【大数据应用技术】作业八|爬虫综合大作业Molly134
本次作业的要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075
前言:本次作业是爬取CBO中国票房2010-2019年每年年度票房排名前25的电影,通过爬取电影的名称、类型、总票房(万)、平均票价、均场人次、国家及地区以及上映时间等数据并对其进行数据分析从而得出相应结论。
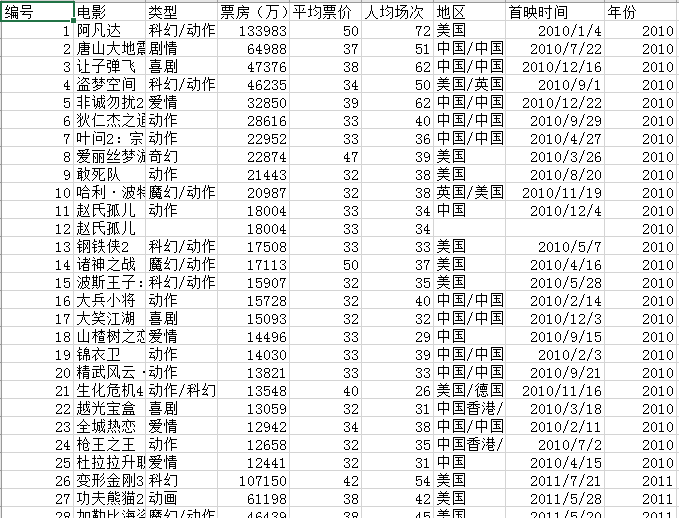
首先,把爬取到的数据存为csv文件,并放在本地中,打开csv文件,可以发现数据已经存进来了,如下图所示。
其次,根据所存数据对其进行数据分析,可以得出以下结论。
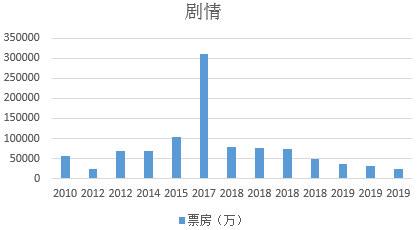
1.统计不同类型电影的平均票房
如下图所示是统计2010年-2019年不同类型电影的平均票房,由此可知2010年-2019年以来喜剧、奇幻、动作、科幻、剧情这几大类型的电影平均票房最多,最受欢迎。
 |
2.分析十年间每年票房冠军的票房走势
按年份对电影进行排名发现2010年-2019年每年的票房冠军分别是阿凡达(2010年)、变形金刚(2011年)、人再囧途之泰囧(2012年)、西游降魔篇(2013年)、变形金刚4:绝迹重生(2014年)、捉妖记(2015年)、美人鱼(2016年)、战狼2(2017年)、红海行动(2018年)、流浪地球(2019年)。
通过统计我们不难发现,2010年以来,随着人们生活水平的提高,电影的综合票房逐年增加,越来越多的人进入电影院看电影。
下图所示为2019年票房排名,其中流浪地球、复仇者联盟4、疯狂的外星人这三大电影的票房最好,其中流浪地球更是高达465488万票房。
 |
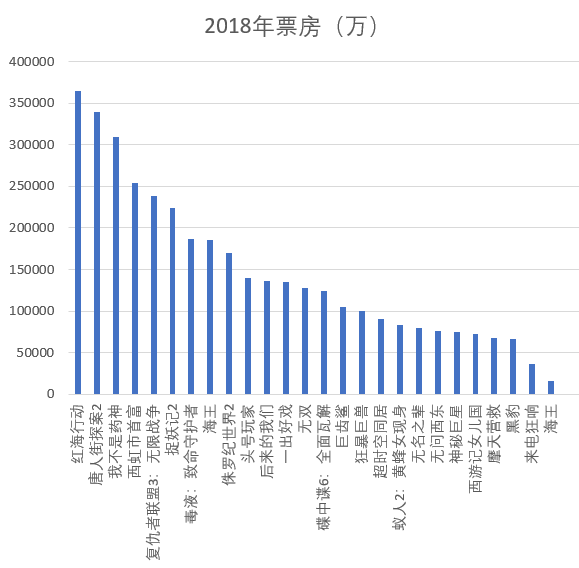
下图所示为2018年票房排名,红海行动、唐人街探案2、我不是药神这三大电影为年度前三,而其余电影的票房较为接近。
 |
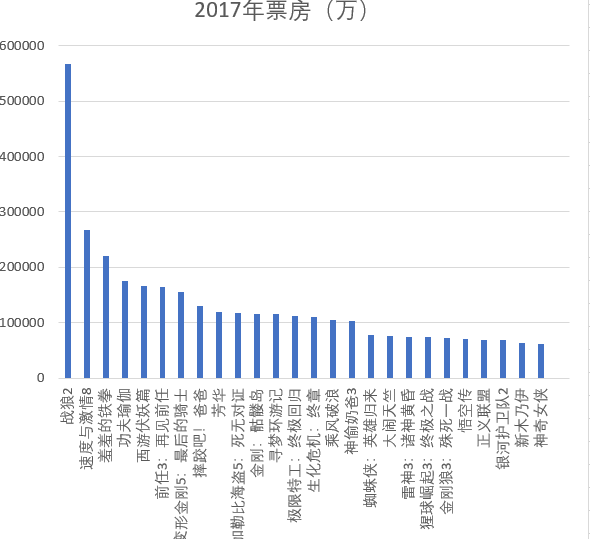
下图所示为2017年票房排名,战狼2的票房高达567875万,其余电影票房差距不大。
下图所示为2016年票房排名,其中美人鱼、疯狂动物城、魔兽排名前三。

