高效实现 LRU 缓存机制:双向链表与哈希表的结合
题目:
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存
int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。
void put(int key, int value) 如果关键字 key 已经存在,则变更其数据值 value ;如果不存在,则向缓存中插入该组 key-value 。如果插入操作导致关键字数量超过 capacity ,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
输入:
["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
输出:
[null, null, null, 1, null, -1, null, -1, 3, 4]
解释:
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
为了实现一个满足 LRU(最近最少使用)缓存约束的数据结构,我们可以使用哈希表(HashMap)和双向链表(Doubly Linked List)的组合。如下图展示:
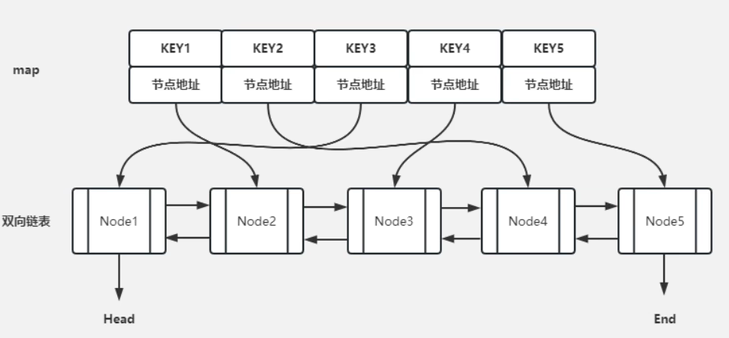
设计思路:
哈希表:
- 用于存储键值对,键是 key,值是一个指向双向链表节点的指针。
- 哈希表的查找操作时间复杂度为 O(1)。
双向链表:
- 用于维护最近使用的顺序,链表的头部是最久未使用的节点,尾部是最近使用的节点。
- 双向链表的插入和删除操作时间复杂度为 O(1)。
操作逻辑:
- get (key):
- 如果键存在,将其对应的节点移动到双向链表的尾部(表示最近使用)。
- 返回对应的值。
- put (key, value):
- 如果键存在,更新其值,并将其移动到双向链表的尾部。
- 如果键不存在,创建新节点并插入到双向链表的尾部。
- 如果缓存容量超出限制,删除双向链表头部的节点(最久未使用的节点)。
那为什么使用双向链表,而不使用其他数据结构呢?
原因如下:
在实现 LRU(最近最少使用)缓存时,双向链表是一种非常合适的数据结构,主要原因在于它能够高效地支持以下两个关键操作:
1. 快速移动节点:
- LRU 缓存需要频繁地将某个节点标记为“最近使用”,即将其移动到链表的尾部。
- 双向链表允许在 O(1) 时间内完成节点的插入和删除操作,因为每个节点都有指向前一个节点和后一个节点的指针。
- 如果使用单向链表,删除操作需要从头开始遍历找到目标节点的前一个节点,时间复杂度为 O(n)。
2. 快速访问最久未使用的节点:
- LRU 缓存需要在缓存满时删除最久未使用的节点。
- 双向链表的头部始终是最久未使用的节点,可以直接通过头节点访问,时间复杂度为 O(1)。
- 如果使用其他数据结构(如数组或单向链表),找到最久未使用的节点需要遍历整个数据结构,时间复杂度为 O(n)。
虽然双向链表本身已经非常高效,但单独使用双向链表无法快速找到某个特定的键值对。因此,通常会结合哈希表来实现 LRU 缓存:
- 哈希表:用于快速查找键值对,时间复杂度为 O(1)。
- 双向链表:用于维护最近使用的顺序,时间复杂度为 O(1)。
通过这种组合,get 和 put 操作都能在 O(1) 时间复杂度内完成,同时满足 LRU 缓存的所有要求。
为什么其他数据结构不够理想?
