大数据系列之Hadoop分布式集群部署
本节目的:搭建Hadoop分布式集群环境
- 环境准备
- LZ用OS X系统 ,安装两台Linux虚拟机,Linux系统用的是CentOS6.5;Master Ip:10.211.55.3 ,Slave Ip:10.211.55.4
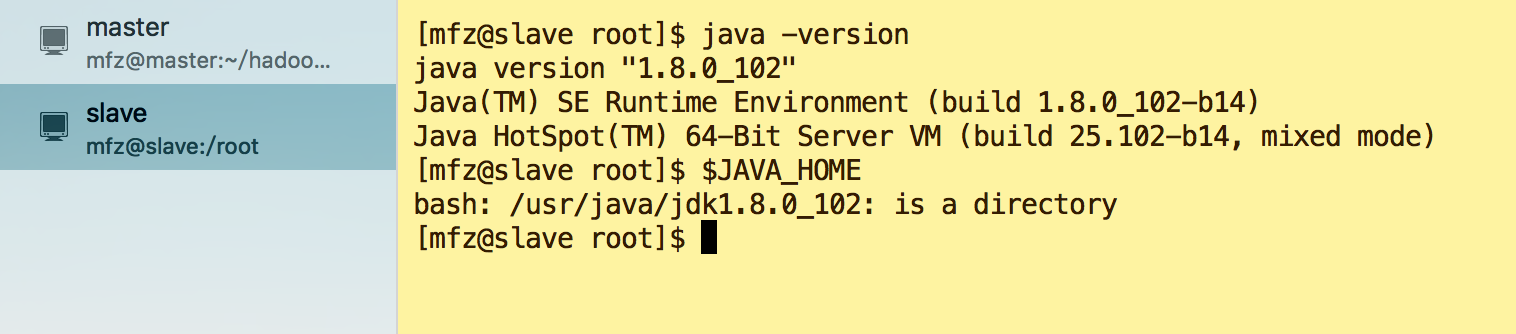
- 各虚拟机环境配置好Jdk1.8(1.7+即可)

- 资料准备
- hadoop-2.7.3.tar.gz
- 虚拟机配置步骤
- 以下操作都在两台虚拟机 root用户下操作,切换至root用户命令
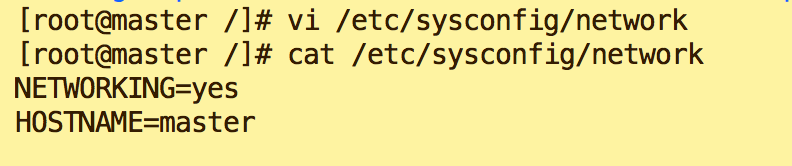
- 配置Master hostname 为Master ;
vi /etc/sysconfig/network
- 生效hostname
hostname master
检测主机名是否修改成功命令如下,在操作之前需要关闭当前终端,重新打开一个终端:即可看到终端命令前是[user@hostname]
- 按照步骤6+7 配置Slave hostname 为 Slave;
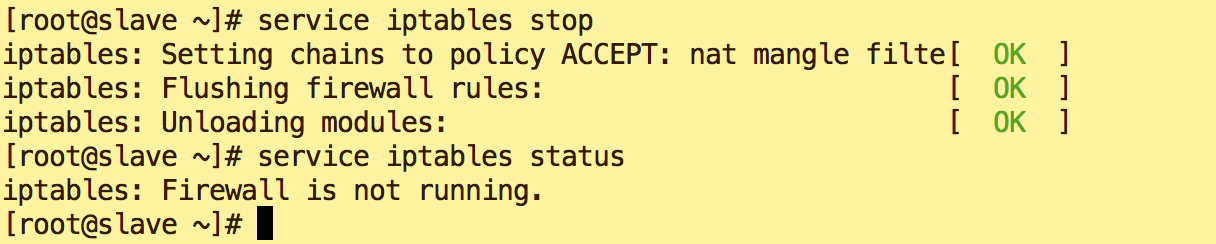
- 关闭Slave防火墙
service iptables stop