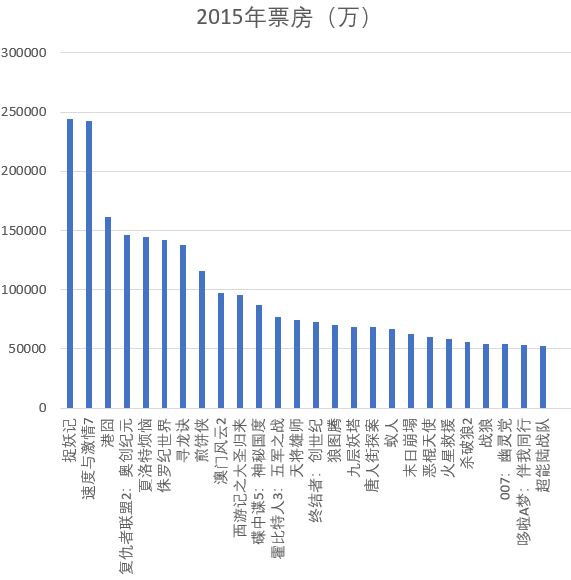
下图所示为2015年票房排名,其中捉妖记、速度与激情7、港囧排名前三。
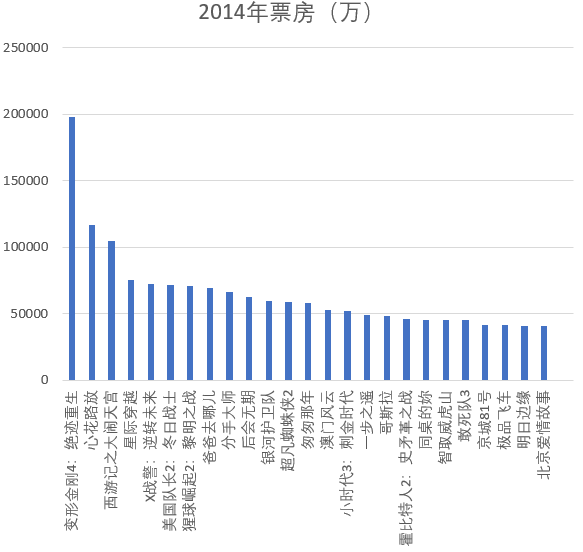
下图所示为2014年票房排名,其中变形金刚4、心花路放、西游记之大闹天宫排名前三。
下图所示为2013年票房排名,其中西游降魔篇票房位居首位,其余电影票房相差不大。

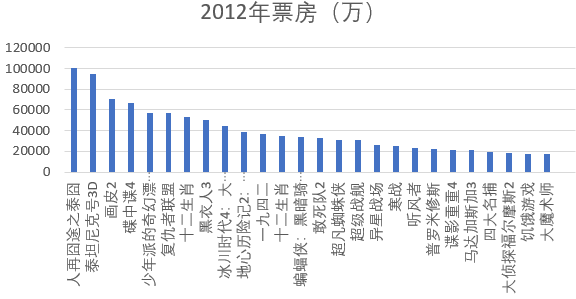
下图所示为2012年票房排名,人再囧途之泰囧、泰坦尼克号、画皮票房较高。
下图所示为2011年票房排名,变形金刚3票房最好。

下图所示为2010年票房排名,阿凡达、唐山大地震、让子弹飞排名最高。

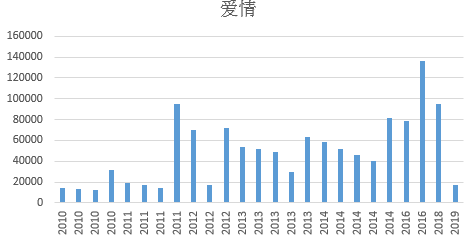
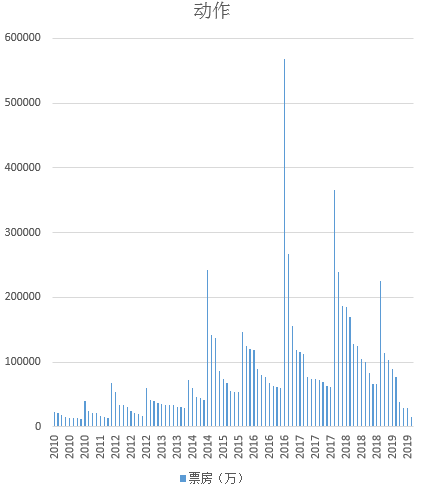
3.分析是否有一种或多种类型的电影在十年间票房震荡非常厉害
首先,我们先分别几大类型的电影进行分析,发现爱情、动作、剧情、科幻、喜剧票房起伏较大


