数据湖选型指南|Hudi vs Iceberg 数据更新能力深度对比
数据湖作为新一代大数据基础设施,近年来持续火热,许多前线的同学都在讨论数据湖应该怎么建,许多企业也都在构建或者计划构建自己的数据湖。基于此,自然引发了许多关于数据湖选型的讨论和探究。但是经过搜索之后我们发现,网上现存的很多内容都是基于较早之前的开源信息做出的结论,在企业调研初期容易造成不准确的印象和理解。
因此带着这样的问题,我们计划推出数据湖选型系列文章,基于最新的开源信息,从升级数据湖架构的几个重要纬度帮助大家进行深度对比。希望能抛砖引玉,引起大家一些思考和共鸣,欢迎同学们一起探讨。
实践过程中我们发现,在计划升级数据湖架构的客户中,支持数据的事务更新通常是大家的第一基础诉求。因此,该系列的第一篇内容我们将从需求的诞生背景,以及不同数据湖架构在数据事务上的能力对比,两个方面帮助大家在数据湖选型之路上做出更好的决定。
需求背景
在传统的 Hive 离线数仓架构下,数据更新的成本是非常大的,更新一条数据需要重写整个分区甚至整张表。因此在真实业务场景中,出于开发成本、数据风险等方面的考虑,大家都不会在 Hive 数仓中更新数据。
不过随着 Hive 3.0 的推出,Hive 表在事务能力上也向前迈了一大步,官方在推出 3.0 时也重点宣传了它的事务能力。不过在实际应用中仍然存在非常大的限制,真实投产的用户寥寥无几。(仅支持ORC事务内表,这意味着像Spark这类计算引擎,无法直接在Hive事务表上进行ETL/ELT开发,包括像CDH、袋鼠云公司都在Spark兼容上做过投入,但是效果不佳,远达不到生产级的应用预期)
因此,在数据湖选型过程中,高效的并发更新能力就显得尤为重要。它能够改变我们在 Hive 数仓中遇到的数据更新成本高的问题,支持对海量的离线数据做更新删除。
数据更新实现的选型
目前市面上核心的数据湖开源产品大致有这么几个:Apache Iceberg、Apache Hudi和 Delta。
本文将为大家重点介绍 Hudi 和 Iceberg 在数据更新实现方面的表现。
Hudi 的数据更新实现
Hudi(Hadoop Update Delete Incremental),从这个名称可以看出,它的诞生就是为了解决 Hadoop 体系内数据更新和增量查询的问题。要想弄明白 Hudi 是如何在 HDFS 这类文件系统上实现快速 update 操作的,我们需要先了解 Hudi 的几个特性:
· Hudi 表的文件组织形式:在每个分区(Partition)内,数据文件被切分组织成一个个文件组(FileGroup),每个文件组都已 FileID 进行唯一标识。
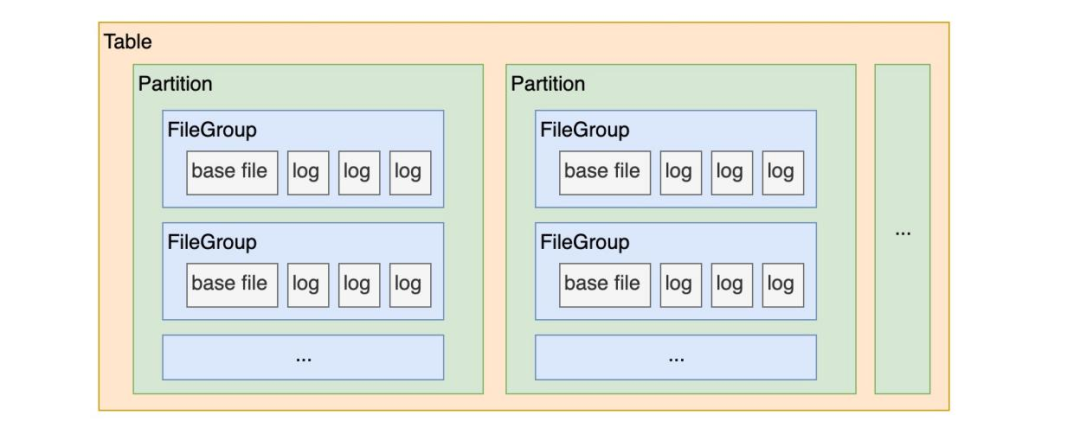
· Hudi 表是有主键设计的,每条数据都已主键进行唯一标识。
· Hudi 表是有索引设计的。
结合上面的三个特性可以得出,Hudi 表的索引可以帮助我们快速地定位到某一条数据存在于某个分区的某个文件组中,然后对其进行 Update 操作,即重写这部分文件组。
Iceberg 的数据更新实现
Iceberg 的官方定位是「面向海量数据分析场景的高效存储格式」。所以它没有像 Hudi 一样模拟业务数据库的设计模式(主键+索引)来实现数据更新,而是设计了更强大的文件组织形式来实现数据的 update 操作,详见下图:
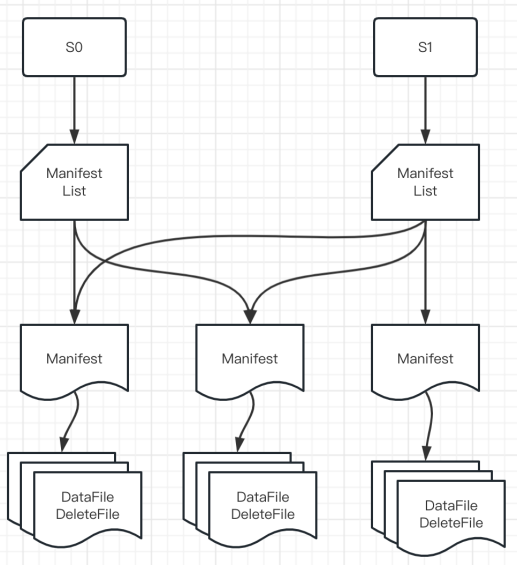
• Snapshot:用户的每次 commit 会产生一个新的 snapshot
• Manifest List:维护当前 snapshot 中所有的 manifest
• Manifest:维护当前 Manifest 下所有的 data files 和 delete files
