Zeppelin原理简介
Zeppelin是一个基于Web的notebook,提供交互数据分析和可视化。后台支持接入多种数据处理引擎,如spark,hive等。支持多种语言: Scala(Apache Spark)、Python(Apache Spark)、SparkSQL、 Hive、 Markdown、Shell等。本文主要介绍Zeppelin中Interpreter和SparkInterpreter的实现原理。
转载请注明
http://www.cnblogs.com/shenh062326/p/6195064.html
安装与使用
参考http://blog.csdn.net/jasonding1354/article/details/46822391
原理简介
Interpreter
Zeppelin中最核心的概念是Interpreter,interpreter是一个插件允许用户使用一个指定的语言或数据处理器。每一个Interpreter都属于换一个InterpreterGroup,同一个InterpreterGroup的Interpreters可以相互引用,例如SparkSqlInterpreter 可以引用 SparkInterpreter 以获取 SparkContext,因为他们属于同一个InterpreterGroup。当前已经实现的Interpreter有spark解释器,python解释器,SparkSQL解释器,JDBC,Markdown和shell等。下图是Zeppelin官网中介绍Interpreter的原理图。
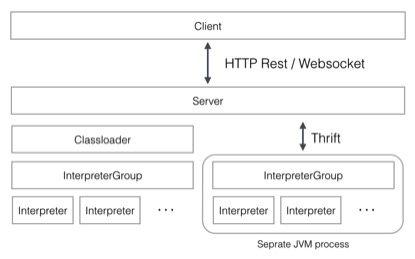
Interpreter接口中最重要的方法是open,close,interpert三个方法,另外还有cancel,gerProgress,completion等方法。
Open 是初始化部分,只会调用一次。
Close 是关闭释放资源的接口,只会调用一次。
Interpret 会运行一段代码并返回结果,同步执行方式。
Cancel可选的接口,用于结束interpret方法
getPregress 方法获取interpret的百分比进度
completion 基于游标位置获取结束列表,实现这个接口可以实现自动结束
SparkInterpreter
Open方法中,会初始化SparkContext,SQLContext,ZeppelinContext;当前支持的模式有:
• local[*] in local mode
• spark://master:7077 in standalone cluster
• yarn-client in Yarn client mode
• mesos://host:5050 in Mesos cluster
其中Yarn集群只支持client模式。
if (isYarnMode()) {
conf.set("master", "yarn");
conf.set("spark.submit.deployMode", "client");
}
Interpret方法中会执行一行代码(以\n分割),其实会调用spark 的SparkILoop一行一行的执行(类似于spark shell的实现),这里的一行是逻辑行,如果下一行代码中以“.”开头(非“..”,“./”),也会和本行一起执行。关键代码如下:
scala.tools.nsc.interpreter.Results.Result res = null;
try {
res = interpret(incomplete + s);
} catch (Exception e) {
sc.clearJobGroup();
out.setInterpreterOutput(null);
logger.info("Interpreter exception", e);
return new InterpreterResult(Code.ERROR, InterpreterUtils.getMostRelevantMessage(e));
}
r = getResultCode(res);
sparkInterpret的关键方法:
close 方法会停止SparkContext
cancel 方法直接调用SparkContext的cancel方法。sc.cancelJobGroup(getJobGroup(context)
getProgress 通过SparkContext获取所有stage的总的task和已经结束的task,结束的tasks除以总的task得到的比例就是进度。
问题1,是否可以存在多个SparkContext?
Interpreter支持'shared', 'scoped', 'isolated'三种选项,在scopde模式下,spark interpreter为每个notebook创建编译器但只有一个SparkContext;isolated模式下会为每个notebook创建一个单独的SparkContext。
问题2,isolated模式下,多个SparkContext是否在同一个进程中?
一个服务端启动多个spark Interpreter后,会启动多个SparkContext。不过可以用另外一个jvm启动spark Interpreter。
Zeppelin优缺点小结
优点
1.提供restful和webSocket两种接口。
2.使用spark解释器,用户按照spark提供的接口编程即可,用户可以自己操作SparkContext,不过用户3.不能自己去stop SparkContext;SparkContext可以常驻。
4.包含更多的解释器,扩展性也很好,可以方便增加自己的解释器。
5.提供了多个数据可视化模块,数据展示方便。
缺点
1.没有提供jar包的方式运行spark任务。
2.只有同步的方式运行,客户端可能需要等待较长时间。
Zeppelin原理简介的更多相关文章
- storm 原理简介及单机版安装指南——详细版【转】
storm 原理简介及单机版安装指南 本文翻译自: https://github.com/nathanmarz/storm/wiki/Tutorial 原文链接自:http://www.open-op ...