【大数据应用技术】作业八|爬虫综合大作业Molly134的更多相关文章
- 【大数据应用期末总评】Hadoop综合大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 一.Hadoop综合大作业 要求: 1.将爬虫大作业产生的csv ...
- 大数据应用期末总评(hadoop综合大作业)
作业要求源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363 一.将爬虫大作业产生的csv文件上传到HDFS (1)在/usr ...
- 爬虫综合大作业——网易云音乐爬虫 & 数据可视化分析
作业要求来自于https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075 爬虫综合大作业 选择一个热点或者你感兴趣的主题. 选择爬取的对象 ...
- AI加持的阿里云飞天大数据平台技术揭秘
摘要:2019云栖大会大数据&AI专场,阿里云智能计算平台事业部研究员关涛.资深专家徐晟来为我们分享<AI加持的阿里云飞天大数据平台技术揭秘>.本文主要讲了三大部分,一是原创技术优 ...
- 大数据 --> 大数据关键技术
大数据关键技术 大数据环境下数据来源非常丰富且数据类型多样,存储和分析挖掘的数据量庞大,对数据展现的要求较高,并且很看重数据处理的高效性和可用性. 传统数据处理方法的不足 传统的数据采集来源单一,且存 ...
- 一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了
一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了 转载: 大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的.你可以把它 ...
- 中国大数据六大技术变迁记(CSDN)
大会召开前期,特别梳理了历届大会亮点以记录中国大数据技术领域发展历程,并立足当下生态圈现状对即将召开的BDTC 2014进行展望: 追本溯源,悉大数据六大技术变迁 伴随着大数据技术大会的发展,我们亲历 ...
- 案例分析:大数据平台技术方案及案例(ppt)
大数据平台是为了计算,现今社会所产生的越来越大的数据量,以存储.运算.展现作为目的的平台.大数据技术是指从各种各样类型的数据中,快速获得有价值信息的能力.适用于大数据的技术,包括大规模并行处理(MPP ...
- 孙荣辛|大数据穿针引线进阶必看——Google经典大数据知识
大数据技术的发展是一个非常典型的技术工程的发展过程,荣辛通过对于谷歌经典论文的盘点,希望可以帮助工程师们看到技术的探索.选择过程,以及最终历史告诉我们什么是正确的选择. 何为大数据 "大 ...
- 一起来学大数据——走进Linux之门,学习大数据的重中之重
昨天我们看了有关大数据Hadoop的一些知识点,但是要在学习大数据之前,我们还是要为大数据的环境做一些的部署. 那么,今天我们就来讲讲开启我们大数据之路的Linux,跟上我们的脚步yo~ Linux介 ...
随机推荐
- python 标准库简介
操作系统接口 os 模块提供了许多与操作系统交互的函数: >>> >>> import os >>> os.getcwd() # Return t ...
- c++ 菜单动态效果
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <ctype.h> ...
- SpringBoot中使用UEditor基本配置(图文详解)
SpringBoot中使用UEditor基本配置(图文详解) 2018年03月12日 10:52:32 BigPotR 阅读数:4497 最近因工作需要,在自己研究百度的富文本编辑器UEditor ...
- ubuntu下编译源码 make 出现 make: 'Makefile' is up to date.
其实只需要 make就行了,不需要 make Makefile 当然,make的前提是,执行 ./configure 不报错
- windows10如何将python2和python3添加到环境变量中
点击我的电脑----->右键‘属性’----->高级系统管理-------->高级-------->环境变量------>新建------->此时输入变量名和变量值 ...
- Win10版本号区分
版本号 内部版本号 UniversalApiContract 首个正式版 1507 10240 1 首个重大更新 1511 10586 2 一周年更新 Anniversary Update ...
- 黑白表格样式教师求职简历免费word模板
10款精黑白表格样式教师求职简历免费word模板,也可用于其他专业和职业,个人免费简历模板,个人简历表免费,个人简历表格. 声明:该简历模板仅用于个人欣赏使用,请勿用于商业用途,谢谢. 下载地址:百度 ...
- Kickstart Round H 2018
打了ks好久都没有更新 诶,自己的粗心真的是没救了,A题大数据都能错 A #include <iostream> #include <cstdio> #include < ...
- Spring Cloud(二):服务注册与发现 Eureka【Finchley 版】
Spring Cloud(二):服务注册与发现 Eureka[Finchley 版] 发表于 2018-04-15 | 更新于 2018-05-07 | 上一篇主要介绍了相关理论,这一篇开始我们 ...
- Spring学习(4)IOC容器配置bean:定义与实例化
一. IOC容器配置 1. 一些概念 (1)IOC容器: 定义:具有管理对象和管理对象之间的依赖关系的容器. 作用:应用程序无需自己创建对象,对象由IOC容器创建并组装.BeanFactory是IO ...