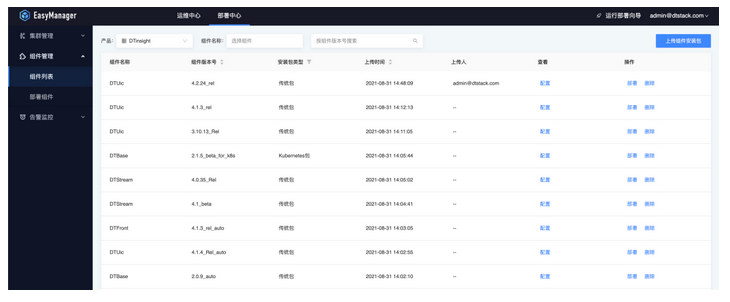
- 上传组件安装包
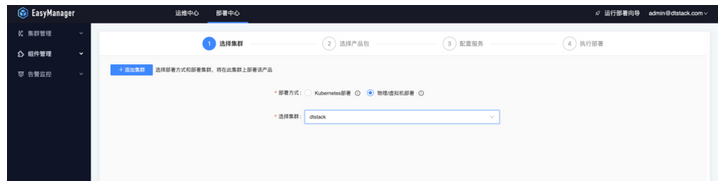
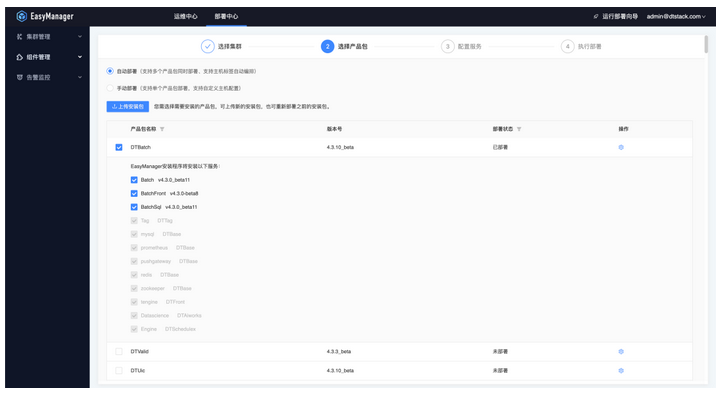
- 选择集群与安装包
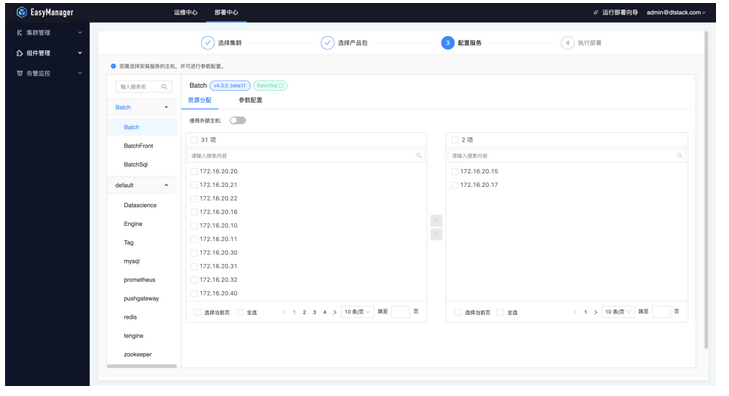
- 配置服务
- 执行部署
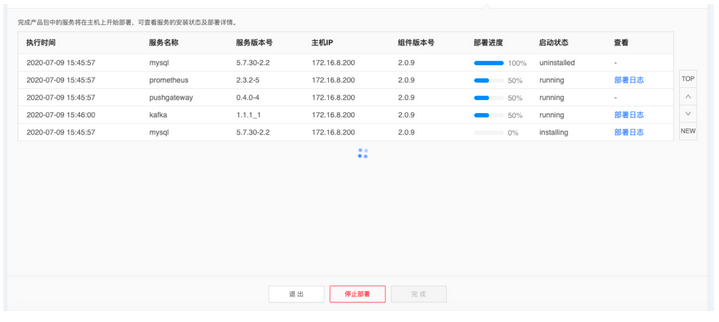
五、ChengYing未来规划
最后为大家介绍ChengYing的未来规划及近期主要做的事情:
未来规划
- 服务编排
支持基于主机角色与服务类型自动编排,减少人工操作成本。
- 部署方式
支持自定义部署产品包流水线顺序。
- 安全认证
支持集群开启Kerberos认证,票据生成与下载。
- 监控告警
支持基于PromQL的自定义告警设置,丰富告警类型。
近期重点事宜
计划8月底发布ChengYing V1.1.0 Release。
每月一次开源技术直播。
与Chunjun/Taier梦幻联动--尝试使用ChengYing部署Chunjun/Taier。
袋鼠云开源框架钉钉技术交流qun(30537511),欢迎对大数据开源项目有兴趣的同学加入交流最新技术信息,开源项目库地址:https://github.com/DTStack
大数据开源项目,一站式全自动化全生命周期运维管家ChengYing(承影)走向何方?的更多相关文章
- 优秀大数据GitHub项目一览
http://blog.csdn.net/yaoxtao/article/details/50540485 优秀大数据GitHub项目一览 VMware CEO Pat Gelsinger曾说: 数据 ...
