MongoDB下Map-Reduce使用简单翻译及示例
Map-reduce是一种数据处理范例,用于将大量数据压缩为有用的聚合结果。 对于map-reduce操作,MongoDB提供了mapReduce数据库命令。
一个简单的map-reduce示例如下:
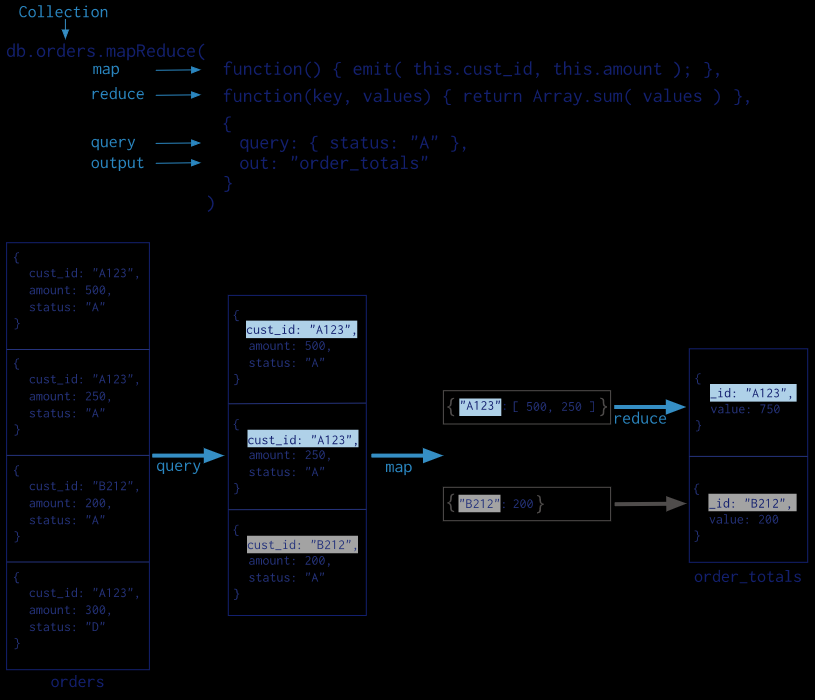
在此map-reduce操作中,MongoDB将映射(map)操作应用于每个输入文档(即集合中与查询条件匹配的文档)。map函数提交(emit)一个键值对(key-value)。对于具有多个值的key钥,MongoDB应用reduce操作,该操作用于聚合数据。然后MongoDB将结果存储在一个集合中。reduce函数的输出还可以选择通过finalize函数以进一步压缩或处理聚合的结果。
MongoDB中的所有map-reduce函数都是JavaScript,并在mongod进程中运行。 Map-reduce操作将单个集合的文档作为输入,并可在开始映射阶段之前执行任意排序和限制。 mapReduce可以将map-reduce操作的结果作为文档返回,也可以将结果写入集合。 输入和输出集合可以分片。
对于大多数聚合操作,聚合管道( Aggregation Pipeline)[https://docs.mongodb.com/manual/core/aggregation-pipeline/]提供更好的性能和更一致的接口。 但是,map-reduce操作提供了一些目前在聚合管道中不可用的灵活性。
Map-Reduce JavaScript 函数
在MongoDB中,map-reduce操作使用自定义JavaScript函数将值(value)映射或关联到键(key)。 如果某个键(key)有对应多个值(value),则该操作应该将键的值reduces为单个对象。
使用自定义JavaScript函数可以灵活地进行map-reduce操作。 例如,在处理文档时,map函数可以创建多个键和值映射或不进行映射。 Map-reduce操作还可以使用自定义JavaScript函数对映射的结果进行最终修改,并在映射操作的最后阶段进行reduce操作,执行其他计算。
Map-Reduce 行为
在MongoDB中,map-reduce操作可以将结果写入集合或返回结果内联。 如果将map-reduce输出写入集合,则可以在合并替换,合并或减少新结果与先前结果的同一输入集合上执行后续map-reduce操作。 有关详细信息和示例,请参阅mapReduce和Perform Incremental(执行增量) Map-Reduce。
当返回map-reduce操作的内联结果时,结果文档必须在BSON文档大小限制内,该限制当前为16兆字节。 有关map-reduce操作的限制和限制的其他信息,请参阅mapReduce参考页面。
MongoDB支持分片集合上的map-reduce操作。 Map-reduce操作还可以将结果输出到分片集合。 请参见Map-Reduce and Sharded Collections。
Views(视图)不支持map-reduce操作。
一个简单的测试
MongoDB地理空间数据存储及检索
上面链接是之前曾经做过一个全国县级行政边界矢量入库到MongoDB的记录,这里用它来测试一下。
简单的测试一下全国每个省都有多少个县
db.getCollection('xzbj').mapReduce(
function() { emit(this.properties.sheng,1);},
function(key,values){return Array.sum(values);},
{
query:{},
out:"xian_count"
}
)
这里将结果输出到了xian_count这个新的集合中,可以打开这个集合查看结果。
上面的query也可以没有,就是默认集合内全部文档。
如果不想把结果输出到一个集合,直接显示结果,则可以使用out: { inline: 1 }。
计算一下湖南省每个地级市有多少个县
使用下面语句
db.getCollection('xzbj').mapReduce(
function() { emit(this.properties.di,1);},
