数据湖框架选型很纠结?一文了解Apache Hudi核心优势

英文原文:https://hudi.apache.org/blog/hudi-indexing-mechanisms/
Apache Hudi使用索引来定位更删操作所在的文件组。对于Copy-On-Write表,索引能加快更删的操作,因为避免了通过连接整个数据集来决定哪些文件需要重写。对于Merge-On-Read表,这个设计,对于任意给定的基文件,能限定要与其合并的记录数量。具体地,一个给定的基文件只需要和其所包含的记录的更新合并。相比之下,没有索引的设计(比如Apache Hive ACID),可能会导致需要把所有基文件与所有更删操作合并。
从高角度看,索引把一个记录的键加一个可选的分区路径映射到存储上的文件组ID(更多细节参考这里)。在写入过程中,我们查找这个映射然后把更删操作导向基文件附带的日志文件(MOR表),或者导向最新的需要被合并的基文件(COW表)。索引也使得Hudi可以根据记录键来规定一些唯一性的限制。
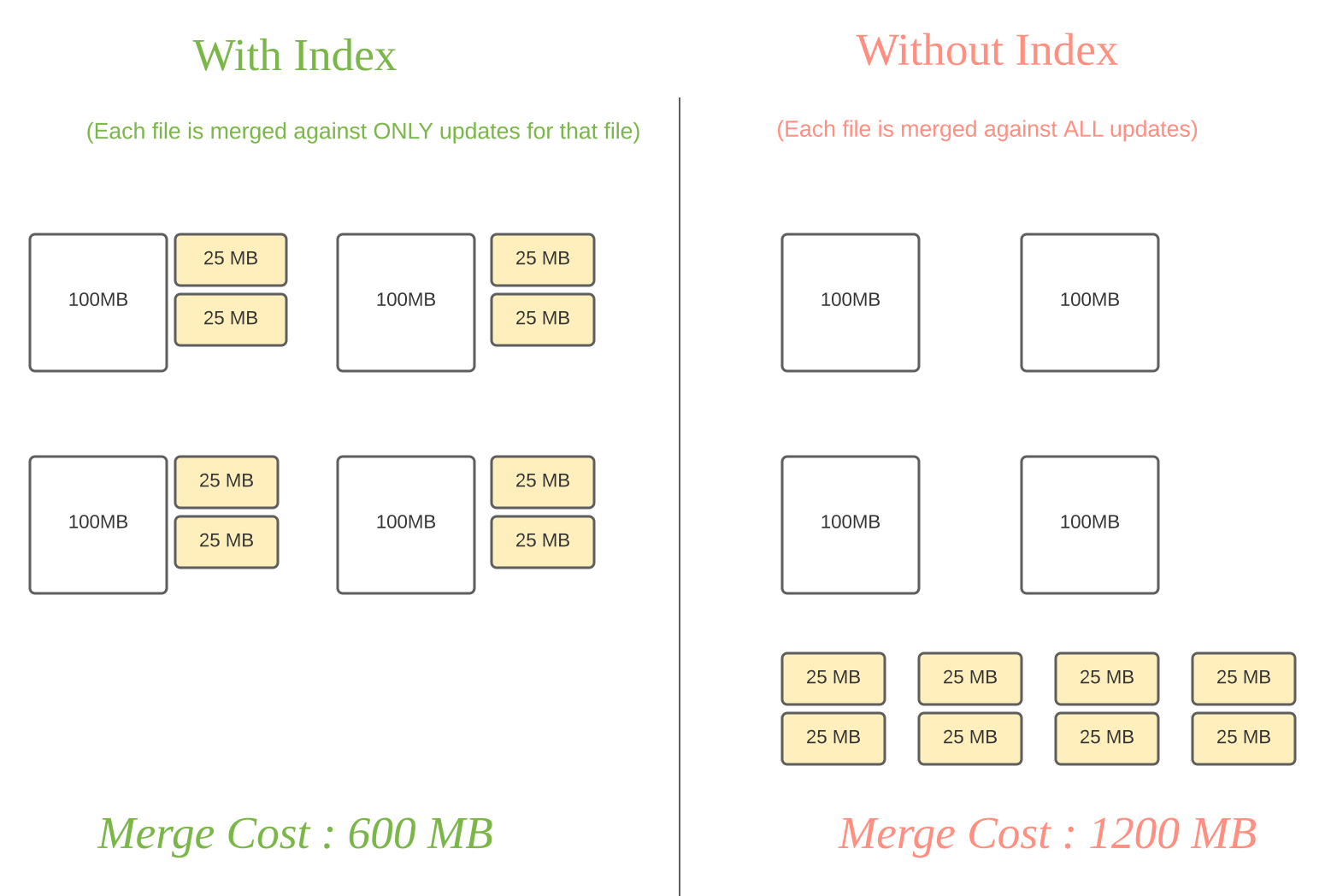
记录更新(黄色块)和基文件(白色块)合并消耗的对比