- [Hadoop 周边] Hadoop和大数据:60款顶级大数据开源工具(2015-10-27)【转】
说到处理大数据的工具,普通的开源解决方案(尤其是Apache Hadoop)堪称中流砥柱.弗雷斯特调研公司的分析师Mike Gualtieri最近预测,在接下来几年,“100%的大公司”会采用Hado ...
- Hadoop和大数据:60款顶级大数据开源工具
一.Hadoop相关工具 1. Hadoop Apache的Hadoop项目已几乎与大数据划上了等号.它不断壮大起来,已成为一个完整的生态系统,众多开源工具面向高度扩展的分布式计算. 支持的操作系统: ...
- 【转载】Hadoop和大数据:60款顶级大数据开源工具
一.Hadoop相关工具 1. Hadoop Apache的Hadoop项目已几乎与大数据划上了等号.它不断壮大起来,已成为一个完整的生态系统,众多开源工具面向高度扩展的分布式计算. 支持的操作系统: ...
- 大数据开源平台CDH 集群(CM6.3.1 + CDH 6.3.2)的部署
一,概述 我依照博文:https://www.cnblogs.com/liugp/p/16286645.html ,进行了CDH集群的部署.总体来说,基本比较顺利. 在部署过程中,发生了一些小问题.本 ...
- oschina大数据开源软件
Hadoop 图形化用户界面 Hue 大数据可视化工具 Nanocubes 企业大数据平台 RedHadoop 大数据查询引擎 PrestoDB Hadoop集群监控工具 HTools 安全大数据分析 ...
- 10大Python开源项目推荐(Github平均star2135)
翻译 | suisui 来源 | 人工智能头条(AI_Thinker) 继续假日充电系列~本文是 Mybridge 挑选的 10 个 Python 开源项目,Github 平均star 2135,希望 ...
- 大数据小项目之电视收视率企业项目09--hive环境搭建
Hive是一个数据仓库基础工具在Hadoop中用来处理结构化数据.它架构在Hadoop之上,总归为大数据,并使得查询和分析方便.并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务 ...
- 大数据小项目之电视收视率企业项目08--》MapReduce编写之Wordcount
编程规范 (1)用户编写的程序分成三个部分:Mapper,Reducer,Driver(提交运行mr程序的客户端) (2)Mapper的输入数据是KV对的形式(KV的类型可自定义) (3)Mapper ...
- Android二维码开源项目zxing用例简化和生成二维码、条形码
上一篇讲到:Android二维码开源项目zxing编译,编译出来后有一个自带的測试程序:CaptureActivity比較复杂,我仅仅要是把一些不用的东西去掉,用看起来更方便,二维码和条形码的流行性自 ...
随机推荐
- VulnHub2018_DeRPnStiNK靶机渗透练习
据说该靶机有四个flag 扫描 扫描附近主机arp-scan -l 扫主目录 扫端口 nmap -sS -sV -n -T4 -p- 192.168.xx.xx 结果如下 Starting Nmap ...
- 【Python】文件批量重命名
需求: 经常有很多相似的文件需要重命名,如果一个一个来太麻烦了,正好会Python,所以用Python写了个脚本,把符合要求的文件的文件名修改为新的. 代码: # coding:utf-8 # @Ti ...
- study PostgreSQL【2-FireDAC连接PostgreSQL】
就这么个简单问题,一下午时间.想想就憋屈. 那么牛逼哄哄FireDAC居然连接PostgreSQL出问题了.帮助中说的啥意思,咱也不明白.网上一通也是云里雾里. 上干货,具体点: TFDConnect ...
- 2024 (ICPC) Jiangxi Provincial Contest -- Official Contest
L. Campus 1.首先考虑时间复杂度,因为最多只会有2*k的时间点,所以我们采取的策略是,对这每个时刻,判断有多少扇门是开的,并且考虑这些门到其他点的最短路之和. 2.输入完数据以后,使用dij ...
- python aiohttp异步协程实现同时执行多条请求
我们在对多个链接进行处理的时候,往往是先请求一个链接获得数据后,再请求第二个. 中间在等待返回数据时候,存在一个空闲时间,脚本啥都没干. 用aiohttp异步协程的方法,创建多条任务发送请求(理论上不 ...
- ThinkPHP3.2无法加载控制器
无法加载控制器:Admin 错误位置 FILE: D:\phpStudy\WWW\wisdom\ThinkPHP\Library\Think\App.class.php LINE: 101 在将Thi ...
- Java编程--观察者(Observer)设计模式
观察者设计模式 观察者设计模式是一种行为设计模式,允许对象在其状态改变时通知其他依赖对象.它创建了一种发布者(Subject)和订阅者(Observer)之间的依赖关系.这种模式经常用于实现事件处理系 ...
- Excel百万数据高性能导出方案!
前言 在我们的日常工作中,经常会有Excel数据导出的需求. 但可能会遇到性能和内存的问题. 今天这篇文章跟大家一起聊聊Excel高性能导出的方案,希望对你会有所帮助. 1 传统方案的问题 很多小伙伴 ...
- 探秘Transformer系列之(32)--- Lookahead Decoding
探秘Transformer系列之(32)--- Lookahead Decoding 目录 探秘Transformer系列之(32)--- Lookahead Decoding 0x00 概述 0x0 ...
- 实现高质量视频通话的javascript技巧与方法
@charset "UTF-8"; .markdown-body { line-height: 1.75; font-weight: 400; font-size: 15px; o ...