- 各虚拟机配置hosts列表,
vi /etc/hosts
添加内容(LZ master Ip是10.211.55.3,Salve Ip 是10.211.55.4)

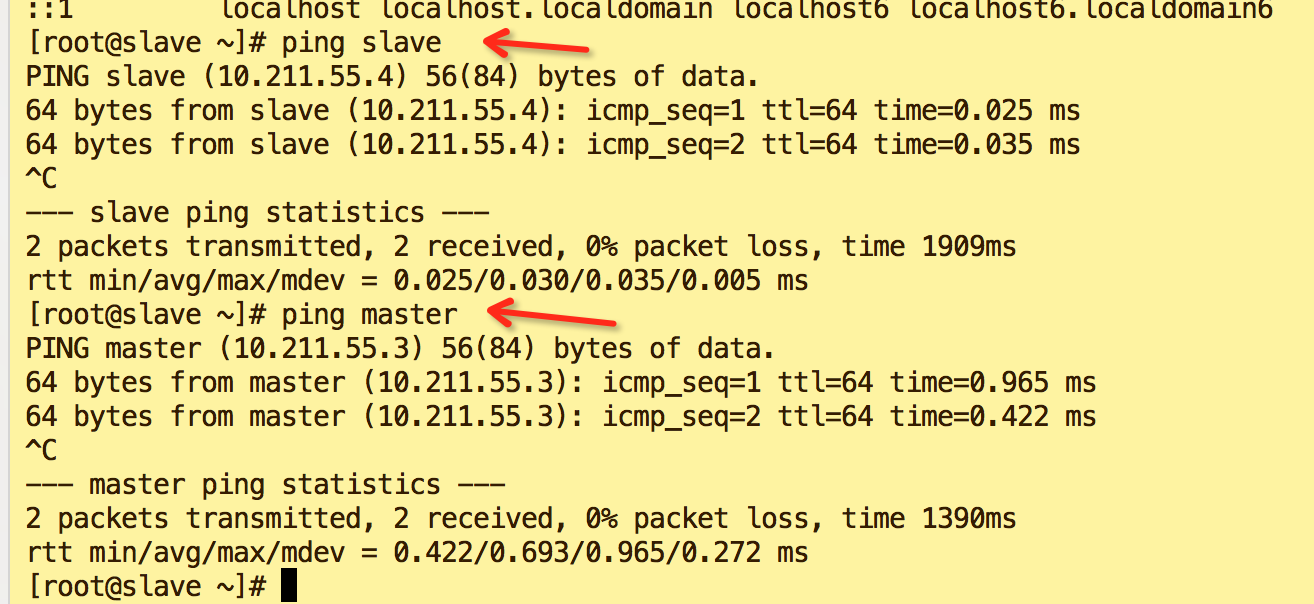
- 验证
ping slave
ping master如图表示修改成功
- 免密钥登录配置(此部分操作均在用户mfz下操作,切换至用户:su mfz)
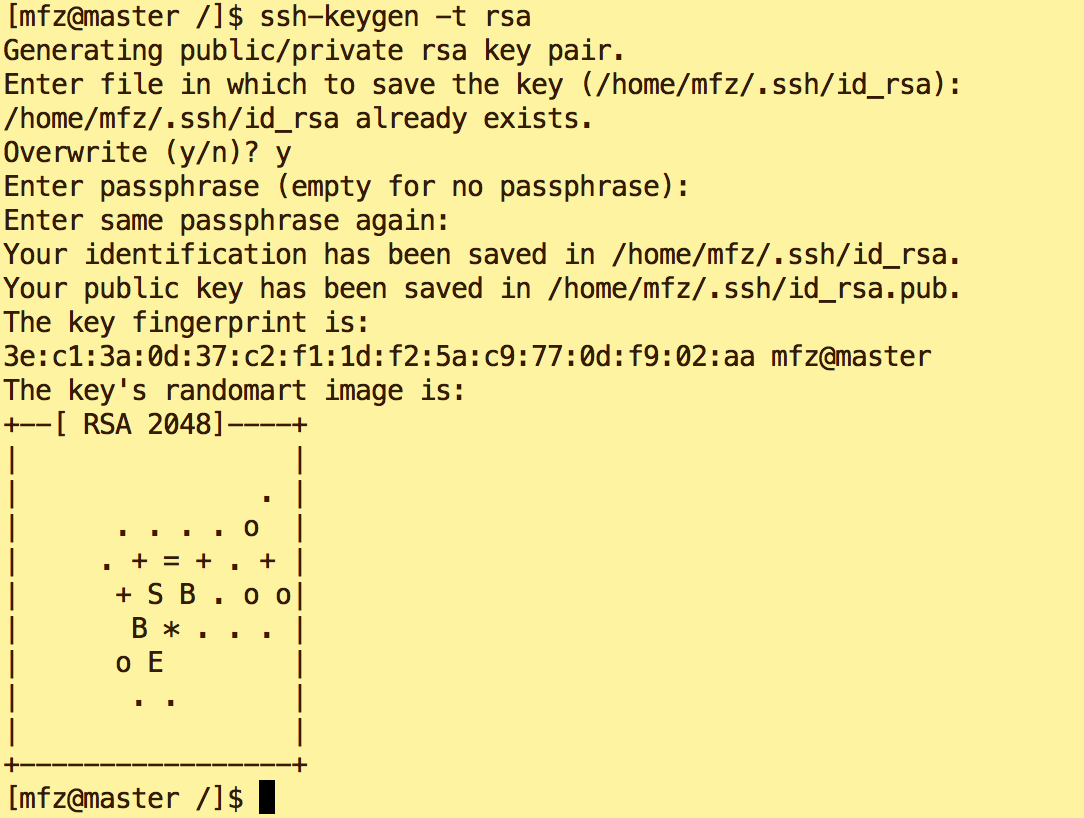
- Master节点上操作:
ssh-keygen -t rsa (多次回车(Enter)即可)
复制公钥文件
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
执行 ll查看

修改authorized_keys文件的权限,命令如下:
chmod ~/.ssh/authorized_keys (执行后文件权限为 -rw------- )
将authorized_keys文件复制到slave节点,命令如下:
scp ~/.ssh/authorized_keys mfz@slave:~/ (如果提示输入yes/no的时候,输入yes,回车密码是mfz slave登录密码)
- slave节点上操作
