高可用OpenStack(Queen版)集群-2.基础服务
参考文档:
- Install-guide:https://docs.openstack.org/install-guide/
- OpenStack High Availability Guide:https://docs.openstack.org/ha-guide/index.html
- 理解Pacemaker:http://www.cnblogs.com/sammyliu/p/5025362.html
三.Mariadb集群
1. 安装mariadb
# 在全部controller节点安装mariadb,以controller01节点为例
[root@controller01 ~]# yum install mariadb mariadb-server python2-PyMySQL -y # 安装galera相关插件,利用galera搭建集群
[root@controller01 ~]# yum install mariadb-server-galera mariadb-galera-common galera xinetd rsync -y
2. 初始化mariadb
# 在全部控制节点初始化数据库密码,以controller01节点为例;
# root初始密码为空
[root@controller01 ~]# systemctl restart mariadb.service
[root@controller01 ~]# mysql_secure_installation
Enter current password for root (enter for none):
Set root password? [Y/n] y
New password:
Re-enter new password:
Remove anonymous users? [Y/n] y
Disallow root login remotely? [Y/n] n
Remove test database and access to it? [Y/n] y
Reload privilege tables now? [Y/n] y
3. 修改mariadb配置文件
# 在全部控制节点/etc/my.cnf.d/目录下新增openstack.cnf配置文件,主要设置集群同步相关参数,以controller01节点为例,个别涉及ip地址/host名等参数根据实际情况修改
[root@controller01 my.cnf.d]# cat /etc/my.cnf.d/openstack.cnf
[mysqld]
binlog_format = ROW
bind-address = 172.30.200.31
default-storage-engine = innodb
innodb_file_per_table = on
max_connections = 4096
collation-server = utf8_general_ci
character-set-server = utf8
[galera]
bind-address = 172.30.200.31
wsrep_provider = /usr/lib64/galera/libgalera_smm.so
wsrep_cluster_address ="gcomm://controller01,controller02,controller03"
wsrep_cluster_name = openstack-cluster-01
wsrep_node_name = controller01
wsrep_node_address = 172.30.200.31
wsrep_on=ON
wsrep_slave_threads=4
wsrep_sst_method=rsync
default_storage_engine=InnoDB
[embedded]
[mariadb]
[mariadb-10.1]
4. 构建mariadb集群
# 停止全部控制节点的mariadb服务,以controller01节点为例
[root@controller01 ~]# systemctl stop mariadb.service # 任选1个控制节点以如下方式启动mariadb服务,这里选择controller01节点
[root@controller01 ~]# /usr/libexec/mysqld --wsrep-new-cluster --user=root & # 其他控制节点加入mariadb集群,以controller02节点为例;
# 启动后加入集群,controller02节点从controller01节点同步数据,也可同步查看mariadb日志/var/log/mariadb/mariadb.log
[root@controller02 ~]# systemctl start mariadb.service
[root@controller02 ~]# systemctl status mariadb.service
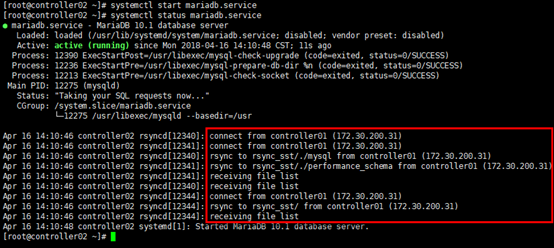
# 重新启动controller01节点;
# 启动前删除contrller01节点的数据
[root@controller01 ~]# pkill -9 mysql
[root@controller01 ~]# rm -rf /var/lib/mysql/* # 注意以system unit方式启动mariadb服务时的权限
[root@controller01 ~]# chown mysql:mysql /var/run/mariadb/mariadb.pid # 启动后查看节点所在服务状态,controller01节点从controller02节点同步数据