function(key,values){return Array.sum(values);},
{
query:{ 'properties.sheng':'湖南'},
out: { inline: 1 }
}
)
得到输出如下(这里如果是针对全国的数据是有问题的,因为之前没有正确处理港澳台数据):
{
"results" : [
{
"_id" : "娄底市",
"value" : 5.0
},
{
"_id" : "岳阳市",
"value" : 7.0
},
{
"_id" : "常德市",
"value" : 9.0
},
{
"_id" : "张家界市",
"value" : 3.0
},
{
"_id" : "怀化市",
"value" : 12.0
},
{
"_id" : "株洲市",
"value" : 6.0
},
{
"_id" : "永州市",
"value" : 10.0
},
{
"_id" : "湘潭市",
"value" : 4.0
},
{
"_id" : "湘西土家族苗族自治州",
"value" : 8.0
},
{
"_id" : "益阳市",
"value" : 6.0
},
{
"_id" : "衡阳市",
"value" : 8.0
},
{
"_id" : "邵阳市",
"value" : 11.0
},
{
"_id" : "郴州市",
"value" : 11.0
},
{
"_id" : "长沙市",
"value" : 5.0
}
],
"timeMillis" : 19.0,
"counts" : {
"input" : 105,
"emit" : 105,
"reduce" : 14,
"output" : 14
},
"ok" : 1.0,
"_o" : {
"results" : [
{
"_id" : "娄底市",
"value" : 5.0
},
{
"_id" : "岳阳市",
"value" : 7.0
},
{
"_id" : "常德市",
"value" : 9.0
},
{
"_id" : "张家界市",
"value" : 3.0
},
{
"_id" : "怀化市",
"value" : 12.0
},
{
"_id" : "株洲市",
"value" : 6.0
},
{
"_id" : "永州市",
"value" : 10.0
},
{
"_id" : "湘潭市",
"value" : 4.0
},
{
"_id" : "湘西土家族苗族自治州",
"value" : 8.0
},
{
"_id" : "益阳市",
"value" : 6.0
},
{
"_id" : "衡阳市",
"value" : 8.0
},
{
"_id" : "邵阳市",
"value" : 11.0
},
{
"_id" : "郴州市",
"value" : 11.0
},
{
"_id" : "长沙市",
"value" : 5.0
}
],
"timeMillis" : 19,
"counts" : {
"input" : 105,
"emit" : 105,
"reduce" : 14,
"output" : 14
},
"ok" : 1.0
},
"_keys" : [
"results",
"timeMillis",
"counts",
"ok"
],
"_db" : {
"_mongo" : {
"slaveOk" : true,
"host" : "127.0.0.1:27017",
"defaultDB" : "test",
"_readMode" : "commands"
},
"_name" : "us"
}
}
MongoDB下Map-Reduce使用简单翻译及示例的更多相关文章
- map/reduce类简单介绍
在Hadoop的mapper类中,有4个主要的函数,分别是:setup,clearup,map,run.代码如下: protected void setup(Context context) thro ...
- 入门大数据---Map/Reduce,Yarn是什么?
简单概括:Map/Reduce是分布式离线处理的一个框架. Yarn是Map/Reduce中的一个资源管理器. 一.图形说明下Map/Reduce结构: 官方示意图: 另外还可以参考这个: 流程介绍: ...
