Zeppelin使用spark解释器
Zeppelin为0.5.6
Zeppelin默认自带本地spark,可以不依赖任何集群,下载bin包,解压安装就可以使用。
使用其他的spark集群在yarn模式下。
配置:
vi zeppelin-env.sh

添加:
export SPARK_HOME=/usr/crh/current/spark-client
export SPARK_SUBMIT_OPTIONS="--driver-memory 512M --executor-memory 1G"
export HADOOP_CONF_DIR=/etc/hadoop/conf
Zeppelin Interpreter配置

注意:设置完重启解释器。
Properties的master属性如下:

新建Notebook
Tips:几个月前zeppelin还是0.5.6,现在最新0.6.2,zeppelin 0.5.6写notebook时前面必须加%spark,而0.6.2若什么也不加就默认是scala语言。
zeppelin 0.5.6不加就报如下错:
Connect to 'databank:4300' failed
%spark.sql
select count(*) from tc.gjl_test0
报错:
com.fasterxml.jackson.databind.JsonMappingException: Could not find creator property with name 'id' (in class org.apache.spark.rdd.RDDOperationScope)
at [Source: {"id":"2","name":"ConvertToSafe"}; line: 1, column: 1]
at com.fasterxml.jackson.databind.JsonMappingException.from(JsonMappingException.java:148)
at com.fasterxml.jackson.databind.DeserializationContext.mappingException(DeserializationContext.java:843)
at com.fasterxml.jackson.databind.deser.BeanDeserializerFactory.addBeanProps(BeanDeserializerFactory.java:533)
at com.fasterxml.jackson.databind.deser.BeanDeserializerFactory.buildBeanDeserializer(BeanDeserializerFactory.java:220)
at com.fasterxml.jackson.databind.deser.BeanDeserializerFactory.createBeanDeserializer(BeanDeserializerFactory.java:143)
at com.fasterxml.jackson.databind.deser.DeserializerCache._createDeserializer2(DeserializerCache.java:409)
at com.fasterxml.jackson.databind.deser.DeserializerCache._createDeserializer(DeserializerCache.java:358)
at com.fasterxml.jackson.databind.deser.DeserializerCache._createAndCache2(DeserializerCache.java:265)
at com.fasterxml.jackson.databind.deser.DeserializerCache._createAndCacheValueDeserializer(DeserializerCache.java:245)
at com.fasterxml.jackson.databind.deser.DeserializerCache.findValueDeserializer(DeserializerCache.java:143)
at com.fasterxml.jackson.databind.DeserializationContext.findRootValueDeserializer(DeserializationContext.java:439)
at com.fasterxml.jackson.databind.ObjectMapper._findRootDeserializer(ObjectMapper.java:3666)
at com.fasterxml.jackson.databind.ObjectMapper._readMapAndClose(ObjectMapper.java:3558)
at com.fasterxml.jackson.databind.ObjectMapper.readValue(ObjectMapper.java:2578)
at org.apache.spark.rdd.RDDOperationScope$.fromJson(RDDOperationScope.scala:85)
at org.apache.spark.rdd.RDDOperationScope$$anonfun$5.apply(RDDOperationScope.scala:136)
at org.apache.spark.rdd.RDDOperationScope$$anonfun$5.apply(RDDOperationScope.scala:136)
at scala.Option.map(Option.scala:145)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:136)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:130)