- 在终端生成密钥,命令如下(一路点击回车生成密钥)
ssh-keygen -t rsa
将authorized_keys文件移动到.ssh目录
mv authorized_keys ~/.ssh/
- 修改authorized_keys文件的权限,命令如下:
cd ~/.ssh
chmod authorized_keys - 验证免密钥登录 ,在master节点上执行命令如下
ssh slave
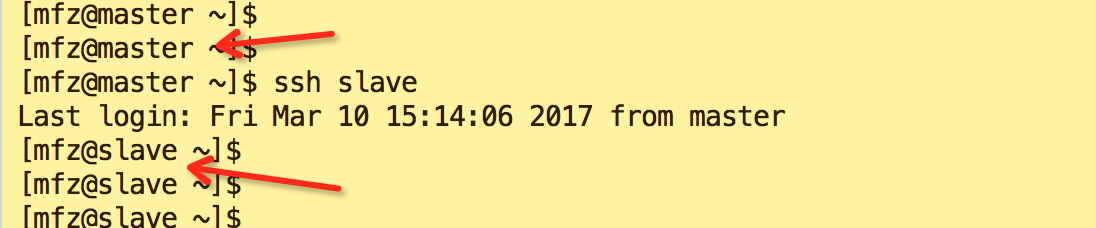 如果还提示输入slave登录密码则配置出错。检查步骤。
如果还提示输入slave登录密码则配置出错。检查步骤。
- Master节点上操作:
- Hadoop配置
每个节点上的Hadoop配置基本相同,在HadoopMaster节点操作,然后完成复制到另一个节点。下面所有的操作都使用mfz用户,切换mfz用户的命令是:su mfz
- 资源包上传到 /home/mfz/resources/下
-
- 执行命令,最后如果显示目录如下图则表示操作成功
cp /home/mfz/resources/hadoop-2.7..tar.gz /home/mfz/
cd /home/mfz
tar -xzvf hadoop-2.7..tar.gz
ll hadoop-2.7.