[root@controller01 ~]# systemctl start mariadb.service
[root@controller01 ~]# systemctl status mariadb.service
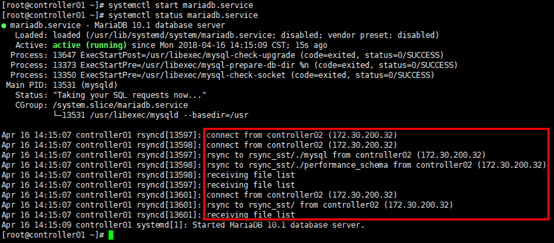
# 查看集群状态
[root@controller01 ~]# mysql -uroot -pmysql_pass
MariaDB [(none)]> show status like "wsrep_cluster_size";
MariaDB [(none)]> SHOW status LIKE 'wsrep_ready';
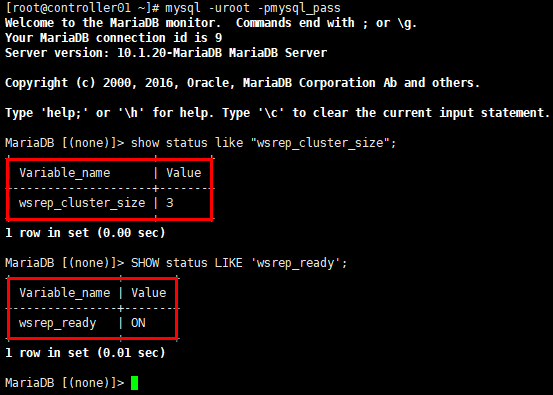
5. 设置心跳检测clustercheck
1)准备脚本
# 下载clustercheck脚本
[root@controller01 ~]# wget https://raw.githubusercontent.com/olafz/percona-clustercheck/master/clustercheck # 赋权
[root@controller01 ~]# chmod +x clustercheck
[root@controller01 ~]# cp ~/clustercheck /usr/bin/
2)创建心跳检测用户
# 在任意控制节点创建clustercheck_user用户并赋权;
# 注意账号/密码与脚本中的账号/密码对应,这里采用的是脚本默认的账号/密码,否则需要修改clustercheck脚本文件
[root@controller01 ~]# mysql -uroot -pmysql_pass
MariaDB [(none)]> GRANT PROCESS ON *.* TO 'clustercheckuser'@'localhost' IDENTIFIED BY 'clustercheckpassword!';
MariaDB [(none)]> FLUSH PRIVILEGES;
3)检测配置文件
# 在全部控制节点新增心跳检测服务配置文件/etc/xinetd.d/mysqlchk,以controller01节点为例
[root@controller01 ~]# touch /etc/xinetd.d/mysqlchk
[root@controller01 ~]# vim /etc/xinetd.d/mysqlchk
# default: on
# description: mysqlchk
service mysqlchk
{
port = 9200
disable = no
socket_type = stream
protocol = tcp
wait = no
user = root
group = root
groups = yes
server = /usr/bin/clustercheck
type = UNLISTED
per_source = UNLIMITED
log_on_success =
log_on_failure = HOST
flags = REUSE
}
4)启动心跳检测服务
# 修改/etc/services,变更tcp9200端口用途,以controller01节点为例
[root@controller01 ~]# vim /etc/services
#wap-wsp 9200/tcp # WAP connectionless session service
mysqlchk 9200/tcp # mysqlchk # 启动xinetd服务,以controller01节点为例
[root@controller01 ~]# systemctl daemon-reload
[root@controller01 ~]# systemctl enable xinetd
[root@controller01 ~]# systemctl start xinetd
5)测试心跳检测脚本
# 在全部控制节点验证,以controller01节点为例
[root@controller01 ~]# /usr/bin/clustercheck
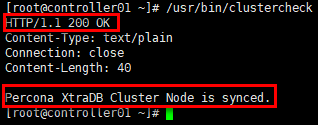
四.RabbitMQ集群
采用openstack官方的安装方法,在未更新erlang的情况下,rabbitmq不是最新版本。
如果需要部署最新版本rabbitmq集群,可参考:http://www.cnblogs.com/netonline/p/7678321.html
1. 安装rabbitmq
# 在全部控制节点,使用aliyun的epel镜像,以controller01节点为例
[root@controller01 ~]# wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
[root@controller01 ~]# yum install erlang rabbitmq-server -y # 设置开机启动
[root@controller01 ~]# systemctl enable rabbitmq-server.service
2. 构建rabbitmq集群
# 任选1个控制节点首先启动rabbitmq服务,这里选择controller01节点
[root@controller01 ~]# systemctl start rabbitmq-server.service
[root@controller01 ~]# rabbitmqctl cluster_status # 分发.erlang.cookie