at org.apache.spark.sql.execution.ConvertToSafe.doExecute(rowFormatConverters.scala:56)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$5.apply(SparkPlan.scala:132)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$5.apply(SparkPlan.scala:130)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:150)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:130)
at org.apache.spark.sql.execution.SparkPlan.executeTake(SparkPlan.scala:187)
at org.apache.spark.sql.execution.Limit.executeCollect(basicOperators.scala:165)
at org.apache.spark.sql.execution.SparkPlan.executeCollectPublic(SparkPlan.scala:174)
at org.apache.spark.sql.DataFrame$$anonfun$org$apache$spark$sql$DataFrame$$execute$1$1.apply(DataFrame.scala:1499)
at org.apache.spark.sql.DataFrame$$anonfun$org$apache$spark$sql$DataFrame$$execute$1$1.apply(DataFrame.scala:1499)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:56)
at org.apache.spark.sql.DataFrame.withNewExecutionId(DataFrame.scala:2086)
at org.apache.spark.sql.DataFrame.org$apache$spark$sql$DataFrame$$execute$1(DataFrame.scala:1498)
at org.apache.spark.sql.DataFrame.org$apache$spark$sql$DataFrame$$collect(DataFrame.scala:1505)
at org.apache.spark.sql.DataFrame$$anonfun$head$1.apply(DataFrame.scala:1375)
at org.apache.spark.sql.DataFrame$$anonfun$head$1.apply(DataFrame.scala:1374)
at org.apache.spark.sql.DataFrame.withCallback(DataFrame.scala:2099)
at org.apache.spark.sql.DataFrame.head(DataFrame.scala:1374)
at org.apache.spark.sql.DataFrame.take(DataFrame.scala:1456)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.zeppelin.spark.ZeppelinContext.showDF(ZeppelinContext.java:297)
at org.apache.zeppelin.spark.SparkSqlInterpreter.interpret(SparkSqlInterpreter.java:144)
at org.apache.zeppelin.interpreter.ClassloaderInterpreter.interpret(ClassloaderInterpreter.java:57)
at org.apache.zeppelin.interpreter.LazyOpenInterpreter.interpret(LazyOpenInterpreter.java:93)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer$InterpretJob.jobRun(RemoteInterpreterServer.java:300)
at org.apache.zeppelin.scheduler.Job.run(Job.java:169)
at org.apache.zeppelin.scheduler.FIFOScheduler$1.run(FIFOScheduler.java:134)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:178)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:292)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
原因:
进入/opt/zeppelin-0.5.6-incubating-bin-all目录下:
# ls lib |grep jackson
jackson-annotations-2.5.0.jar
jackson-core-2.5.3.jar
jackson-databind-2.5.3.jar
将里面的版本换成如下版本:
# ls lib |grep jackson
jackson-annotations-2.4.4.jar
jackson-core-2.4.4.jar
jackson-databind-2.4.4.jar
测试成功!
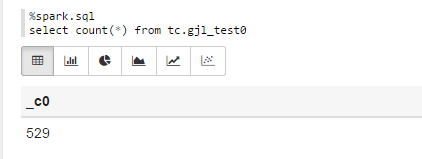
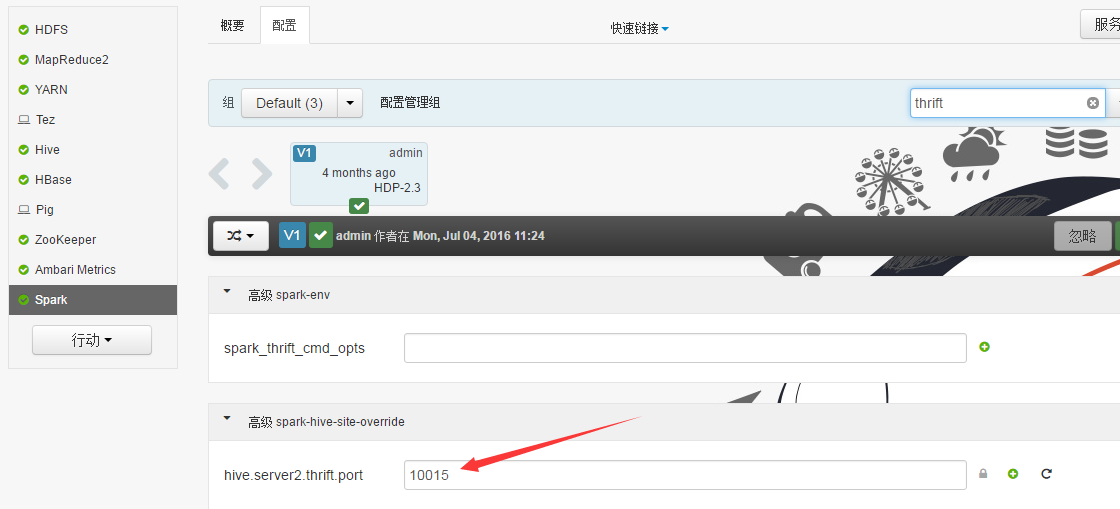
Sparksql也可直接通过hive jdbc连接,只需换端口,如下图:

Zeppelin使用spark解释器的更多相关文章
- Zeppelin使用Spark的yarn-client模式
Zeppelin版本0.6.2 1. Export SPARK_HOME In conf/zeppelin-env.sh, export SPARK_HOME environment variable ...
