spark集群安装[转]
========================================================================================
一、基础环境
========================================================================================
1、服务器分布
10.217.145.244 主名字节点
10.217.145.245 备名字节点
10.217.145.246 数据节点1
10.217.145.247 数据节点2
10.217.145.248 数据节点3
--------------------------------------------------------------------------------------------------------------------------------------------
2、HOSTS 设置
在每台服务器的“/etc/hosts”文件,添加如下内容:
10.217.145.244 namenode1
10.217.145.245 namenode2
10.217.145.246 datanode1
10.217.145.247 datanode2
10.217.145.248 datanode3
-------------------------------------------------------------------------------------------------------------------------------------------
3、SSH 免密码登录
可参考文章:
http://blog.csdn.net/codepeak/article/details/14447627
......
========================================================================================
二、Hadoop 2.2.0 编译安装【官方提供的二进制版本为32位版本,64位环境需重新编译】
========================================================================================
1、JDK 安装
http://download.oracle.com/otn-pub/java/jdk/7u45-b18/jdk-7u45-linux-x64.tar.gz
# tar xvzf jdk-7u45-linux-x64.tar.gz -C /usr/local
# cd /usr/local
# ln -s jdk1.7.0_45 jdk
# vim /etc/profile
export JAVA_HOME=/usr/local/jdk
export CLASS_PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin
# source /etc/profile
------------------------------------------------------------------------------------------------------------------------------------------
2、MAVEN 安装
http://mirror.bit.edu.cn/apache/maven/maven-3/3.1.1/binaries/apache-maven-3.1.1-bin.tar.gz
# tar xvzf apache-maven-3.1.1-bin.tar.gz -C /usr/local
# cd /usr/local
# ln -s apache-maven-3.1.1 maven
# vim /etc/profile
export MAVEN_HOME=/usr/local/maven
export PATH=$PATH:$MAVEN_HOME/bin
# source /etc/profile
# mvn -v

------------------------------------------------------------------------------------------------------------------------------------------
3、PROTOBUF 安装
https://protobuf.googlecode.com/files/protobuf-2.5.0.tar.gz
# tar xvzf protobuf-2.5.0.tar.gz
# ./configure --prefix=/usr/local/protobuf
# make && make install
# vim /etc/profile
export PROTO_HOME=/usr/local/protobuf
export PATH=$PATH:$PROTO_HOME/bin
# source /etc/profile
# vim /etc/ld.so.conf
/usr/local/protobuf/lib
# /sbin/ldconfig
------------------------------------------------------------------------------------------------------------------------------------------
4、其他依赖库安装
http://www.cmake.org/files/v2.8/cmake-2.8.12.1.tar.gz
http://ftp.gnu.org/pub/gnu/ncurses/ncurses-5.9.tar.gz
http://www.openssl.org/source/openssl-1.0.1e.tar.gz