• Data File:存储数据的文件
• Delete File:存储「删除的数据」的文件
在上面的文件组织基础上,我们可以看出,Iceberg 实现 update 的大致逻辑是:
· 先将要删除的数据写入 Delete File;
· 然后将「Data File」 JOIN 「Delete File」进行数据比对,实现数据更新。
当然,实现这两步有很多技术细节:比如利用 Sequence Number 保障事务顺序;Delete File 根据删除时的文件状态判断是走 position delete 还是 equality delete 逻辑;引入 equality_ids 概念模拟主键等。
如何选择
单纯从数据更新能力这个角度来看:
· Hudi 凭借文件组+索引+主键的设计模式,能够有效减少数据文件的冗余更新,提高数据更新效率。
· Iceberg 通过文件组织设计也能达到数据更新效果,但是每一次的 commit 都会产生新的文件,如果写入/更新频繁,小文件问题会比较严重。(虽然官方也配套提供了小文件治理能力,但是这部分的资源消耗、治理难度相对 Hudi 来说会比较大)
如何实践应用
当我们确定了数据湖选型后,如何在生产环境中进行实践应用就成为了下一个问题。
这里就需要提前了解表类型这个概念,同一种数据湖表格式也有不同的类型区别,分别适用不同的场景:
• COW(Copy On Write):写时复制表。在数据写入/更新时,立即重写原有数据文件,生成一份新的数据文件。
• MOR(Merge On Read):读时合并表。在数据写入/更新时,不修改原有文件,写入新的日志/文件,在之后数据被读取到的时候,重写数据文件。
基于这两种表类型的特性差异,我们给出如下建议:
· 如果你的湖表写入/更新不频繁,主要用于支撑数据查询/分析场景,那建议使用 COW 表。
· 如果你的湖表写入/更新频繁(甚至是用于实时开发场景的写入),那建议使用 MOR 表。
总结
没有最好的技术架构,只有最适合当前业务的技术架构。
关于数据湖的选型当然也不能简单从数据更新能力这一单一纬度做出判断。后续我们将继续推出不同数据湖架构在 Schema 管理、查询加速、批流一体等更多纬度的对比内容。欢迎大家和我们一起探讨交流。
同时,袋鼠云也有自己的数据湖仓一体化构建平台 EasyLake,提供面向湖仓一体的数据湖管理分析服务,基于统一的元数据抽象构建一致性的数据访问,提供海量数据的存储管理和实时分析处理能力。
《数据治理行业实践白皮书》下载地址:https://fs80.cn/380a4b
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack
数据湖选型指南|Hudi vs Iceberg 数据更新能力深度对比的更多相关文章
- 均有商业公司支持!2023再看数据湖 hudi iceberg delta2 社区发展现状!
开源数据湖三剑客 Apache hudi.Apache iceberg .Databricks delta 近年来大动作不断. 2021年8月,Apache Iceberg 的创始人 Ryan Blu ...
- 深度对比Apache CarbonData、Hudi和Open Delta三大开源数据湖方案
摘要:今天我们就来解构数据湖的核心需求,同时深度对比Apache CarbonData.Hudi和Open Delta三大解决方案,帮助用户更好地针对自身场景来做数据湖方案选型. 背景 我们已经看到, ...
- 基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战 传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化.虽然能 ...