- Java进阶(二十四)Java List集合add与set方法原理简介
Java List集合add与set方法原理简介 add方法 add方法用于向集合列表中添加对象. 语法1 用于在列表的尾部插入指定元素.如果List集合对象由于调用add方法而发生更改,则返回 tr ...
- kafka原理简介并且与RabbitMQ的选择
kafka原理简介并且与RabbitMQ的选择 kafka原理简介,rabbitMQ介绍,大致说一下区别 Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和 ...
- InheritableThreadLocal类原理简介使用 父子线程传递数据详解 多线程中篇(十八)
上一篇文章中对ThreadLocal进行了详尽的介绍,另外还有一个类: InheritableThreadLocal 他是ThreadLocal的子类,那么这个类又有什么作用呢? 测试代码 p ...
- Nginx 负载均衡原理简介与负载均衡配置详解
Nginx负载均衡原理简介与负载均衡配置详解 by:授客 QQ:1033553122 测试环境 nginx-1.10.0 负载均衡原理 客户端向反向代理发送请求,接着反向代理根据某种负载机制 ...
- Nginx 反向代理工作原理简介与配置详解
Nginx反向代理工作原理简介与配置详解 by:授客 QQ:1033553122 测试环境 CentOS 6.5-x86_64 nginx-1.10.0 下载地址:http://nginx. ...
- Linux DNS原理简介及配置
Linux DNS原理简介及配置 DNS简介 DNS原理 域名解析的过程 资源记录 DNS BIND安装配置 一.简介 一般来讲域名比IP地址更加的有含义.也更容易记住,所以通常用户更习惯输入域名来访 ...
- Oracle Golden Gate原理简介
Oracle Golden Gate原理简介 http://www.askoracle.org/oracle/HighAvailability/20140109953.html#6545406-tsi ...
- Linux SSH基于密钥交换的自动登陆原理简介及配置说明
一.原理简介 SSH证书认证登录的基础是一对唯一匹配密钥: 私钥(private key)和公钥(public key).公钥用于对数据进行加密,而且只能用于加密.而私钥只能对使用所匹配的公钥,所加密 ...
随机推荐
- 【SQL SERVER】触发器(一)
下面是个人对触发器知识的整理,触发器其实很简单,但想要编写发杂的触发器操作还是需要一定的SQL语句编写,触发器主要用于SQL SERVER约束.默认值和规则的完整性检查,还可以实现由主键和外键不能保证 ...
- Docker —几个概念的理解
本文从一种使用场景来引出docker,并讨论了什么是镜像,容器,仓库,以及docker的相关概念. 试想一种使用场景: 我的wordpress 博客网站现在部署在阿里云服务器上,但是在后期的使用中我有 ...
- 洛谷P3919 【模板】可持久化数组 [主席树]
题目传送门 可持久化数组 题目描述 如题,你需要维护这样的一个长度为 $N$ 的数组,支持如下几种操作 在某个历史版本上修改某一个位置上的值 访问某个历史版本上的某一位置的值 此外,每进行一次操作(对 ...
- 【记录】mybatis-generator如何使用(maven方式)
1.首先在pom.xml中添加插件 <plugin> <groupId>org.mybatis.generator</groupId> <artifactId ...
- U2随笔
Html 结构化 CSS 样式 JavaScript 行为交互 1.JavaScript基础 2.JavaScript操作BOM对象 3.JavaScript操作DOM对象***** 4.JavaSc ...
- hdu 1253
D - 胜利大逃亡 Time Limit:2000MS Memory Limit:32768KB 64bit IO Format:%I64d & %I64u Submit St ...
- 【最小割】BZOJ3894-文理分科
[题目大意] 给定一个m*n的矩阵,每个格子的人可以学文或者学理,学文和学理各有一个满意度,如果以某人为中心的十字内所有人都学文或者学理还会得到一个额外满意度,求最大满意度之和. [思路] 发现这道题 ...
- Java 基础总结--反射的基本操作
一.反射的概念 JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法:对于任意一个对象,都能够调用它的任意一个方法和属性:这种动态获取的信息以及动态调用对象的方法的功能称为 ...
- JDK源码(1.7) -- java.util.Iterator<E>
java.util.Iterator<E> 源码分析(JDK1.7) ----------------------------------------------------------- ...
- [转] Android 命名规范 (提高代码可以读性)
Android命名规范编码习惯 刚接触android的时候,命名都是按照拼音来,所以有的时候想看懂命名的那个控件什么是什么用的,就要读一遍甚至好几遍才知道,这样的话,在代码的 审查和修改过程中就会浪费 ...