# tar xvzf cmake-2.8.12.1.tar.gz
# cd cmake-2.8.12.1
# ./bootstrap --prefix=/usr/local
# gmake && gmake install
# tar xvzf ncurses-5.9.tar.gz
# cd ncurses-5.9
# ./configure --prefix=/usr/local
# make && make install
# tar xvzf openssl-1.0.1e.tar.gz
# cd openssl-1.0.1e
# ./config shared --prefix=/usr/local
# make && make install
# /sbin/ldconfig
------------------------------------------------------------------------------------------------------------------------------------------
5、编译 Hadoop
http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.2.0/hadoop-2.2.0-src.tar.gz
(1)、maven源设置【在<mirrors></mirros>里添加】
# vim /usr/local/maven/conf/settings.xml
|
1
2
3
4
5
6
|
<mirror> <id>nexus-osc</id> <mirrorOf>*</mirrorOf> <name>Nexusosc</name> <url>http://maven.oschina.net/content/groups/public/</url></mirror> |
(2)、编译Hadoop
# tar xvzf hadoop-2.2.0-src.tar.gz
# cd hadoop-2.2.0-src
# mvn clean install -DskipTests
# mvn package -Pdist,native -DskipTests -Dtar
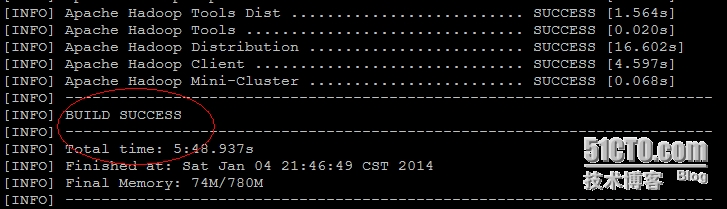
## 编译成功后,生成的二进制包所在路径
hadoop-dist/target/hadoop-2.2.0
# cp -a hadoop-dist/target/hadoop-2.2.0 /usr/local
# cd /usr/local
# ln -s hadoop-2.2.0 hadoop
【注意:编译过程中,可能会失败,需要多尝试几次】
========================================================================================
三、Hadoop YARN 分布式集群配置【注:所有节点都做同样配置】
========================================================================================
1、环境变量设置
# vim /etc/profile
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_PID_DIR=/data/hadoop/pids
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=$HADOOP_HOME/lib/native"
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# source /etc/profile
------------------------------------------------------------------------------------------------------------------------------------------
2、相关路径创建
mkdir -p /data/hadoop/{pids,storage}
mkdir -p /data/hadoop/storage/{hdfs,tmp}
mkdir -p /data/hadoop/storage/hdfs/{name,data}
------------------------------------------------------------------------------------------------------------------------------------------
3、配置 core-site.xml
# vim /usr/local/hadoop/etc/hadoop/core-site.xml
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://namenode1:9000</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/data/hadoop/storage/tmp</value> </property> <property> <name>hadoop.proxyuser.hadoop.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hadoop.groups</name> <value>*</value> </property> <property> <name>hadoop.native.lib</name> <value>true</value> </property></configuration> |
------------------------------------------------------------------------------------------------------------------------------------------
4、配置 hdfs-site.xml
# vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>namenode2:9000</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/data/hadoop/storage/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/data/hadoop/storage/hdfs/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property></configuration> |
------------------------------------------------------------------------------------------------------------------------------------------