目前Hudi已经支持了几种不同的索引机制,并且在工具库中不断地完善和增加更多机制,在本文余下的篇幅中将根据我们的经验介绍几种不同作业场景下索引机制的选择。我们也会穿插一些对已有限制、即将开展的工作、以及优化和权衡方面的评论。
Hudi的索引类型
目前Hudi支持以下几种索引类型。
布隆索引(默认):使用以记录的键生成的布隆过滤器,也可以用记录键对可能对应的文件进行剪枝操作。简单索引:对更删的记录和存储上的表里提取的键进行轻量级的连接。HBase索引:使用外部的Apache HBase表来管理索引映射。
写入器可以通过hoodie.index.type来设置以上的类型。此外,自定义的索引实现可以通过hoodie.index.class来配置。对Apache Spark写入器需提供SparkHoodieIndex的子类。
另一个需要了解的关键点是区分全局索引和非全局索引。布隆索引和简单索引都有一个全局选项,分别是hoodie.index.type=GLOBAL_BLOOM和hoodie.index.type=GLOBAL_SIMPLE。HBase索引本质上就是全局索引。
- 全局索引:全局索引在全表的所有分区范围下强制要求键的唯一性,也就是确保对给定的键有且只有一个对应的记录。全局索引提供了更强的保证,而更删的消耗随着表的大小增加而增加(O(表的大小)),但仍可能对小表适用。