- 修改配置环境变量hadoop-env.sh 环境变量
vi /home/mfz/hadoop-2.7./etc/hadoop/hadoop-env.sh

配置hdfs-site.xml,添加\替换 如下
<configuration>
<property>
<name>dfs.replication</name>
<value></value>
</property>
</configuration>- 配置core-site.xml ,添加\替换 如下
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/mfz/hadoopdata</value>
<description>A base for other temporary directories.</description>
</property>
</configuration> - 修改yarn-env.sh 环境变量
vi yarn-env.sh

- 配置yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:</value>
</property>
</configuration> 配置计算框架mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xm --添加/替换 如下 <configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>- 修改slaves文件,插入slave 节点hostname (可配置多个slave)
vi /home/mfz/hadoop-2.7./etc/hadoop/slaves
cat /home/mfz/hadoop-2.7./etc/hadoop/slaves
复制到从节点(使用下面的命令将已经配置完成的Hadoop复制到从节点HadoopSlave上) (可复制到多个slave)
cd
scp -r hadoop-2.7. slave:~/ --注意:因为之前已经配置了免密钥登录,这里可以直接远程复制。
- 运行验证-启动Hadoop集群
- 该节的配置需要同时在两个节点(HadoopMaster和HadoopSlave)上进行操作
- 操作命令如下:(LZ 环境变量统一放在了/etc/profile 下,也可放于单个用户~/.base_profile 下)
cd
vi /etc/profile 添加如下内容 #HADOOP
export HADOOP_HOME=/home/mfz/hadoop-2.7.
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH 生效配置
source /etc/profile 创建数据目录(该节的配置需要同时在两个节点(HadoopMaster和HadoopSlave)上进行操作。)
cd
mkdir hadoopdata
说明:(在用户mfz主目录下操作,此hadoopData目录是hadoop-2.7.3/etc/hadoop/core-site.xml 中hadoop.tmp.dir 的 value)- 格式化文件系统 ---格式化命令如下,该操作需要在HadoopMaster节点上执行:
hdfs namenode -format