5、配置 mapred-site.xml
# vim /usr/local/hadoop/etc/hadoop/mapred-site.xml
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>namenode1:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>namenode1:19888</value> </property></configuration> |
------------------------------------------------------------------------------------------------------------------------------------------
6、配置 yarn-site.xml
# vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>namenode1:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>namenode1:8031</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>namenode1:8032</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>namenode1:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>namenode1:80</value> </property></configuration> |
------------------------------------------------------------------------------------------------------------------------------------------
7、配置 hadoop-env.sh、mapred-env.sh、yarn-env.sh【在开头添加】
文件路径:
/usr/local/hadoop/etc/hadoop/hadoop-env.sh
/usr/local/hadoop/etc/hadoop/mapred-env.sh
/usr/local/hadoop/etc/hadoop/yarn-env.sh
添加内容:
export JAVA_HOME=/usr/local/jdk
export CLASS_PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_PID_DIR=/data/hadoop/pids
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=$HADOOP_HOME/lib/native"
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
------------------------------------------------------------------------------------------------------------------------------------------
8、数据节点配置
# vim /usr/local/hadoop/etc/hadoop/slaves
datanode1
datanode2
datanode3
------------------------------------------------------------------------------------------------------------------------------------------
9、Hadoop 简单测试
# cd /usr/local/hadoop
## 首次启动集群时,做如下操作【主名字节点上执行】
# hdfs namenode -format
# sbin/start-dfs.sh
## 检查进程是否正常启动
# jps
主名字节点:

备名字节点:

数据节点:

## hdfs与mapreduce测试
# hdfs dfs -mkdir -p /user/rocketzhang
# hdfs dfs -put bin/hdfs.cmd /user/rocketzhang
# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /user/rocketzhang /user/out
# hdfs dfs -ls /user/out
## hdfs信息查看
# hdfs dfsadmin -report
# hdfs fsck / -files -blocks
## 集群的后续维护
# sbin/start-all.sh
# sbin/stop-all.sh
## 监控页面URL
http://10.217.145.244:80/
========================================================================================
四、Spark 分布式集群配置【注:所有节点都做同样配置】
========================================================================================
1、Scala 安装
http://www.scala-lang.org/files/archive/scala-2.9.3.tgz
# tar xvzf scala-2.9.3.tgz -C /usr/local
# cd /usr/local
# ln -s scala-2.9.3 scala
# vim /etc/profile
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SCALA_HOME/bin
# source /etc/profile
------------------------------------------------------------------------------------------------------------------------------------------
2、Spark 安装
