大数据应用期末总评(hadoop综合大作业)
作业要求源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363
一、将爬虫大作业产生的csv文件上传到HDFS
(1)在/usr/local路径下创建bigdatacase目录,bigdatacase下创建dataset目录,再在 windows 通过共享文件夹将爬取的census_all_data.csv文件传进 Ubuntu ,使用cp命令讲census_all_data.csv文件复制到/usr/local/bigdatacase/dataset目录下。
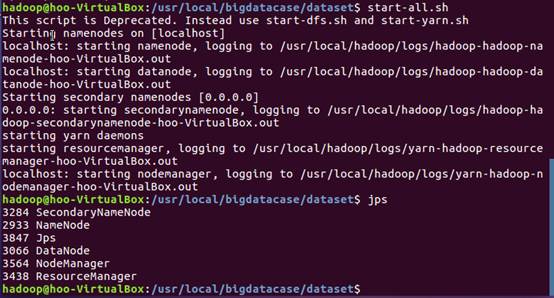
(2)启动服务并用jps命令查看服务启动情况。
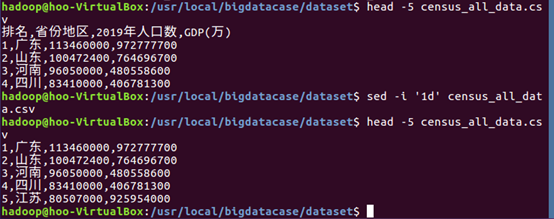
(3)查看文件前五条信息,使用sed命令去掉census_all_data.csv文件的第一行数据,再次查看文件前五条信息。
(4)创建hive目录,将census_all_data.csv文件上传到HDFS。

二、对CSV文件进行预处理生成无标题文本文件
(1)编辑pre_deal_census.sh预处理文件。

(2)pre_deal_census.sh预处理文件内容。

(3)对census_all_data.csv文件进行预处理并生成结果文件census_all_data.txt。

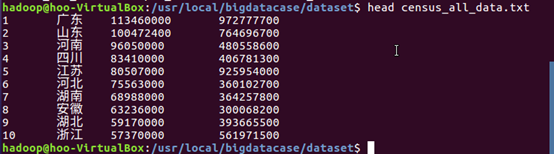
(4)查看处理结果,查看census_all_data.txt文件前十条信息。


三、把hdfs中的文本文件最终导入到数据仓库Hive中
(1)进入数据仓库 hive ,创建并使用censusdb数据库。
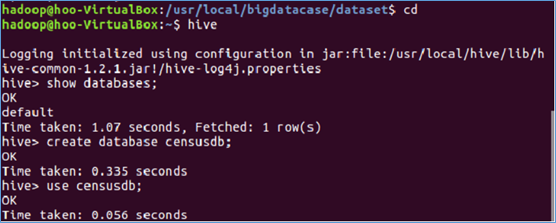
(2)创建表censustb,并为其指定census_all_data.txt文件上传路径为 /hive,将HDFS中的census_all_data.csv文件导入数据仓库hive中。