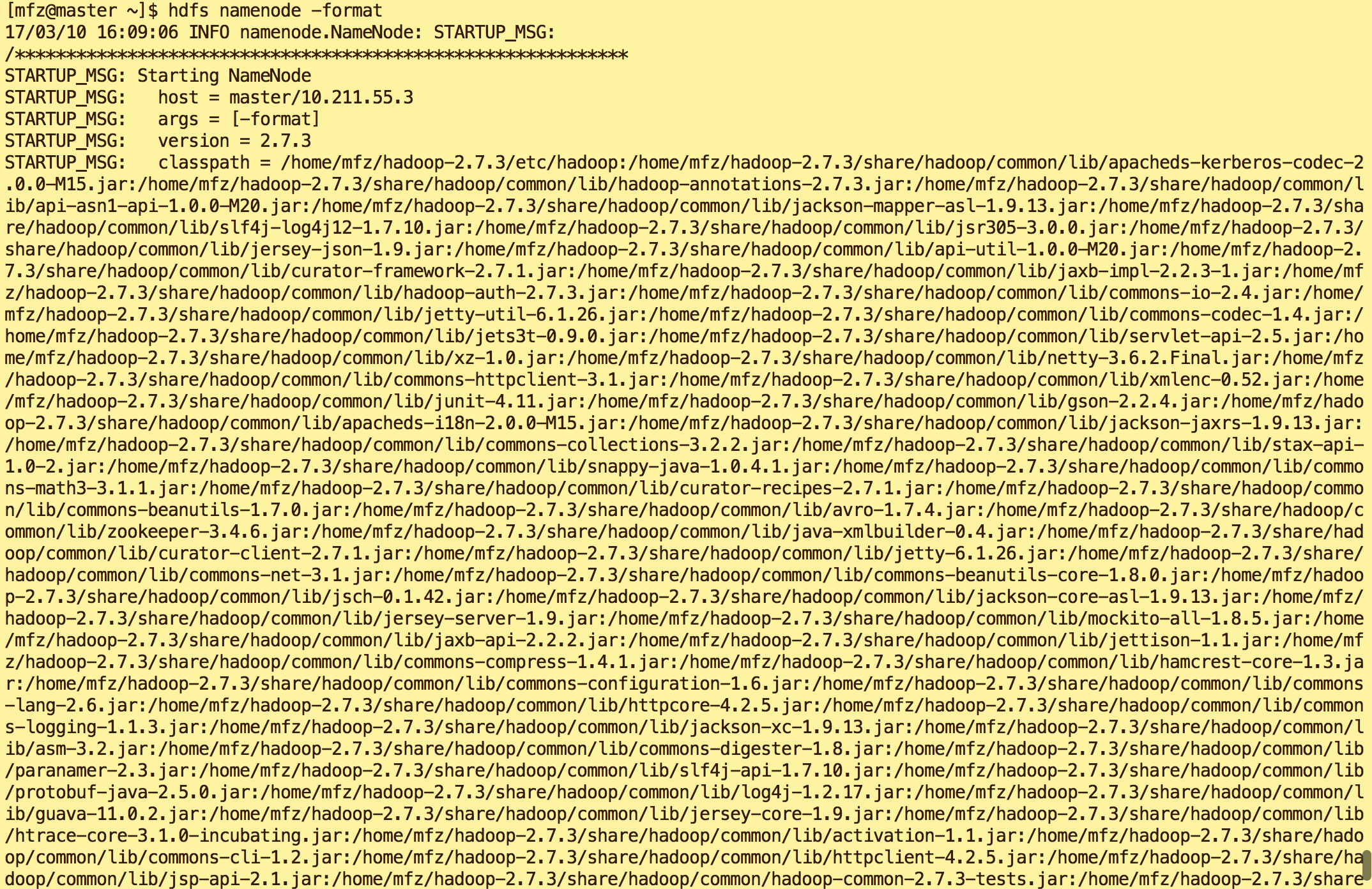
- 如果出现ERROR/Exception 则表示出现问题了。自行百度解决。。。
- Master节点上启动hadoop 集群
cd /home/mfz/hadoop-2.7./ sbin/start-all.sh
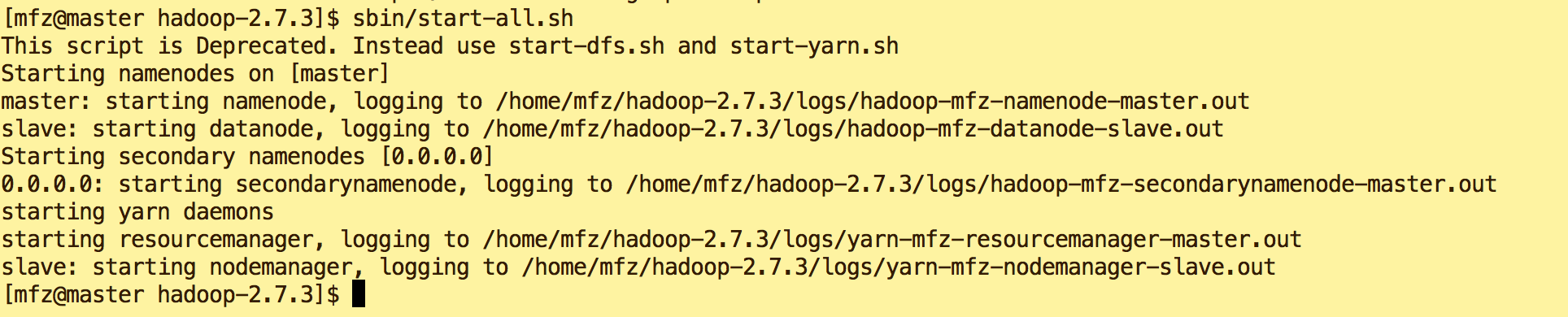
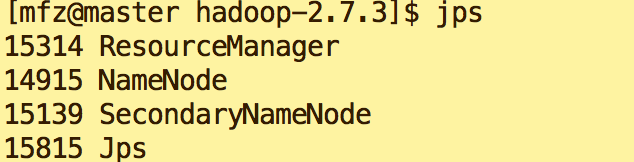
在master的终端执行jps命令,在打印结果中会看到4个进程,分别是ResourceManager、Jps、NameNode和SecondaryNameNode,如下图所示。如果出现了这4个进程表示主节点进程启动成功。
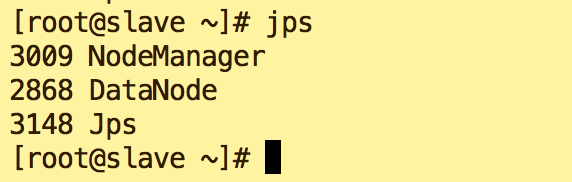
在slave的终端执行jps命令,在打印结果中会看到3个进程,分别是NodeManager、DataNode和Jps,如下图所示。如果出现了这3个进程表示从节点进程启动成功。
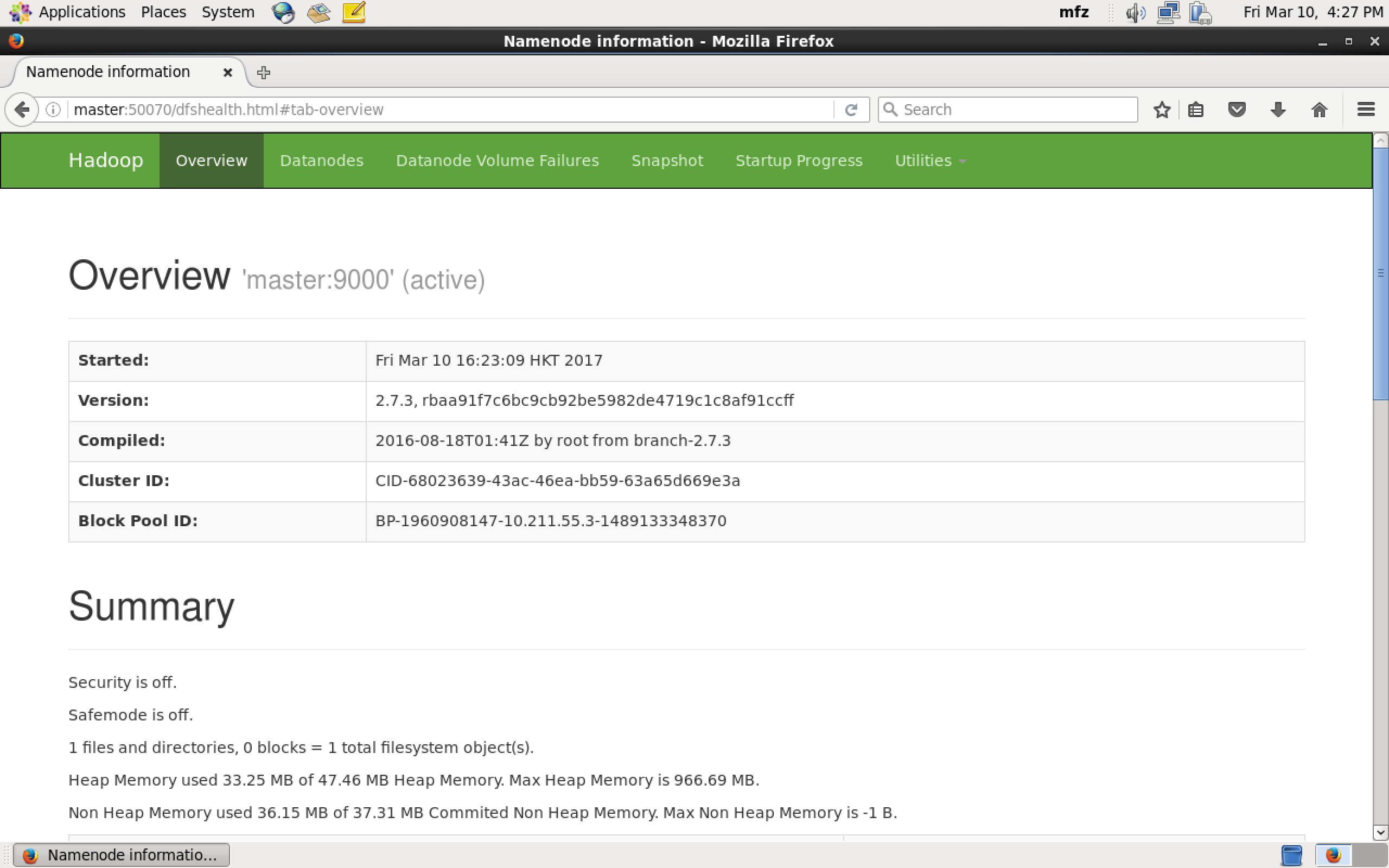