- 非全局索引:这个默认的索引实现只在一个分区里强制要求了这样的限制。由此可见,非全局索引依靠写入器为同一个记录的更删提供一致的分区路径,但由此同时大幅提高了效率,因为索引查询复杂度成了O(更删的记录数量)且可以很好地应对写入量的扩展。
由于数据可能有着不同的体量、速度和读取规律,不同索引会适用于不同的作业场景。接下来让我们分析几个不同的场景来讨论如何选择适合的Hudi索引。
作业场景:对事实表的延迟更新
许多公司会在NoSQL数据存储中存放大量的交易数据。例如共享出行的行程表、股票买卖记录的表、和电商的订单表。这些表通常一直在增长,且大部分的更新随机发生在较新的记录上,而对旧记录有着长尾分布型的更新。这通常是源于交易关闭或者数据更正的延迟性。换句话说,大部分更新会发生在最新的几个分区上而小部分会在旧的分区。

典型的事实表的更新样式。
对于这样的作业模式,布隆索引就能表现地很好,因为查询索引可以靠设置得当的布隆过滤器来剪枝很多数据文件。另外,如果生成的键可以以某种顺序排列,参与比较的文件数会进一步通过范围剪枝而减少。Hudi用所有文件的键域来构造区间树,这样能来高效地依据输入的更删记录的键域来排除不匹配的文件。