1. 数组(或动态数组,如 Java 中的 ArrayList)
优点:可以通过索引快速访问任意位置的元素。
缺点:插入和删除操作需要移动大量元素,时间复杂度为 O(n)。无法快速找到最久未使用的元素,需要遍历整个数组。
2. 单向链表
优点:插入和删除操作的时间复杂度为 O(1)。
缺点:删除操作需要找到目标节点的前一个节点,需要从头开始遍历,时间复杂度为 O(n)。无法快速访问最久未使用的节点,需要从头开始遍历。
3. 队列
优点:可以快速访问队首和队尾的元素。
缺点:无法在队列中间插入或删除元素,无法快速将某个节点移动到队尾。无法快速找到某个特定的键值对。
4. 堆(如优先队列)
优点:可以快速找到最大值或最小值。
缺点:堆的插入和删除操作的时间复杂度为 O(logn),无法在 O(1) 时间内完成。无法快速找到某个特定的键值对。
双向链表的优势总结:
高效插入和删除:双向链表允许在 O(1) 时间内完成节点的插入和删除操作。
快速访问最久未使用的节点:双向链表的头部始终是最久未使用的节点,可以直接访问。
灵活的节点移动:可以快速将任意节点移动到链表的尾部,表示其最近被使用。
明白了为什么使用双向链表和哈希表之后,下面给出详细的算法步骤和代码来实现这道题:
数据结构设计:
- 双向链表(Doubly Linked List):用于维护最近使用的顺序。链表的头部是最久未使用的节点,尾部是最近使用的节点。每个节点存储键值对 (key, value)。
- 哈希表(HashMap):用于快速查找节点。键是 key,值是对应的双向链表节点。
初始化:
- 初始化缓存容量 capacity。
- 初始化哈希表 cache。
- 初始化双向链表的虚拟头节点 head 和虚拟尾节点 tail,并连接它们。
class LRUCache {
private final int capacity;
private final Map<Integer, Node> cache;
private final Node head;
private final Node tail;
public LRUCache(int capacity) {
this.capacity = capacity;
this.cache = new HashMap<>();
this.head = new Node(-1, -1); // 虚拟头节点
this.tail = new Node(-1, -1); // 虚拟尾节点
head.next = tail;
tail.prev = head;
}
}
算法步骤:
1. get(int key) 操作
目标:如果键存在于缓存中,返回其值,并将其标记为最近使用;如果不存在,返回 -1。
(1)查找键:
- 在哈希表中查找键 key。
- 如果键不存在,返回 -1。
(2)更新节点位置:
- 如果键存在,获取对应的节点 node。
- 将该节点从双向链表中移除(调用 _remove(node))。
- 将该节点添加到双向链表的尾部(调用 _add(node))。
(3)返回值:返回节点的值 node.value。
public int get(int key) {
if (!cache.containsKey(key)) {
return -1;
}
Node node = cache.get(key);
remove(node); // 移除旧位置
add(node); // 添加到尾部
return node.value;
}
2. put(int key, int value) 操作
目标:插入或更新键值对,并维护缓存的容量限制。
(1)如果键存在:
- 更新节点的值 node.value = value。
- 将该节点从双向链表中移除(调用 _remove(node))。
(2)插入新节点:
- 创建一个新节点 node = new Node(key, value)。
- 将新节点添加到双向链表的尾部(调用 _add(node))。
- 将新节点存入哈希表 cache.put(key, node)。
(3)检查容量:
- 如果缓存大小超过容量 capacity:
- 删除双向链表头部的节点(最久未使用的节点)。
- 从哈希表中移除对应的键 del cache[lruNode.key]。
public void put(int key, int value) {
if (cache.containsKey(key)) {
Node node = cache.get(key);
node.value = value; // 更新值
remove(node); // 移除旧位置
} else {
Node node = new Node(key, value);
if (cache.size() >= capacity) {
// 删除最久未使用的节点(头节点的下一个)
Node lruNode = head.next;
remove(lruNode);
cache.remove(lruNode.key);
}
cache.put(key, node);
}
add(cache.get(key)); // 添加到尾部
}
3. 辅助操作
(1) remove(Node node):
从双向链表中移除指定节点。
更新前后节点的指针:
node.prev.next = node.next;
node.next.prev = node.prev;
(2) add(Node node):
将节点添加到双向链表的尾部。
更新尾部节点的指针:
Node prev = tail.prev;
prev.next = node;
tail.prev = node;
node.prev = prev;
node.next = tail;
完整 Java 代码实现:
import java.util.HashMap;