四、在Hive中查看并分析数据
(1)sql语句查询表censustb所有省份名。
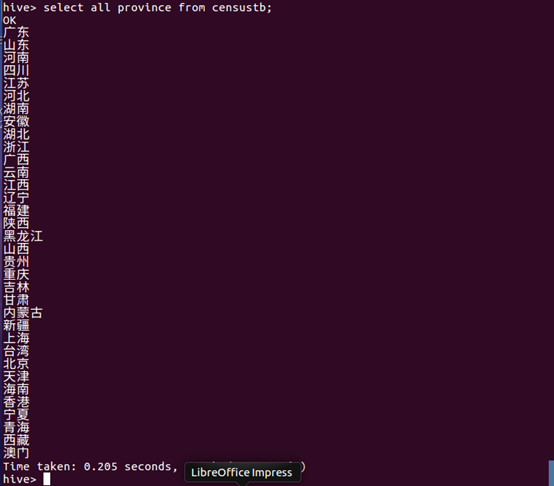
数据分析:censustb表已经按省份的人口数量从大到小排好了序,从查询结果可以看到,我国人口数量最多的省份地区是广东,人口数量最少的省份地区是澳门。
(2)sql语句查询表censustb的前10条信息。
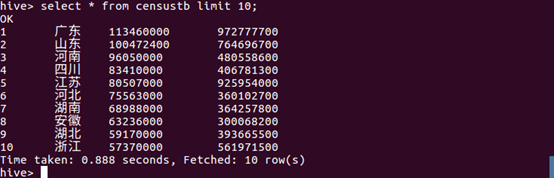
数据分析:从查询结果可知,省份的GDP值与省份的人口数量具有一定的正相关性。
(3)查询censustb表中的信息数量。
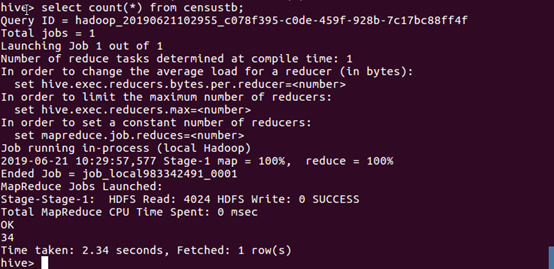
数据分析:从结果可以看出,我国共有34个省级行政区域。
(4)将censustb表排降序,并显示前十条信息中的province和GDP数据。
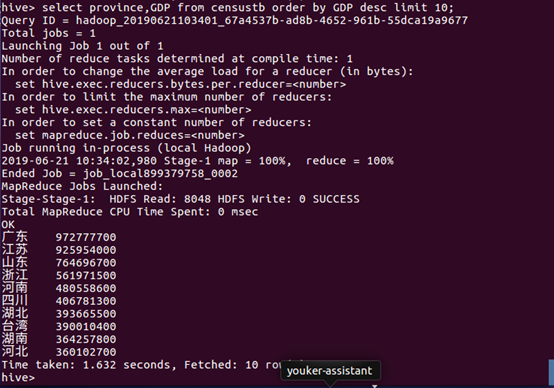
数据分析:从查询的结果可以看出,GDP值最大的省份是广东,其次是江苏,第三是山东。GDP值最大的十个省大都在沿海地区,说明GDP值与沿海的地理位置存在极大的关系。
(5)将人口数大于60000000的省份显示出来。
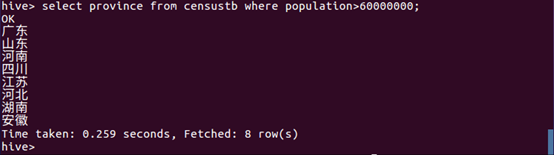
数据分析:从查询结果可以看出,广东、山东、河南、四川、江苏、河北、湖南和安徽这八个省的的人口数量已经超过六千万,结合上面的前十GDP省份可以知道:GDP越大,人数就越多。
(6)将censustb表中省份名与匹配字段相匹配的显示出来。