为了高效地把记录键和布隆过滤器进行比对,即尽量减少过滤器的读取和均衡执行器间的工作量,Hudi缓存了输入记录并使用了自定义分区器和统计规律来解决数据的偏斜。有时,如果布隆过滤器的伪正率过高,查询会增加数据的打乱操作。Hudi支持动态布隆过滤器(设置hoodie.bloom.index.filter.type=DYNAMIC_V0)。它可以根据文件里存放的记录数量来调整大小从而达到设定的伪正率。
在不久的将来,我们计划引入一个更快的布隆索引机制。该机制会在Hudi内部的元数据表中跟踪记录布隆过滤器和取值范围从而进行快速的点查询。这可以避免因从基文件中读取布隆过滤器和取值范围而导致的查询的局限性。(总体设计请参考RFC-15)
作业场景:对事件表的去重
事件流无处不在。从Apache Kafka或其他类似的消息总线发出的事件数通常是事实表大小的10-100倍。事件通常把时间(到达时间、处理时间)作为首类处理对象,比如物联网的事件流、点击流数据、广告曝光数等等。由于这些大部分都是仅追加的数据,插入和更新只存在于最新的几个分区中。由于重复事件可能发生在整个数据管道的任一节点,在存放到数据湖前去重是一个常见的需求。