- Zeppelin0.5.6使用spark解释器
Zeppelin为0.5.6 Zeppelin默认自带本地spark,可以不依赖任何集群,下载bin包,解压安装就可以使用. 使用其他的spark集群在yarn模式下. 配置: vi zeppelin ...
- Zeppelin添加mysql解释器
安装Apache zeppelin 1 wget http://apache.fayea.com/zeppelin/zeppelin-0.6.2/zeppelin-0.6.2-bin-all.tgz ...
- Zeppelin使用phoenix解释器
Interpreters设置
- Zeppelin 0.6.2使用Spark的yarn-client模式
Zeppelin版本0.6.2 1. Export SPARK_HOME In conf/zeppelin-env.sh, export SPARK_HOME environment variable ...
- Spark实战2:Zeppelin的安装和SparkSQL使用总结
zeppelin是spark的web版本notebook编辑器,相当于ipython的notebook编辑器. 一Zeppelin安装 (前提是spark已经安装好) 1 下载https://zepp ...
- Ubuntu下基于Saprk安装Zeppelin
前言 Apache Zeppelin是一款基于web的notebook(类似于ipython的notebook),支持交互式地数据分析,即一个Web笔记形式的交互式数据查询分析工具,可以在线用scal ...
- Zeppelin原理简介
Zeppelin是一个基于Web的notebook,提供交互数据分析和可视化.后台支持接入多种数据处理引擎,如spark,hive等.支持多种语言: Scala(Apache Spark).Pytho ...
- Spark in meituan http://tech.meituan.com/spark-in-meituan.html
Spark在美团的实践 忽略元数据末尾 回到原数据开始处 引言:Spark美团系列终于凑成三部曲了,Spark很强大应用很广泛, 文中Spark交互式开发平台和作业ETL模板的设计都很有启发借鉴意义. ...
随机推荐
- 标准I/O 缓存
标准I/O提供了三种类型的缓存: (1)全缓存.在这种情况下,当填满标准I/O 缓存后才进行实际 I/O 操作.对于驻在磁盘上的文件通常是由标准I/O库实施全缓存的.在一个流上执行第一次I/O操作时, ...
- SQL总结之导入导出
(5)还原数据库[倒库] [数据泵模式]先要在D盘创建个目录,如D:/dbback 然后去plsql中创建目录sql命令:create directory dbback as 'D:\dbback'; ...
- tomcat的自我理解与使用心得
当一个动态动态网页编写完成后是不能直接被别人通过浏览器访问的,要想访问此动态网页就必须让浏览器通过一段程序来访问此网页,这段程序就是服务器,他用来接受浏览器的请求,进行处理,将结果返回给浏览器. to ...
- 5.MyBaits调用存储过程
1.创建一个javaweb项目MyBatis_Part4_Procedure 2.在src下创建procedure.sql文件 --创建表 create table p_user( id number ...
- javabean+servlet+jsp实现分页
前端实现用ligerUI实现分页,感觉用框架确实简单,闲着无聊,模拟着liger的分页界面实现了一遍(只要是功能,样式什么无视) 这里用基础的三层架构+servlet+jsp实现,思路很简单,把所有分 ...
- 面试题-Java Web-Servlet部分
1.什么是Servlet? Servlet是用来处理客户端请求并产生动态网页内容的Java类.Servlet主要是用来处理或者是存储HTML表单提交的数据,产生动态内容,在无状态的HTTP协议下管理状 ...
- Dojo的UI框架bootstrap for dojo和Dojo-Bootstrap简介
最近在学习Dojo,但样式问题真是头疼呀,虽然清新的淡蓝色很是减缓眼睛的疲劳,但这个扁平化简约风盛行的年代,光是清新的拟物已经满足不了群众的需求了,所以就在这样的需求下,我知道了bootstrap f ...
- QCMediaPlayer mediaplayer NOT present(android)
出现了“QCMediaPlayer mediaplayer NOT present”这个错误!!!我的手机是小米手机2,我给它刷机刷到了Android 4.4.4,后来我学长是这样解决的:case R ...
- React添加自定义属性
使用‘data-’前缀即可,代码举例 render(){ return ( <ul className={css.forUl}> { this.props.todo.map(functio ...
- hibernate简单的增删改查
获取当前线程的session protected Session getSession() { return sessionFactory.getCurrentSession(); } 增加:save ...