[root@controller01 ~]# scp /var/lib/rabbitmq/.erlang.cookie root@172.30.200.32:/var/lib/rabbitmq/
[root@controller01 ~]# scp /var/lib/rabbitmq/.erlang.cookie root@172.30.200.33:/var/lib/rabbitmq/ # 修改controller02/03节点.erlang.cookie文件的用户/组,以controller02节点为例
[root@controller02 ~]# chown rabbitmq:rabbitmq /var/lib/rabbitmq/.erlang.cookie # 注意修改全部控制节点.erlang.cookie文件的权限,默认即400权限,可不修改
[root@controller02 ~]# ll /var/lib/rabbitmq/.erlang.cookie # 启动controller02/03节点的rabbitmq服务
[root@controller02 ~]# systemctl start rabbitmq-server [root@controller03 ~]# systemctl start rabbitmq-server # 构建集群,controller02/03节点以ram节点的形式加入集群
[root@controller02 ~]# rabbitmqctl stop_app
[root@controller02 ~]# rabbitmqctl join_cluster --ram rabbit@controller01
[root@controller02 ~]# rabbitmqctl start_app
[root@controller03 ~]# rabbitmqctl stop_app
[root@controller03 ~]# rabbitmqctl join_cluster --ram rabbit@controller01
[root@controller03 ~]# rabbitmqctl start_app
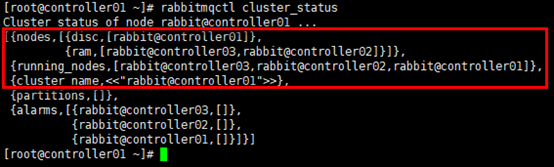
# 任意节点可验证集群状态
[root@controller01 ~]# rabbitmqctl cluster_status
3. rabbitmq账号
# 在任意节点新建账号并设置密码,以controller01节点为例
[root@controller01 ~]# rabbitmqctl add_user openstack rabbitmq_pass # 设置新建账号的状态
[root@controller01 ~]# rabbitmqctl set_user_tags openstack administrator # 设置新建账号的权限
[root@controller01 ~]# rabbitmqctl set_permissions -p "/" openstack ".*" ".*" ".*" # 查看账号
[root@controller01 ~]# rabbitmqctl list_users
4. 镜像队列ha
# 设置镜像队列高可用
[root@controller01 ~]# rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}' # 查看镜像队列策略
[root@controller01 ~]# rabbitmqctl list_policies
5. 安装web管理插件
# 在全部控制节点安装web管理插件,以controller01节点为例
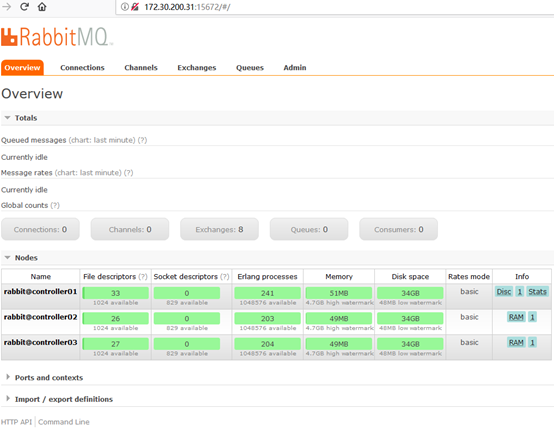
[root@controller01 ~]# rabbitmq-plugins enable rabbitmq_management 访问任意节点,如:http://172.30.200.31:15672
五.Memcached集群
Memcached是无状态的,各控制节点独立部署,openstack各服务模块统一调用多个控制节点的memcached服务即可。
采用openstack官方的安装方法,如果需要部署最新版本memcached,可参考:http://www.cnblogs.com/netonline/p/7805900.html
以下配置以controller01节点为例。
1. 安装memcached
# 在全部控制节点安装memcached
[root@controller01 ~]# yum install memcached python-memcached -y
2. 设置memcached
# 在全部安装memcached服务的节点设置服务监听地址
[root@controller01 ~]# sed -i 's|127.0.0.1,::1|0.0.0.0|g' /etc/sysconfig/memcached
3. 开机启动
[root@controller01 ~]# systemctl enable memcached.service
[root@controller01 ~]# systemctl start memcached.service
[root@controller01 ~]# systemctl status memcached.service
高可用OpenStack(Queen版)集群-2.基础服务的更多相关文章
- Corosync+Pacemaker+DRBD+MySQL 实现高可用(HA)的MySQL集群
大纲一.前言二.环境准备三.Corosync 安装与配置四.Pacemaker 安装与配置五.DRBD 安装与配置六.MySQL 安装与配置七.crmsh 资源管理 推荐阅读: Linux 高可用(H ...