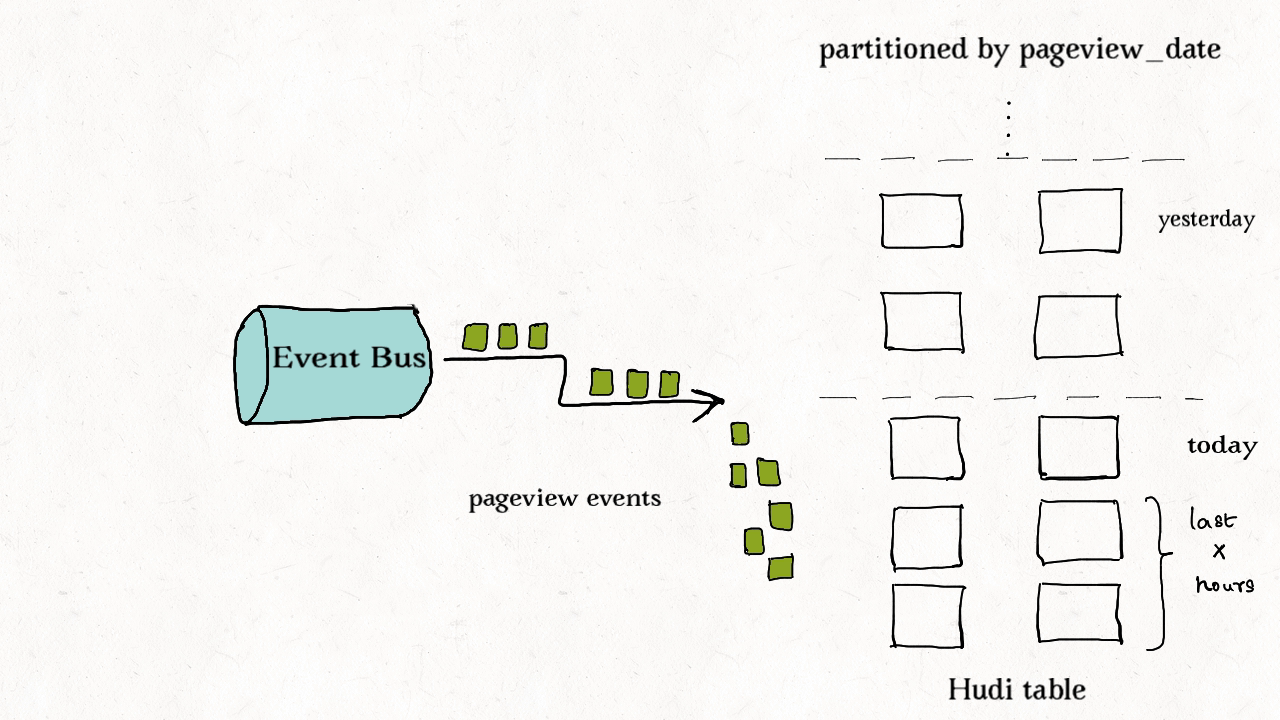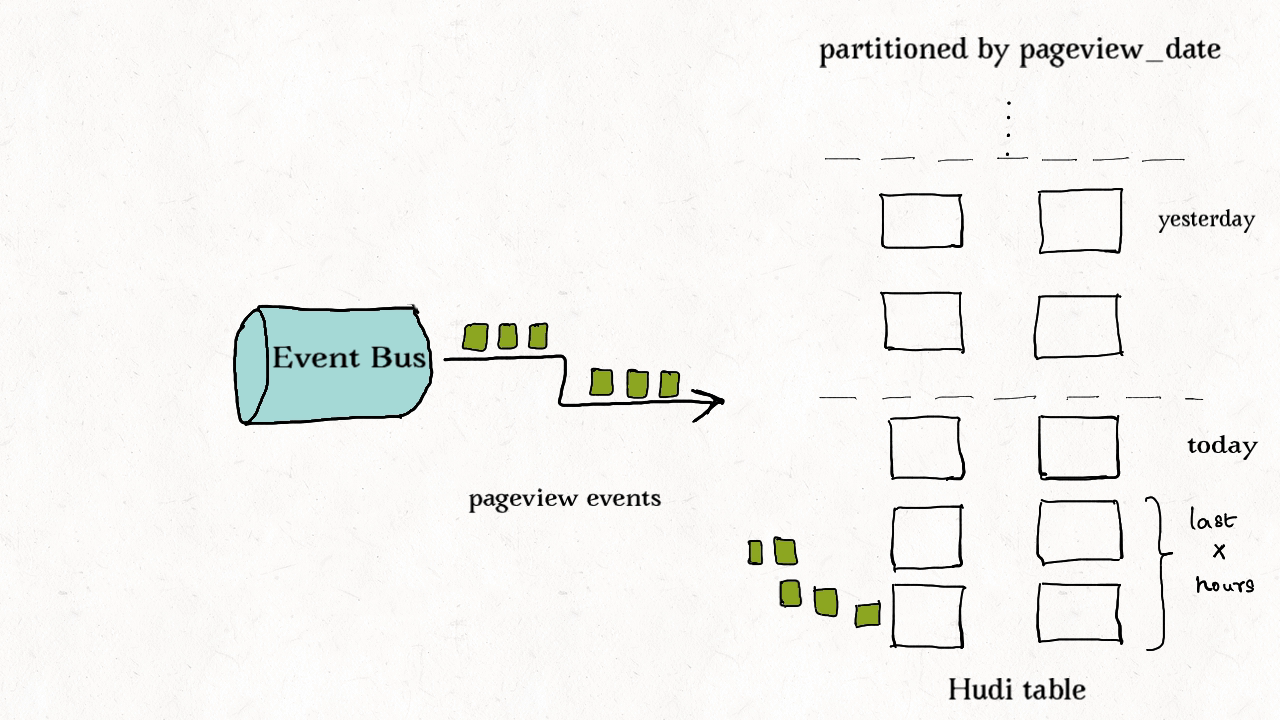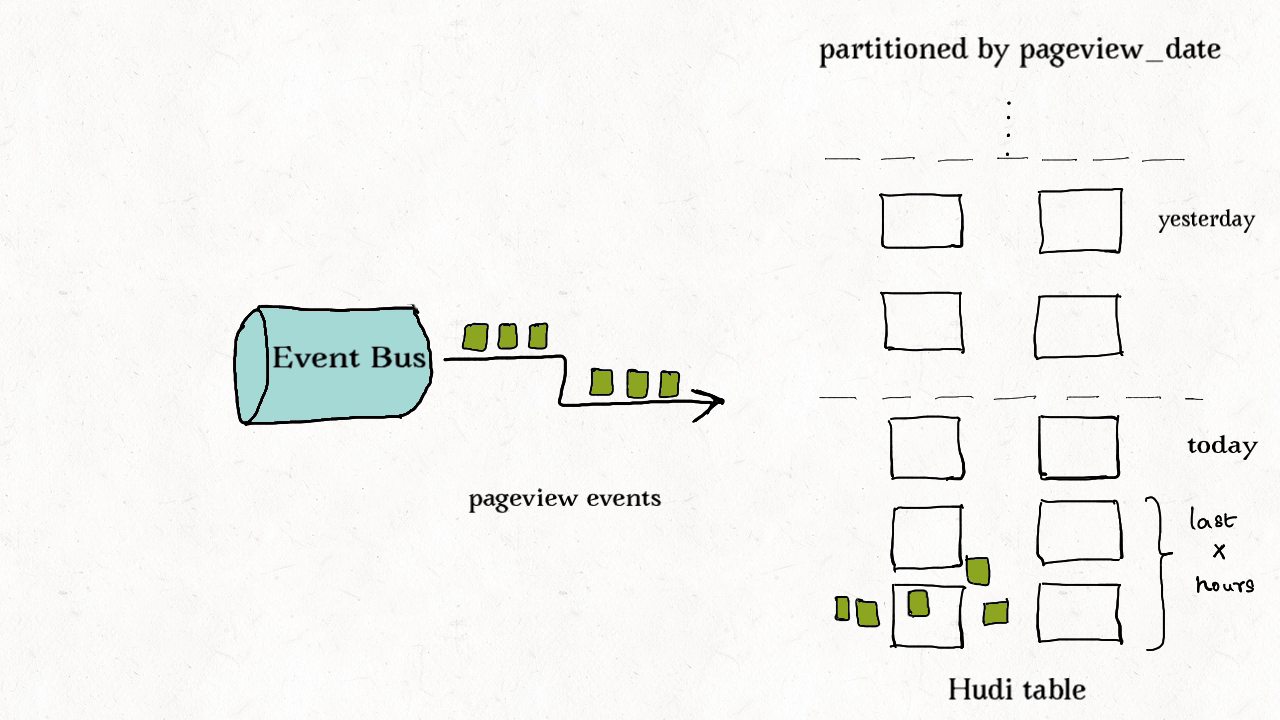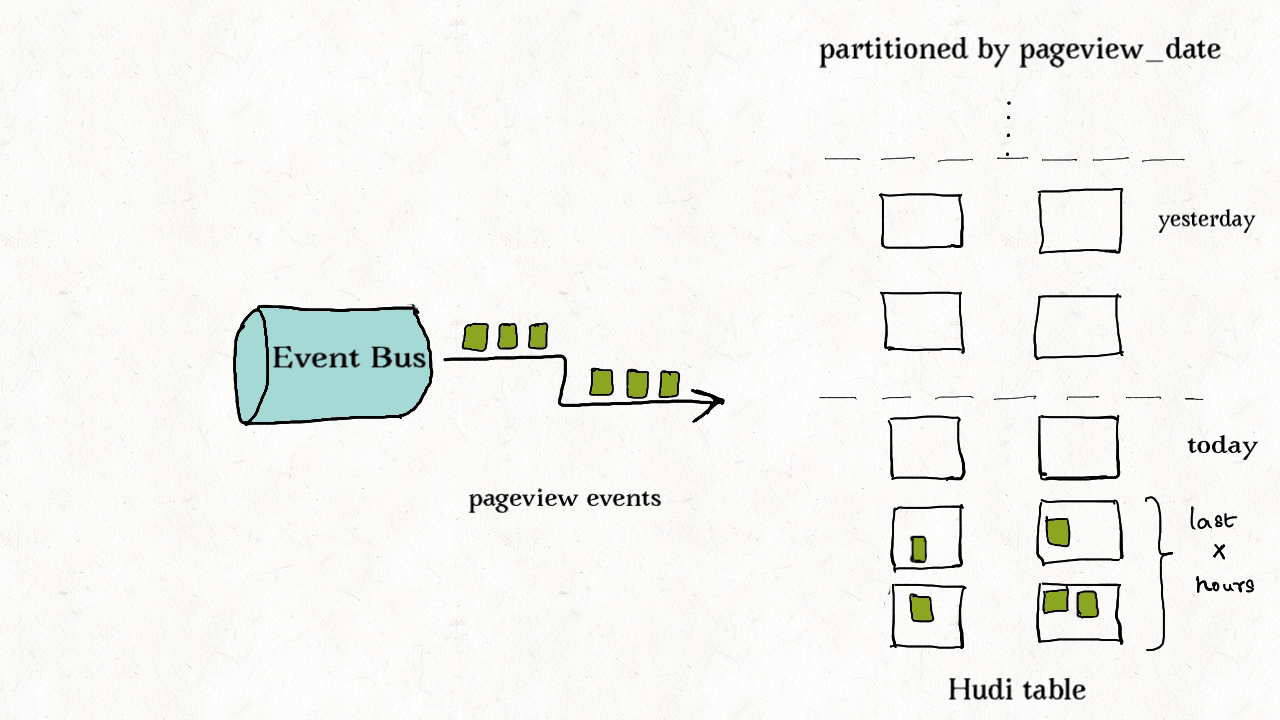
上图演示了事件表的更新分布情况。
总的来说,低消耗去重一个非常挑战的工作。尽管甚至可以用一个键值存储来实现去重(即HBase索引),但索引存储的消耗会随着事件数增长而线性增长以至于变得不可行。事实上,有范围剪枝功能的布隆索引是最佳的解决方案。我们可以利用作为首类处理对象的时间来构造由事件时间戳和事件id(event_ts+event_id)组成的键,这样插入的记录就有了单调增长的键。这会在最新的几个分区里大幅提高剪枝文件的效益。
作业场景:对维度表的随机更删
这种类型的表通常包含高纬度的数据和数据链接,比如用户资料、商家信息等。这些都是高保真度的表。它们的更新量通常很小但所接触的分区和数据文件会很多,范围涉及从旧到新的整个数据集。有时因为没有很好的分区条件,这些表也会不分区。
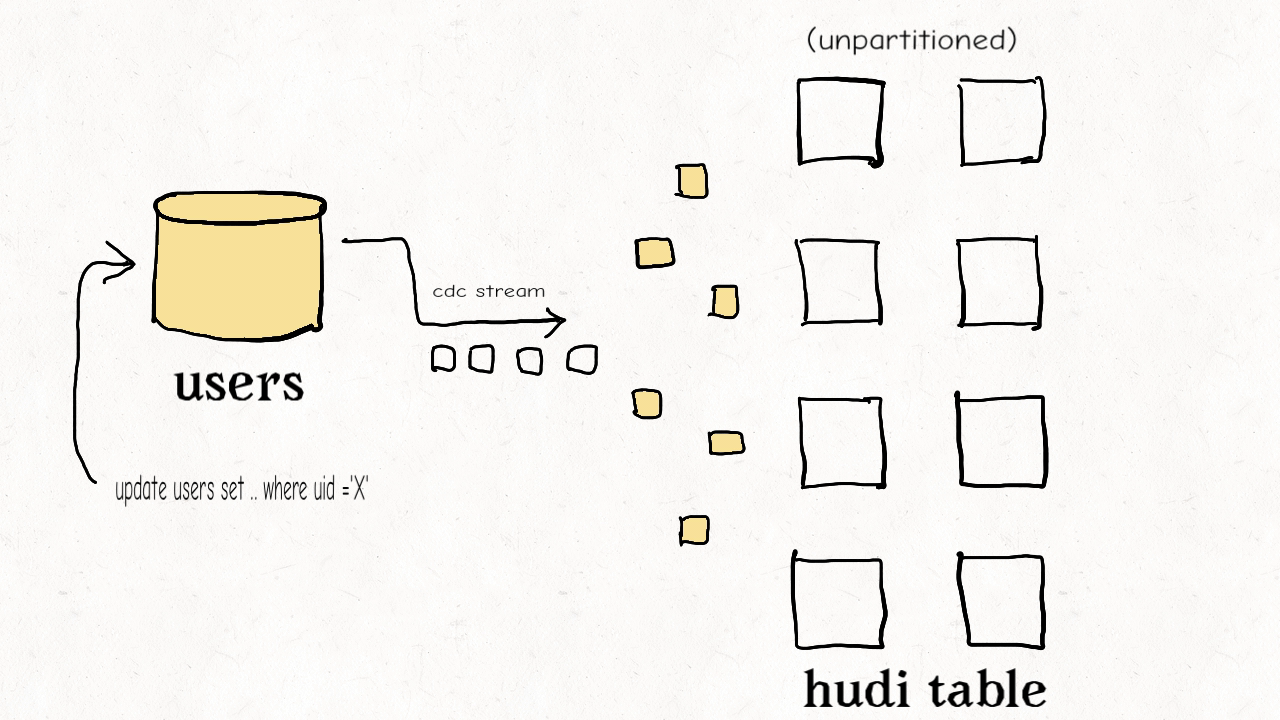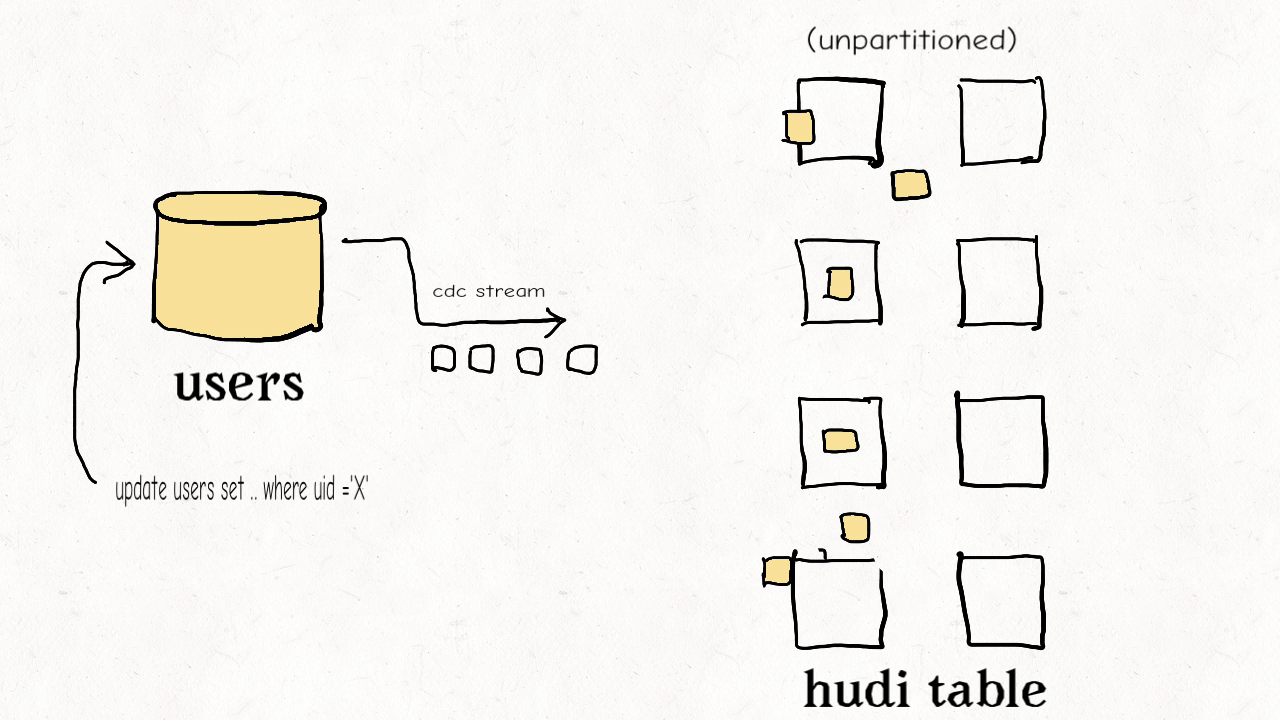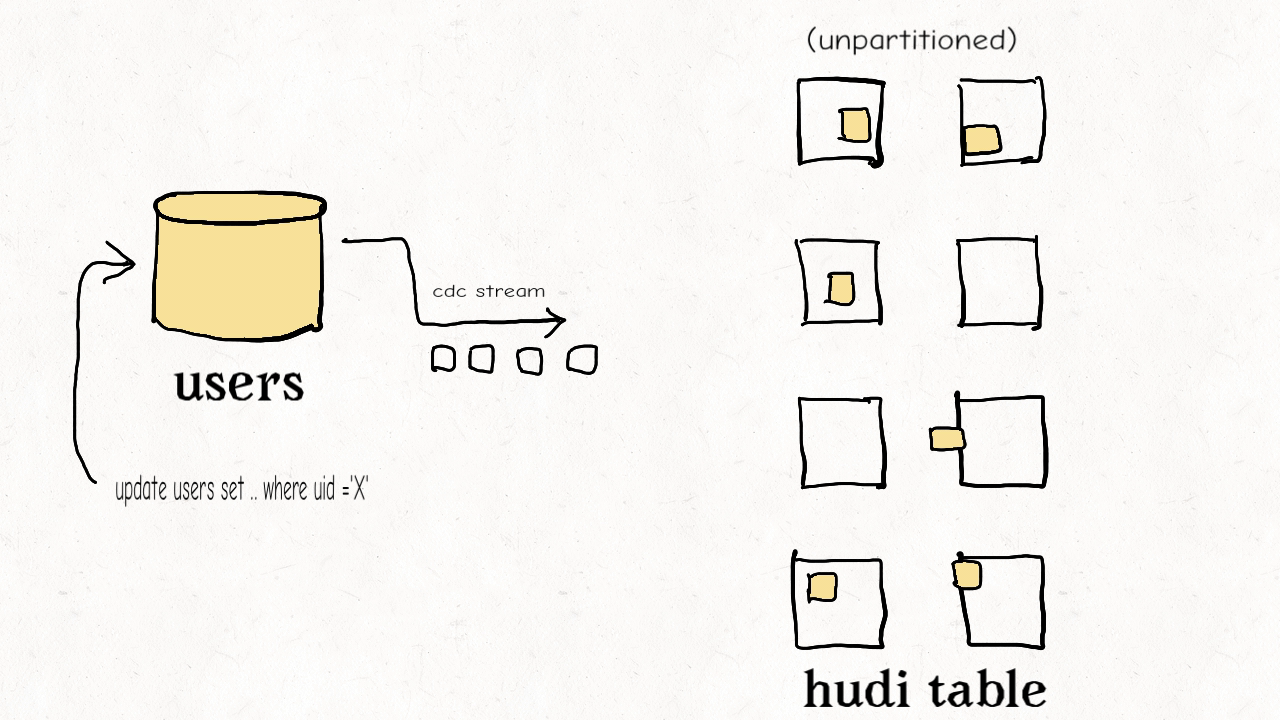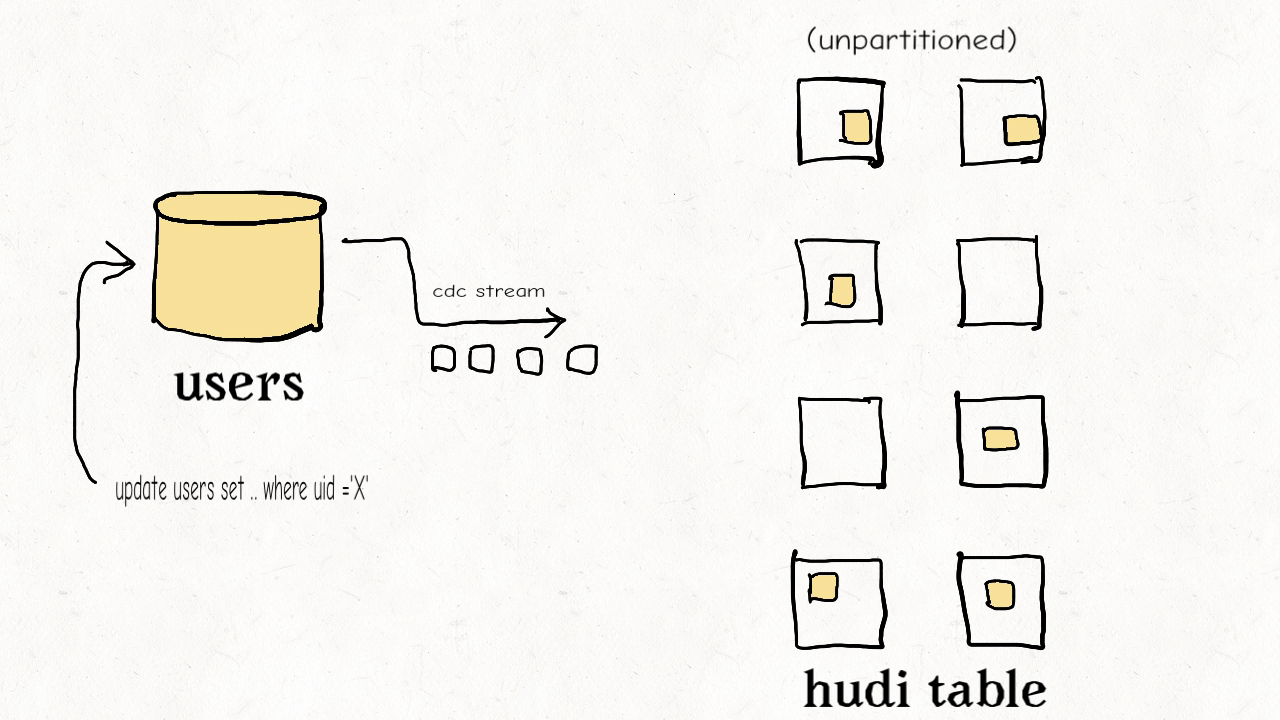