(7)将censustb表按人口数量排升序并将前五条数据的省份名与人口数量显示出来。
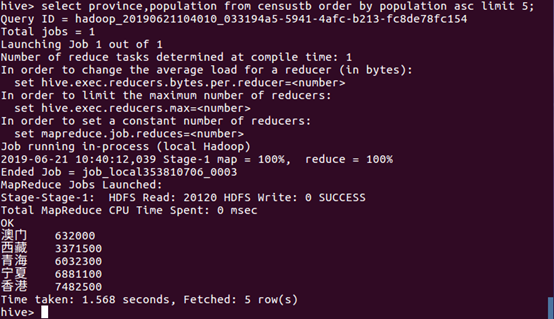
数据分析:从查询结果结果可以看出,人口数量最少的五个省份分别是香港、宁夏、青海、西藏以及澳门。
(8)使用SQL语句计算人口总数。
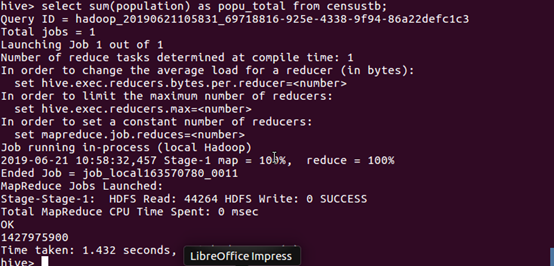
数据分析:从查询结果可以看出,2019年,我国的人口已达近 14.28 亿人,人口基数极大。
(9)显示最大的GDP值。
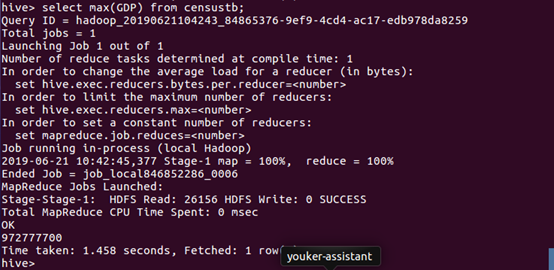
数据分析:在各省份中,最大的GDP值为 972777700 元。
(10)显示最少的人口数量。
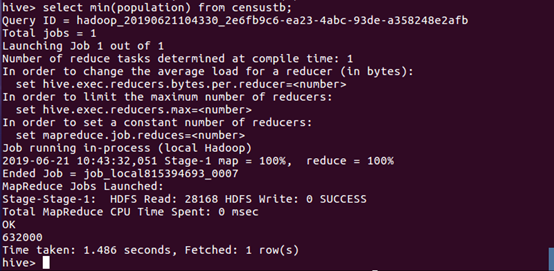
数据分析:从查询结果可知最少人口数量为632000人。
(11)使用SQL语句计算GDP总值。
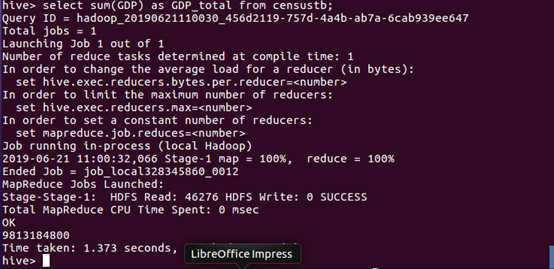
数据分析:我国GDP总值约为 98.13 亿元。
五、总结
通过对我国个省份地区的人口数量以及GDP总值数据分析,我们可以知道广东省不但是一个人口大省,还是一个国内生产总值较高的省,说明这个省的人们的生活水平比较高。我们还可以发现,我国的人口大多数都在东边沿海地区,沿海地区的经济也比内陆的地区更为发达,说明人口数量与经济呈现正相关的关系。我国的GDP生产总值(GDP)约为 98.13 亿元,虽然这个数看起来很大,但我国的人口也极多,约为14.28亿人,平均下来的GDP值也就没多少了,所以我国仍需大力发展经济。
大数据应用期末总评(hadoop综合大作业)的更多相关文章
- 大数据应用期末总评——Hadoop综合大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 Hadoop综合大作业 要求: 1.将爬虫大作业产生的csv文件 ...
- 大数据应用期末总评Hadoop综合大作业
作业要求来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 1.将爬虫大作业产生的csv文件上传到HDFS 此次作业选取的 ...
- 【大数据应用期末总评】Hadoop综合大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 一.Hadoop综合大作业 要求: 1.将爬虫大作业产生的csv ...
- Hadoop综合大作业
Hadoop综合大作业 要求: 用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计. 用Hive对爬虫大作业产生的csv文件进行数据分析 1. 用Hive对爬虫大作业产 ...
- 《Hadoop综合大作业》
作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339 我主要的爬取内容是关于热门微博文章“996”与日剧<我要 ...
- 菜鸟学IT之Hadoop综合大作业
Hadoop综合大作业 作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363 1.将爬虫大作业产生的csv文件上传到HDF ...
- Hadoop综合大作业1
本次作业来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363 一.课程评分标准: 分数组成: 考勤 10 平时作业 30 爬 ...
- 大数据平台搭建(hadoop+spark)
大数据平台搭建(hadoop+spark) 一.基本信息 1. 服务器基本信息 主机名 ip地址 安装服务 spark-master 172.16.200.81 jdk.hadoop.spark.sc ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
随机推荐
- ES6 新增集合----- Set 和Map
Sets 和数组一样,都是一些有序值的的集合,但是Sets 和数组又有所不同,首先Sets 集合中不能存有相同的值,如果你向Sets 添加重复的值,它会忽略掉, 其次Sets 集合的作用也有所不同,它 ...
- Flask第三方组件 之 Flask-Session
原生session:交由客户端保管机制,安全性相对较差,优势是一点都不占用服务器空间 Flask-Session: 解决原生session的劣势 安装包 from flask import Flask ...
- java-springCloud环境配置
SpringCloud注解和配置以及pom依赖说明 https://www.cnblogs.com/zhuwenjoyce/p/9663324.html https://blog.csdn.net/s ...
- nginx反向代理前后端分离项目(后端多台)
目前软件架构都比较流行前后端分离,前后端的分离也实现了前后端架构的分离,带来的好处 —— 整个项目的开发权重往前移,实现真正的前后端解耦,动态资源和静态资源分离,提高了性能和扩展性. 通常Spring ...
- PHP微信商户支付企业付款到零钱功能
一 开通条件,就是首先要在微信平台设置好. 以下微信文档里有的,我这里大概掠几项比较重要的. 付款资金 企业付款到零钱资金使用商户号余额资金. 根据商户号的账户开通情况,实际出款账户有做区别: ◆ 默 ...
- 19,flask消息闪现-flash
Flash消息 请求完成后给用户的提醒消息,flask的核心特性, flash函数实现效果 视图函数中调用flash()方法 html中要使用get_flashed_messages() 后端代码: ...
- 云计算与大数据实验:Hbase shell终端操作之数据操作一
[实验目的] 1)学会向表中添加记录 2)学会添加记录时动态添加列 3)学会查看一条记录 4)学会查看表中的记录总数 5)学会删除记录 [实验原理] Hbase shell作为Hbase数据的客户端, ...
- JSON的Go解析
JSON(Javascript Object Notation)是一种轻量级的数据交换语言,以文字为基础,具有自我描述性且易于让人阅读.尽管JSON是Javascript的一个子集,但JSON是独立于 ...
- APP测试之MONKEY安装、使用
1.先下载java的jdk;配置java变量 安装好之后会有两个文件夹一个是jdk 一个是jre(运行)然后配置好java环境变量:JAVA_HOME:C:\Program Files\Java\jd ...
- pytho模块的加载顺序
当前目录如果有同名的系统模块,那么当前目录的模块会被import,系统模块会被忽略,如: 1 ghostwu@ghostwu:~/python/module$ ls 2 import_test.py ...