- MongoDB Map Reduce(转载)
MongoDB Map Reduce Map-Reduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE). MongoDB提供的Map ...
- 记一次MongoDB Map&Reduce入门操作
需求说明 用Map&Reduce计算几个班级中,每个班级10岁和20岁之间学生的数量: 需求分析 学生表的字段: db.students.insert({classid:1, age:14, ...
- ODPS 下一个map / reduce 准备
阿里接到一个电话说练习和比赛智能二选一, 真的很伤心, 练习之前积极老龄化的权利. 要总结ODPS下一个 写map / reduce 并进行购买预测过程. 首先这里的hadoop输入输出都是表的形式, ...
- mongodb Map/reduce测试代码
private void AccountInfo() { ls.Clear(); DateTime dt = DateTime.Now.Date; IMongoQuery query = Query& ...
- 分布式基础学习(2)分布式计算系统(Map/Reduce)
二. 分布式计算(Map/Reduce) 分 布式式计算,同样是一个宽泛的概念,在这里,它狭义的指代,按Google Map/Reduce框架所设计的分布式框架.在Hadoop中,分布式文件 系统,很 ...
- 分布式基础学习【二】 —— 分布式计算系统(Map/Reduce)
二. 分布式计算(Map/Reduce) 分布式式计算,同样是一个宽泛的概念,在这里,它狭义的指代,按Google Map/Reduce框架所设计的分布式框架.在Hadoop中,分布式文件系统,很大程 ...
- 数据库-mongodb-聚合与map reduce
分组统计:group() 简单聚合:aggregate() 强大统计:mapReduce() Group函数: 1.不支持集群.分片,无法分布式计算 2.需要手写聚合函数的业务逻辑 curr指当前行, ...
随机推荐
- java实现点选汉字验证码(转)
package com.rd.p2p.web; import java.awt.BasicStroke; import java.awt.Color; import java.awt.Font; im ...
- oracle左连接连表查询
要想把该表的数据全部查出来,必须select中出现该表的字段. SELECT distinct a.ZGSWSKFJ_DM,b.ZGSWJ_DM,b.SSGLY_DM,b.NSRSBH,b.NSRMC ...
- 利用Python中的mock库对Python代码进行模拟测试
这篇文章主要介绍了利用Python中的mock库对Python代码进行模拟测试,mock库自从Python3.3依赖成为了Python的内置库,本文也等于介绍了该库的用法,需要的朋友可以参考下 ...
- Cinema CodeForces - 670C (离散+排序)
Moscow is hosting a major international conference, which is attended by n scientists from different ...
- 003.Ceph扩展集群
一 基础准备 参考<002.Ceph安装部署>文档部署一个基础集群. 二 扩展集群 2.1 扩展架构 需求:添加Ceph元数据服务器node1.然后添加Ceph Monitor和Ceph ...
- 对Promise的一些深入了解
1.介绍promise和模仿Promise.all和Promise.race promise的设计主要是解决回调地狱(接收结果用回调函数来处理,但必须传入回调函数)的问题,由一层层嵌套回调函数改为由t ...
- Linux系统开发之路-中
4.Linux的安装(Windows环境下): 1)Windows环境需要借助虚拟机来安装Linux系统,这个推荐使用的软件是VMWare,官网能下载到的最新版本是Workstation Pro15. ...
- 自己总结的C#编码规范--6.格式篇
格式 格式的统一使用可以使代码清晰.美观.方便阅读.为了不影响编码效率,在此只作如下规定: 长度 一个文件最好不要超过500行(除IDE自动生成的类). 一个文件必须只有一个命名空间,严禁将多个命名空 ...
- Xamarin Essentials教程数据处理传输数据
Xamarin Essentials教程数据处理传输数据 在移动应用程序中,除了常规的数据处理,还涉及数据存储.数据传输.版本数据多个方面.Xamarin.Essentials组件提供了多个数据处理相 ...
- Java笔记(十二) 文件基础技术
文件基础技术 一.文件概述 一)基本概念 1.文件的分类: 1)文本文件:文件中每个二进制字节都是某个可打印字符的一部分.如.java文件 2)二进制文件:文件中每个二进制字节不一定用来表示字符,也可 ...