- 高可用,完全分布式Hadoop集群HDFS和MapReduce安装配置指南
原文:http://my.oschina.net/wstone/blog/365010#OSC_h3_13 (WJW)高可用,完全分布式Hadoop集群HDFS和MapReduce安装配置指南 [X] ...
- Linux 高可用(HA)集群之keepalived详解
http://freeloda.blog.51cto.com/2033581/1280962 大纲 一.前言 二.Keepalived 详解 三.环境准备 四.LVS+Keepalived 实现高可用 ...
- Linux 高可用(HA)集群基本概念详解
大纲一.高可用集群的定义二.高可用集群的衡量标准三.高可用集群的层次结构四.高可用集群的分类 五.高可用集群常用软件六.共享存储七.集群文件系统与集群LVM八.高可用集群的工作原理 推荐阅读: Cen ...
- 16套java架构师,高并发,高可用,高性能,集群,大型分布式电商项目实战视频教程
16套Java架构师,集群,高可用,高可扩展,高性能,高并发,性能优化,设计模式,数据结构,虚拟机,微服务架构,日志分析,工作流,Jvm,Dubbo ,Spring boot,Spring cloud ...
- 分布式架构高可用架构篇_03-redis3集群的安装高可用测试
参考文档 Redis 官方集群指南:http://redis.io/topics/cluster-tutorial Redis 官方集群规范:http://redis.io/topics/cluste ...
- 通过LVS+Keepalived搭建高可用的负载均衡集群系统
1. 安装LVS软件 (1)安装前准备操作系统:统一采用Centos6.5版本,地址规划如下: 服务器名 IP地址 网关 虚拟设备名 虚拟ip Director Server 192.168 ...
- 分布式架构高可用架构篇_01_zookeeper集群的安装、配置、高可用测试
参考: 龙果学院http://www.roncoo.com/share.html?hamc=hLPG8QsaaWVOl2Z76wpJHp3JBbZZF%2Bywm5vEfPp9LbLkAjAnB%2B ...
- 全是干货---Linux 高可用(HA)集群基本概念详解
http://www.linuxidc.com/Linux/2013-08/88522.htm 高可用集群的衡量标准 HA(High Available), 高可用性群集是通过系统的可靠性(re ...
随机推荐
- 《Java程序设计》第12周课堂实践总结
<Java程序设计>第12周课堂实践总结 实践一 教材代码检查-p98 要求 修改教材P98 Score2.java, 让执行结果数组填充是自己的学号: 提交在IDEA或命令行中运行结查截 ...
- smtp outlook邮件发送非授权码模式
1.起因:send fail SMTP AUTH extension not supported by server. 使用端口25 和587均失效出现此问题 首先前往outlook修改设置pop和I ...
- 解决JS在url中传递参数时参数包含中文乱码的问题
1.传参页面JavaScript代码: function go_mark(id,jobname,headimgurl,nickname){ window.location.href = "m ...
- CanOpen协议【CanFestival】移植方法 支持VC、QT、STM32
前段时间学习了CanOpen协议,到网上下载的CanFestival3-10源码,移植到VC.QT.STM32等平台,由于网上的资源较少,走了不少弯路,移植好使用过程中才逐渐暴露出各种问题,比如OD字 ...
- UVa 10377 - Maze Traversal
題目:一個機器人在迷宮中行走,它的指令是方向控制(前進.左轉.右轉).給你初始位置和一些指令: 問最後停在那個位置. 分析:模擬.直接模擬就可以,注意一下細節. 假设,不能行走(邊界或者是墻壁)則停在 ...
- Mysql 5.7 windows安装 zip安装
最近想安装一个本地数据库, 发现网上写的没一个能安装成功的, 各种蛋疼, 我还是自己写一个吧 参考链接: https://www.cnblogs.com/by330326/p/5608290.html ...
- c语言计算功能
---恢复内容开始--- #include <stdio.h> int main(){int a1,a2,a3,a4; printf("请输入数值"); a4=0;wh ...
- 数据结构与算法之Stack(栈)的应用——in dart
参考教科书上的一个应用例子,用栈来分析一行输入中的括号brackets是否匹配.用stdin读取用户输入,并输出检查结果.exit 退出. 注意这行代码: import 'stack.dart';// ...
- 使用promis串行化异步操作
该代码可在chrome下运行,对于低版本浏览器可以引入Q库 function async1() { var defer = Promise.defer() setTimeout(function(){ ...
- node auto run / node 自动运行
http://stackoverflow.com/questions/20445599/auto-start-node-js-server-on-boot http://stackoverflow.c ...