上图演示了维度表的更新分布情况。
正如之前提到的,如果范围比较不能剪枝许多文件的话,那么布隆索引并不能带来很好的效益。在这样一个随机写入的作业场景下,更新操作通常会触及表里大多数文件从而导致布隆过滤器依据输入的更新对所有文件标明真正(true positive)。最终会导致,即使采用了范围比较,也还是检查了所有文件。使用简单索引对此场景更合适,因为它不采用提前的剪枝操作,而是直接和所有文件的所需字段连接。如果额外的运维成本可以接受的话,也可以采用HBase索引,其对这些表能提供更加优越的查询效率。
当使用全局索引时,用户也可以考虑通过设置hoodie.bloom.index.update.partition.path=true或者hoodie.simple.index.update.partition.path=true(Global Bloom)hoodie.hbase.index.update.partition.path=true或者hoodie.hbase.index.update.partition.path=true 或者来处理分区路径需要更新的情况;例如对于以所在城市分区的用户表,会有用户迁至另一座城市的情况。这些表也非常适合采用Merge-On-Read表型。
将来我们计划在Hudi内实现记录层的索引机制,以此提高索引查询效率,同时也将省去维护额外系统(比如HBase)的开销。
总结
若没有索引功能,Hudi就不可能在超大扩展规模上实现更删操作。希望这篇文章为目前的索引机制提供了足够的背景知识和对不同权衡取舍的解释。
以下是一些颇具意义的相关工作:
- 基于Apache Flink并建立在RocksDB状态存储上的索引机制将带来真正意义上的数据湖流式插入更新。
- 全新的元数据索引将基于Hudi元数据全面翻新现有的布隆索引机制。
- 记录层的索引实现,用另一个Hudi表作为二级索引。
在接下来的开发中,项目组会对这个领域保持积极的投入。我们始终期待更多贡献者的加入以及推进路线图中的项目。如果有意参与,欢迎与我们的社区联系。
数据湖框架选型很纠结?一文了解Apache Hudi核心优势的更多相关文章
- Robinhood基于Apache Hudi的下一代数据湖实践
1. 摘要 Robinhood 的使命是使所有人的金融民主化. Robinhood 内部不同级别的持续数据分析和数据驱动决策是实现这一使命的基础. 我们有各种数据源--OLTP 数据库.事件流和各种第 ...