http://d3kbcqa49mib13.cloudfront.net/spark-0.8.1-incubating-bin-hadoop2.tgz
# tar xvzf spark-0.8.1-incubating-bin-hadoop2.tgz -C /usr/local
# cd /usr/local
# ln -s spark-0.8.1-incubating-bin-hadoop2 spark
# vim /etc/profile
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
# source /etc/profile
# cd /usr/local/spark/conf
# mv spark-env.sh.template spark-env.sh
# vim spark-env.sh
export JAVA_HOME=/usr/local/jdk
export SCALA_HOME=/usr/local/scala
export HADOOP_HOME=/usr/local/hadoop
## worker节点的主机名列表
# vim slaves
datanode1
datanode2
datanode3
# mv log4j.properties.template log4j.properties
## 在Master节点上执行
# cd /usr/local/spark && .bin/start-all.sh
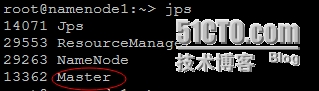
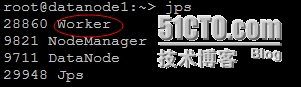
## 检查进程是否启动【在master节点上出现“Master”,在slave节点上出现“Worker”】
# jps
Master节点:
Slave节点:
------------------------------------------------------------------------------------------------------------------------------------------
3、相关测试
## 监控页面URL
http://10.217.145.244:8080/
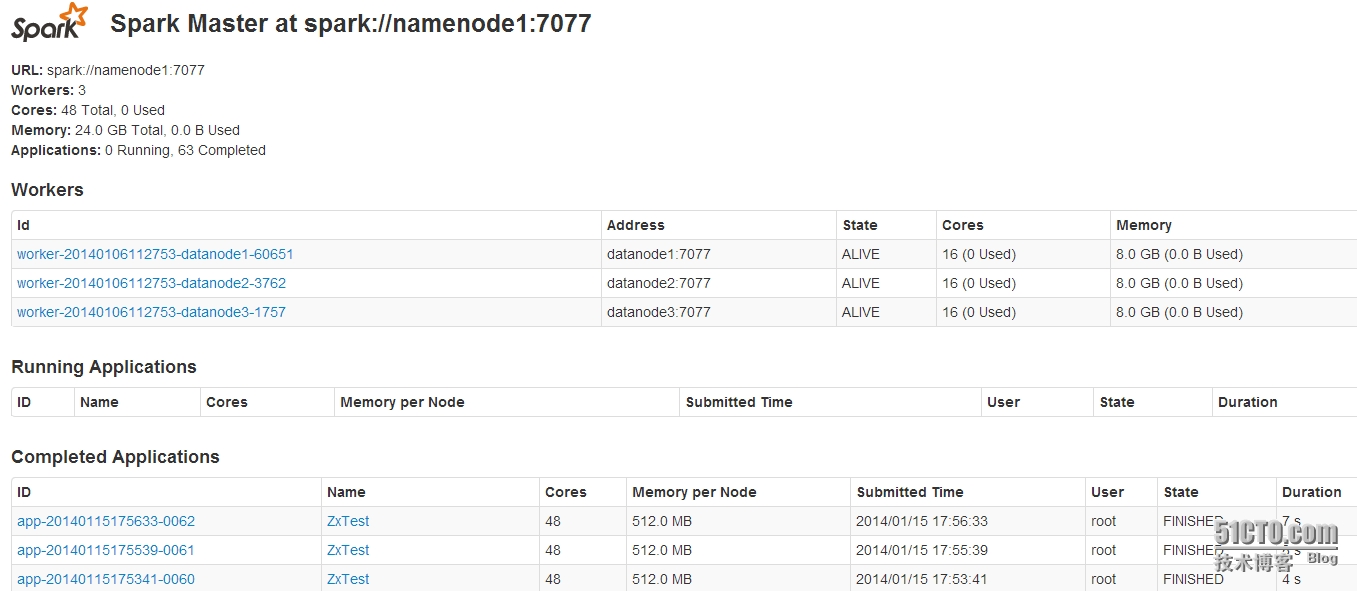
## 先切换到“/usr/local/spark”目录
(1)、本地模式
# ./run-example org.apache.spark.examples.SparkPi local
(2)、普通集群模式
# ./run-example org.apache.spark.examples.SparkPi spark://namenode1:7077
# ./run-example org.apache.spark.examples.SparkLR spark://namenode1:7077
# ./run-example org.apache.spark.examples.SparkKMeans spark://namenode1:7077 file:/usr/local/spark/kmeans_data.txt 2 1
(3)、结合HDFS的集群模式
# hadoop fs -put README.md .
# MASTER=spark://namenode1:7077 ./spark-shell
scala> val file = sc.textFile("hdfs://namenode1:9000/user/root/README.md")
scala> val count = file.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_+_)
scala> count.collect()
scala> :quit
(4)、基于YARN模式
# SPARK_JAR=./assembly/target/scala-2.9.3/spark-assembly_2.9.3-0.8.1-incubating-hadoop2.2.0.jar \
./spark-class org.apache.spark.deploy.yarn.Client \
--jar examples/target/scala-2.9.3/spark-examples_2.9.3-assembly-0.8.1-incubating.jar \
--class org.apache.spark.examples.SparkPi \
--args yarn-standalone \
--num-workers 3 \
--master-memory 4g \
--worker-memory 2g \
--worker-cores 1
执行结果:
/usr/local/hadoop/logs/userlogs/application_*/container*_000001/stdout
(5)、其他一些样例程序
examples/src/main/scala/org/apache/spark/examples/
(6)、问题定位【数据节点上的日志】
/data/hadoop/storage/tmp/nodemanager/logs
(7)、一些优化
# vim /usr/local/spark/conf/spark-env.sh
export SPARK_WORKER_MEMORY=16g 【根据内存大小进行实际配置】
......
(8)、最终的目录结构
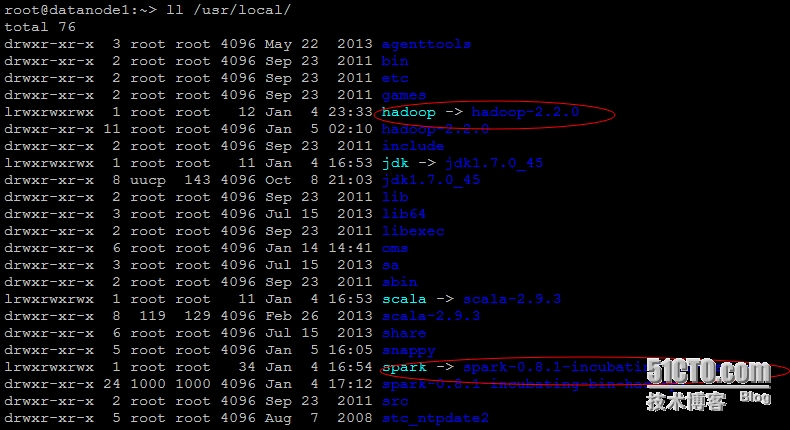
========================================================================================
五、Shark 数据仓库【后续补上】
========================================================================================
https://github.com/amplab/shark/releases
本文出自 “人生理想在于坚持不懈” 博客,请务必保留此出处http://sofar.blog.51cto.com/353572/1352713
spark集群安装[转]的更多相关文章
- [bigdata] spark集群安装及测试
在spark安装之前,应该已经安装了hadoop原生版或者cdh,因为spark基本要基于hdfs来进行计算. 1. 下载 spark: http://mirrors.cnnic.cn/apache ...