import java.util.Map;
class LRUCache {
private final int capacity;
private final Map<Integer, Node> cache;
private final Node head;
private final Node tail;
static class Node {
int key;
int value;
Node prev;
Node next;
Node(int key, int value) {
this.key = key;
this.value = value;
}
}
public LRUCache(int capacity) {
this.capacity = capacity;
this.cache = new HashMap<>();
this.head = new Node(-1, -1); // 虚拟头节点
this.tail = new Node(-1, -1); // 虚拟尾节点
head.next = tail;
tail.prev = head;
}
public int get(int key) {
if (!cache.containsKey(key)) {
return -1;
}
Node node = cache.get(key);
// 移除旧位置
remove(node);
// 添加到尾部
add(node);
return node.value;
}
public void put(int key, int value) {
if (cache.containsKey(key)) {
// 如果键存在,更新值并移除旧位置
Node node = cache.get(key);
node.value = value;
remove(node);
} else {
// 如果键不存在,创建新节点
Node node = new Node(key, value);
if (cache.size() >= capacity) {
// 如果超出容量,删除最久未使用的节点(头节点的下一个)
Node lruNode = head.next;
remove(lruNode);
cache.remove(lruNode.key);
}
cache.put(key, node);
}
// 添加到尾部
add(cache.get(key));
}
private void remove(Node node) {
// 从双向链表中移除节点
Node prev = node.prev;
Node next = node.next;
prev.next = next;
next.prev = prev;
}
private void add(Node node) {
// 将节点添加到双向链表的尾部
Node prev = tail.prev;
prev.next = node;
tail.prev = node;
node.prev = prev;
node.next = tail;
}
public static void main(String[] args) {
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
System.out.println(lRUCache.get(1)); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
System.out.println(lRUCache.get(2)); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
System.out.println(lRUCache.get(1)); // 返回 -1 (未找到)
System.out.println(lRUCache.get(3)); // 返回 3
System.out.println(lRUCache.get(4)); // 返回 4
}
}
高效实现 LRU 缓存机制:双向链表与哈希表的结合的更多相关文章
- 【golang必备算法】 Letecode 146. LRU 缓存机制
力扣链接:146. LRU 缓存机制 思路:哈希表 + 双向链表 为什么必须要用双向链表? 因为我们需要删除操作.删除一个节点不光要得到该节点本身的指针,也需要操作其前驱节点的指针,而双向链表才能支持 ...
- 【力扣】146. LRU缓存机制
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制.它应该支持以下操作: 获取数据 get 和 写入数据 put . 获取数据 get(key) - 如果关键字 (key) ...
- 146. LRU 缓存机制 + 哈希表 + 自定义双向链表
146. LRU 缓存机制 LeetCode-146 题目描述 题解分析 java代码 package com.walegarrett.interview; /** * @Author WaleGar ...
- [Leetcode]146.LRU缓存机制
Leetcode难题,题目为: 运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制.它应该支持以下操作: 获取数据 get 和 写入数据 put . 获取数据 get(key ...
- Java实现 LeetCode 146 LRU缓存机制
146. LRU缓存机制 运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制.它应该支持以下操作: 获取数据 get 和 写入数据 put . 获取数据 get(key) - ...