- Robinhood基于Apache Hudi的下一代数据湖实践
1. 摘要 Robinhood 的使命是使所有人的金融民主化. Robinhood 内部不同级别的持续数据分析和数据驱动决策是实现这一使命的基础. 我们有各种数据源--OLTP 数据库.事件流和各种第 ...
- 构建数据湖上低延迟数据 Pipeline 的实践
T 摘要 · 云原生与数据湖是当今大数据领域最热的 2 个话题,本文着重从为什么传统数仓 无法满足业务需求? 为何需要建设数据湖?数据湖整体技术架构.Apache Hudi 存储模式与视图.如何解决冷 ...
- 重磅!flink-table-store 将作为独立数据湖项目重新加入 Apache
数据湖是大数据近年来的网红项目,大家熟知的开源数据湖三剑客 Apache hudi.Apache iceberg .Databricks delta 近年来野蛮生长,目前各自背后也都有商业公司支持,投 ...
- 数据湖框架选型很纠结?一文了解Apache Hudi核心优势
英文原文:https://hudi.apache.org/blog/hudi-indexing-mechanisms/ Apache Hudi使用索引来定位更删操作所在的文件组.对于Copy-On-W ...
- 使用Apache Hudi构建大规模、事务性数据湖
一个近期由Hudi PMC & Uber Senior Engineering Manager Nishith Agarwal分享的Talk 关于Nishith Agarwal更详细的介绍,主 ...
- 使用Apache Hudi + Amazon S3 + Amazon EMR + AWS DMS构建数据湖
1. 引入 数据湖使组织能够在更短的时间内利用多个源的数据,而不同角色用户可以以不同的方式协作和分析数据,从而实现更好.更快的决策.Amazon Simple Storage Service(amaz ...
- 使用 Iceberg on Kubernetes 打造新一代云原生数据湖
背景 大数据发展至今,按照 Google 2003年发布的<The Google File System>第一篇论文算起,已走过17个年头.可惜的是 Google 当时并没有开源其技术,& ...
随机推荐
- Win32控制台获取可执行程序的快捷方式的目标位置、起始位置、快捷键、备注等
Win32控制台获取可执行程序的快捷方式的目标位置.起始位置.快捷键.备注等,示例如下图: #include <iostream> #include <atlstr.h> #i ...
- docker-compose up -d 运行容器秒自动停止解决方案
正常的我们运行Docker-Compose的服务 docker-compose -f docker-compose.yml up -d mysql-setup 执行Docker ps 查看存活的容器 ...
- Linux下对LVM逻辑卷分区大小调整 [针对xfs和ext4文件系统]
当我们在安装系统的时候,由于没有合理分配分区空间,在后续维护过程中,发现有些分区空间不够使用,而有的分区空间却有很多剩余空间.如果这些分区在装系统的时候使用了lvm(前提是这些分区要是lvm逻辑卷分区 ...
- Momentum Contrast for Unsupervised Visual Representation Learning论文精读
目录 Birth of MoCo Supervised Learning Contrastive Learning MoCo Dictionary Limits of the early learni ...
- Spring底层AOP代码实现
一. AOP功能测试 ①. pom.xml 依赖导入 ②. 目标类 ③. 切面类 ④. 配置类 ⑤. 测试类 二. AOP原理-@EnableAspectJAutoProxy AOP原理:[看给容器中 ...
- 华为od机考2025A卷真题 -查找接口成功率最优时间段
题目描述与示例 题目描述 服务之间交换的接口成功率作为服务调用关键质量特性,某个时间段内的接口失败率使用一个数组表示,数组中每个元素都是单位时间内失败率数值,数组中的数值为 0~100 的整数,给定一 ...
- Go工程选择开源分库分表中间件可用性测试
近期在寻找Go工程可以用的开源分库分表中间件,找了3个:ShardingSphere-Proxy,Kingshard,Gaea,下面给出测试过程和对比结果 ShardingSphere-Proxy h ...
- Java编程之面向对象
一.面向对象 1.定义 (1)类:描述的是具有共性的一类事物 (2)对象:一个个具备了类的特点和功能的个体 (3)面向对象:要完成某件事,首先要先有对象,然后直接调用这个对象的响应功能 2.成员变量: ...
- 前端js需要连接后端c#的wss服务
背景前端js需要连接后端wss服务 前端:js后端:c# - 控制台搭建wss服务器 步骤1 wss需要ssl认证,所以需要个证书,随便找一台linux的服务器(windows的话,自己安装下open ...
- GUI development with Rust and GTK4 阅读笔记
简记 这是我第二次从头开始阅读,有第一次的印象要容易不少. 如果只关心具体的做法,而不思考为什么这样做,以及整体的框架,阅读的过程将会举步维艰. 简略记录 gtk-rs 的书中提到的点.对同一个问题书 ...