- spark集群安装配置
spark集群安装配置 一. Spark简介 Spark是一个通用的并行计算框架,由UCBerkeley的AMP实验室开发.Spark基于map reduce 算法模式实现的分布式计算,拥有Hadoo ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- CentOS6安装各种大数据软件 第十章:Spark集群安装和部署
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- Spark入门:第2节 Spark集群安装:1 - 3;第3节 Spark HA高可用部署:1 - 2
三. Spark集群安装 3.1 下载spark安装包 下载地址spark官网:http://spark.apache.org/downloads.html 这里我们使用 spark-2.1.3-bi ...
- 3 Spark 集群安装
第3章 Spark集群安装 3.1 Spark安装地址 1.官网地址 http://spark.apache.org/ 2.文档查看地址 https://spark.apache.org/docs/2 ...
- Spark 个人实战系列(1)--Spark 集群安装
前言: CDH4不带yarn和spark, 因此需要自己搭建spark集群. 这边简单描述spark集群的安装过程, 并讲述spark的standalone模式, 以及对相关的脚本进行简单的分析. s ...
- 大数据平台搭建-spark集群安装
版本要求 java 版本:1.8.*(1.8.0_60) 下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downl ...
- Spark集群安装和WordCount编写
一.Spark概述 官网:http://spark.apache.org/ Apache Spark™是用于大规模数据处理的统一分析引擎. 为大数据处理而设计的快速通用的计算引擎. Spark加州大学 ...
随机推荐
- Linux运维二:CentOS6.6系统安装后的基本配置与优化
CentOS6.6系统安装完成后还需要做一些配置与优化: 一:Linux内核版本号介绍 查看内核版本: [root@Gin scripts]# uname -r 2.6.32-504.el6.x86_ ...
- windows10下基于vs2015的 caffe安装教程及python接口实现
啦啦啦:根据网上的教程前一天安装失败,第二天才安装成功.其实caffe的安装并不难,只是网上的教程不是很全面,自己写一个,留作纪念. 准备工作 Windows10 操作系统 vs2015(c++编译器 ...
- IOS数组的排序和筛选
1.排序 [self.tableItems sortUsingComparator:^NSComparisonResult(GPBTeacherBrief* obj1, GPBTeacherBrief ...
- java 修饰符总结
java中的修饰符分为类修饰符,字段修饰符,方法修饰符.根据功能的不同,主要分为以下几种. 1.权限访问修饰符 public,protected,default,private,这四种级别 ...
- StringBuffer类和String 类的 equals 和 ==
注意: equals(Object obj)equals方法的参数是任意对象 Object类的equals方法就是用==判断的,即判断两个对象是否为同一个对象 StringBuffer类没有重写equ ...
- soj1762.排座椅
1762. 排座椅 Constraints Time Limit: 1 secs, Memory Limit: 32 MB Description 上课的时候总有一些同学和前后左右的人交头接耳,这是令 ...
- 如何定制Gtk版Emacs的Widget外观
当我们使用 xlib 版的Emacs时,可以通过 XResource 定义 Emacs 的菜单 栏.工具条.滚动条的外观. 现在,在Linux上我们大多使用 gtk版的Emacs,是否还有办法定义 E ...
- Java 图片转字节流 实现 图片->字节流(字符串)->图片
//该方法实现图片转String 参数为图片的路径 可以是file.toString()得到public String testUpload(String path) { try { String s ...
- java反射动态加载类Class.forName();
1,所有的new出来的对象都是静态加载的,在程序编译的时候就会进行加载.而使用反射机制Class.forName是动态加载的,在运行时刻进行加载. 例子:直接上两个例子 public class Ca ...
- CodeForces - 1009B Minimum Ternary String
You are given a ternary string (it is a string which consists only of characters '0', '1' and '2'). ...