- 基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战 传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化.虽然能 ...
- 构建数据湖上低延迟数据 Pipeline 的实践
T 摘要 · 云原生与数据湖是当今大数据领域最热的 2 个话题,本文着重从为什么传统数仓 无法满足业务需求? 为何需要建设数据湖?数据湖整体技术架构.Apache Hudi 存储模式与视图.如何解决冷 ...
- 划重点!AWS的湖仓一体使用哪种数据湖格式进行衔接?
此前Apache Hudi社区一直有小伙伴询问能否使用Amazon Redshift查询Hudi表,现在它终于来了. 现在您可以使用Amazon Redshift查询Amazon S3 数据湖中Apa ...
- 深度对比Apache CarbonData、Hudi和Open Delta三大开源数据湖方案
摘要:今天我们就来解构数据湖的核心需求,同时深度对比Apache CarbonData.Hudi和Open Delta三大解决方案,帮助用户更好地针对自身场景来做数据湖方案选型. 背景 我们已经看到, ...
- Apache Hudi表自动同步至阿里云数据湖分析DLA
1. 引入 Hudi 0.6.0版本之前只支持将Hudi表同步到Hive或者兼容Hive的MetaStore中,对于云上其他使用与Hive不同SQL语法MetaStore则无法支持,为解决这个问题,近 ...
- Apache Hudi助力nClouds加速数据交付
1. 概述 在nClouds上,当客户的业务决策取决于对近实时数据的访问时,客户通常会向我们寻求有关数据和分析平台的解决方案.但随着每天创建和收集的数据量都在增加,这使得使用传统技术进行数据分析成为一 ...
- 一个类GraphQL的ORM数据访问框架发布
Zongsoft.Data 发布公告 很高兴我们的 ORM 数据访问框架(Zongsoft.Data)在历经两个 SaaS 产品的应用之后,今天正式宣布对外推广! 这是一个类 GraphQL 风格的 ...
- 使用Apache Spark和Apache Hudi构建分析数据湖
1. 引入 大多数现代数据湖都是基于某种分布式文件系统(DFS),如HDFS或基于云的存储,如AWS S3构建的.遵循的基本原则之一是文件的"一次写入多次读取"访问模型.这对于处理 ...
随机推荐
- mysql索引原理以及优化
一.常见查找算法: 1.顺序查找: 最基础的查找方法,对比每一个元素进行查找.在数据量很大的时候效率相当的慢. 数据结构:有序或者无需的队列 时间复杂度:O(n) 2.二分查找: 二分查找首先要求数组 ...
- Jdk源码-集合类主要原理和解析
写在前面 熟悉Jdk原理的重要性不言而喻,作为Java开发者或者面试者,了解其实现原理也显得更为装逼,在Java读书计划我写到了,它是面试中最基础的一部分,所以单独拿出来做个总结,为了更好滴理解和学习 ...
- JDK8日期类入门
关于jdk8的时间类的用法,网上有很多教程教你如何用,比如: System.out.println(LocalDateTime.now()); 可以获取当前的时间, 2020-12-06T18:02: ...
- pandas 标签映射成数值的几种方法
1. preprocessing.LabelEncoder() import pandas as pd from sklearn import preprocessing le = preproces ...
- CF1147F Zigzag Game & 稳定婚姻问题学习笔记
CF1147F Zigzag Game 这题太神仙了,不得不记录一下. 我网络流做不动了,DS做不动了,DP做不动了,特别自闭.于是博弈论之神(就是随手切3500博弈的那种) \(\color{bla ...
- 【APIO2020】交换城市(Kruskal重构树)
Description 给定一个 \(n\) 个点,\(m\) 条边的无向连通图,边带权. \(q\) 次询问,每次询问两个点 \(x, y\),求两点间的次小瓶颈路.不存在输出 -1. Hint \ ...
- Array的简单使用(Boost和STL通用)
目录 目录 介绍 使用 Boost和STL的区别 介绍 本来这一次是想简单介绍一下Boost里面的协程库的使用的,但是Boost.Coroutine已经被废弃了,而Boost.Coroutine2目前 ...
- uni-app微信小程序登录授权
微信小程序授权是非常简单和常用的功能,但为了方便,还是在此记录一下要点: 首先是需要用到一个授权按钮来触发获取用户信息授权: 关键在于 open-type 为 getUserInfo , 然后有个@g ...
- 编译opencv4.5.0
1. 环境vs2017或其它版本cmake-3.18设置环境变量OPENCV_TEST_DATA_PATH 值设置为 D:\sdk\vs2017\opencv-4.5.0\opencv_extra-4 ...
- python绘折线图
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt #X轴,Y轴数据 y = [0.3,0.4,2,5 ...