- 常见面试题之操作系统中的LRU缓存机制实现
LRU缓存机制,全称Least Recently Used,字面意思就是最近最少使用,是一种缓存淘汰策略.换句话说,LRU机制就是认为最近使用的数据是有用的,很久没用过的数据是无用的,当内存满了就优先 ...
- Q200510-03-03 :LRU缓存机制
LRU缓存机制运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制.它应该支持以下操作: 获取数据 get 和 写入数据 put . 获取数据 get(key) - 如果密钥 ( ...
- Q200510-03-02: LRU缓存机制
问题: LRU缓存机制运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制.它应该支持以下操作: 获取数据 get 和 写入数据 put . 获取数据 get(key) - 如果 ...
- 力扣 - 146. LRU缓存机制
目录 题目 思路 代码 复杂度分析 题目 146. LRU缓存机制 思路 利用双链表和HashMap来解题 看到链表题目,我们可以使用头尾结点可以更好进行链表操作和边界判断等 还需要使用size变量来 ...
- 146. LRU缓存机制
题目描述 运用你所掌握的数据结构,设计和实现一个LRU (最近最少使用) 缓存机制.它应该支持以下操作: 获取数据 get 和 写入数据 put . 获取数据 get(key) - 如果密钥 (key ...
随机推荐
- Typora中markdown文件无法识别行内公式(内联公式)
行内公式属于LaTeX扩展语法,而不属于Markdown的通用标准.为了使Typora予以解析,需要在Typora的"文件"-"偏好设置"中,勾选"内 ...
- 晴神宝典之C /C++快速入门
OJ 补充:runtime error通常原因是数组越界,除零,异常调用,堆栈溢出 尽可能远离TLE 选择c++ 输入输出使用printf和scanf basis 变量名取名: (1)不能是c语言标识 ...
- springboot读取并映射额外的yml配置到bean
项目结构 userPermission.yml # 用户权限 user-permission: api: # 系统管理员 system_manager: - "*:*:*" # 应 ...
- The length of parametric curve (x + sin x, cos x)
问题引入 一个硬币(圆)的周长上有一个点,将硬币在一条线上无滑动地滚动.假设那个点开始时在最上面,滚了半圈到了最下面,求这个点相对于地面的运动轨迹的长度. 或者说,再简单点,自行车总骑过吧.假如你在骑 ...
- mysql页中的行记录头部信息
mysql中具体的数据是存储在行中的,而行是存储在页中的.也就是说页是凌驾于行之上的. mysq一个页大小为16K,当然这个大小是可以通过修改配置文件来改变的. mysql页结构大致示意图: 当我们新 ...
- 超实用!Dify调用Java的3种实现方式!
在一些复杂的业务中,我们可能需要使用 Dify 调用外部程序(如 Java 程序),因为这样才能满足业务的特殊需求. 例如,当我们使用 Dify 实现"AI 简历自动筛选器"的时候 ...
- Vue鼠标与键盘事件触发汇总
Vue鼠标与键盘事件触发汇总 一.鼠标事件 1.悬浮事件 @mouseenter :进入 @mouseover:在 @mousemove:移动 @mouseout:移出 @mouseleave:离开 ...
- helmfile使用
说明 使用helmfile时,我们首先得了解helm的使用,以及如何开发一个helm chart. helm是kubernetes的包管理工具.在实际的使用场景中我们涉及同时部署多个chart.区分不 ...
- Golang基础笔记四之map
本文首发于公众号:Hunter后端 原文链接:Golang基础笔记四之map 这一篇笔记介绍 Golang 里 map 相关的内容,以下是本篇笔记目录: map 的概念及其声明与初始化 map 的增删 ...
- [CSP-S 2022] 策略游戏
link 历年来最简单的 T2. 我们直接暴力分讨: 首先不考虑 \(0\). A 区间全为正数 (1) B 区间全为正数,A 取最大, B 取最小 (2) B 区间有正有负,A 取最小,B 取最小 ...