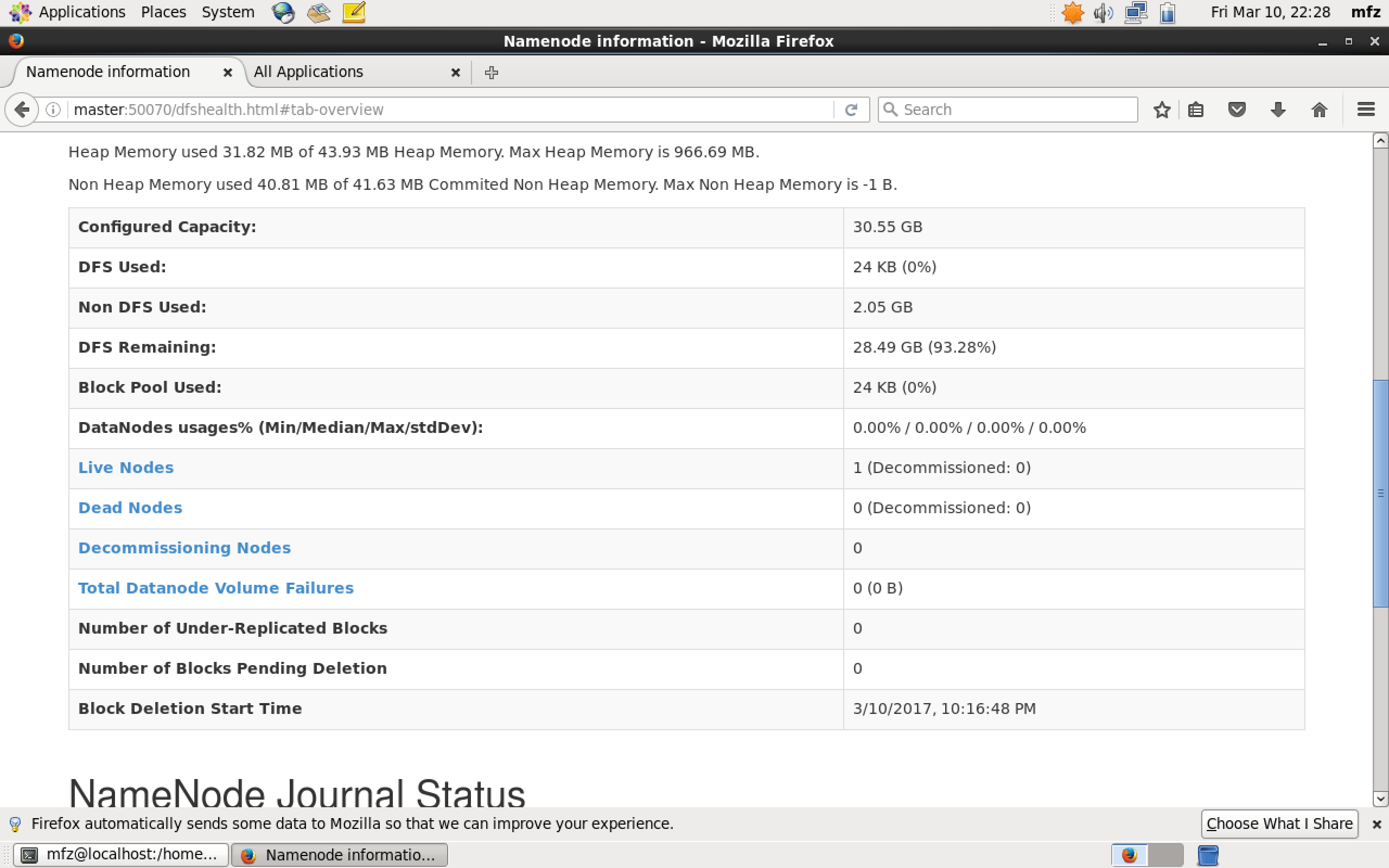
验证1:Web UI查看集群是否成功启动,在Master上启动Firefox浏览器,在浏览器地址栏中输入输入http://master:50070/,检查namenode 和datanode 是否正常。UI页面如下图所示。
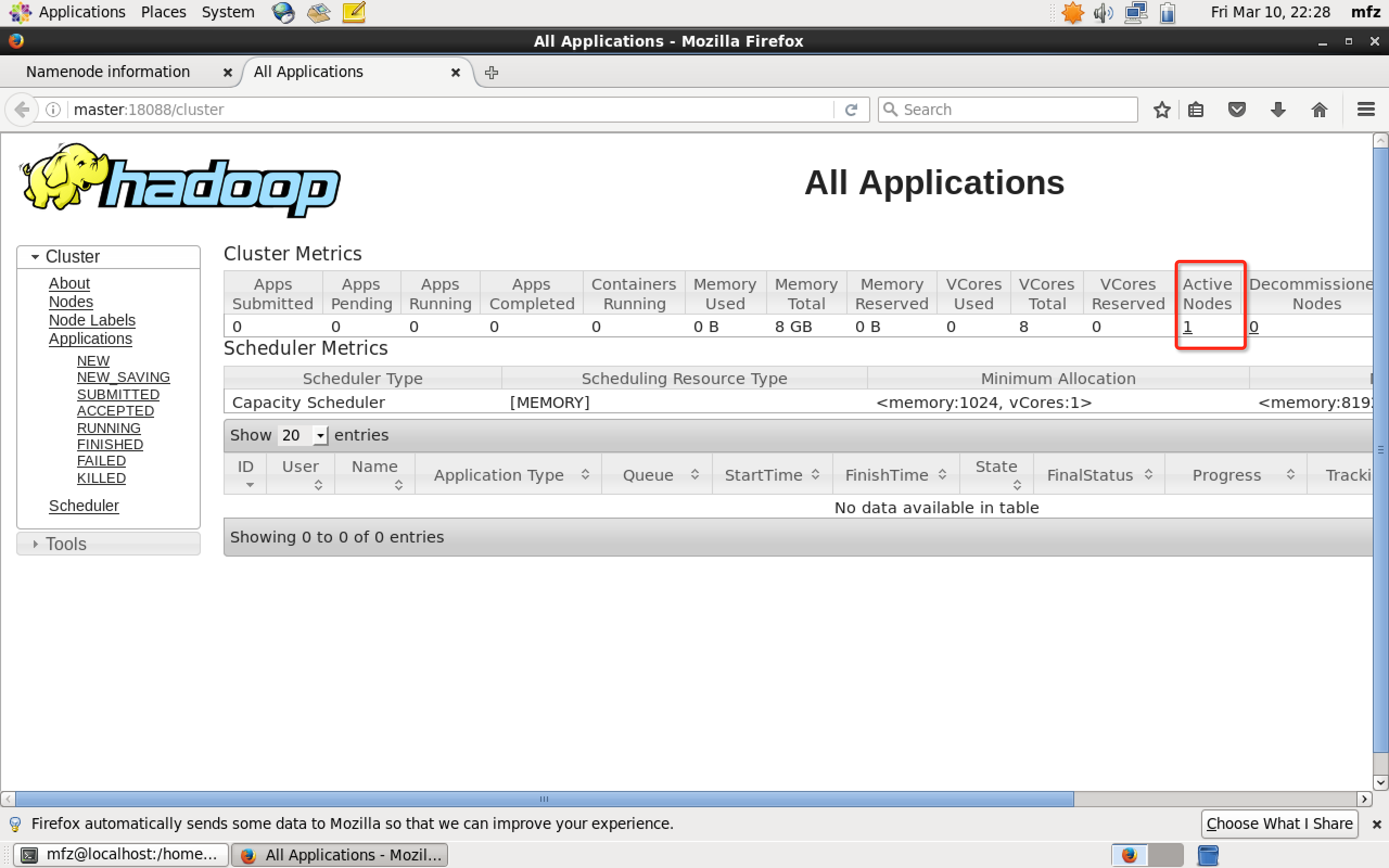
验证2: 在Master上启动Firefox浏览器,在浏览器地址栏中输入输入http://master:18088/,检查Yarn是否正常,页面如下图所示。
- 验证3:mfz用户下输入如下命令,得到结果最后输出'Job Finished in 72.742 seconds Estimated value of Pi is 3.20000000000000000000'则表示操作成功。
cd
cd hadoop-2.7./share/hadoop/mapreduce/
hadoop jar hadoop-mapreduce-examples-2.7..jar pi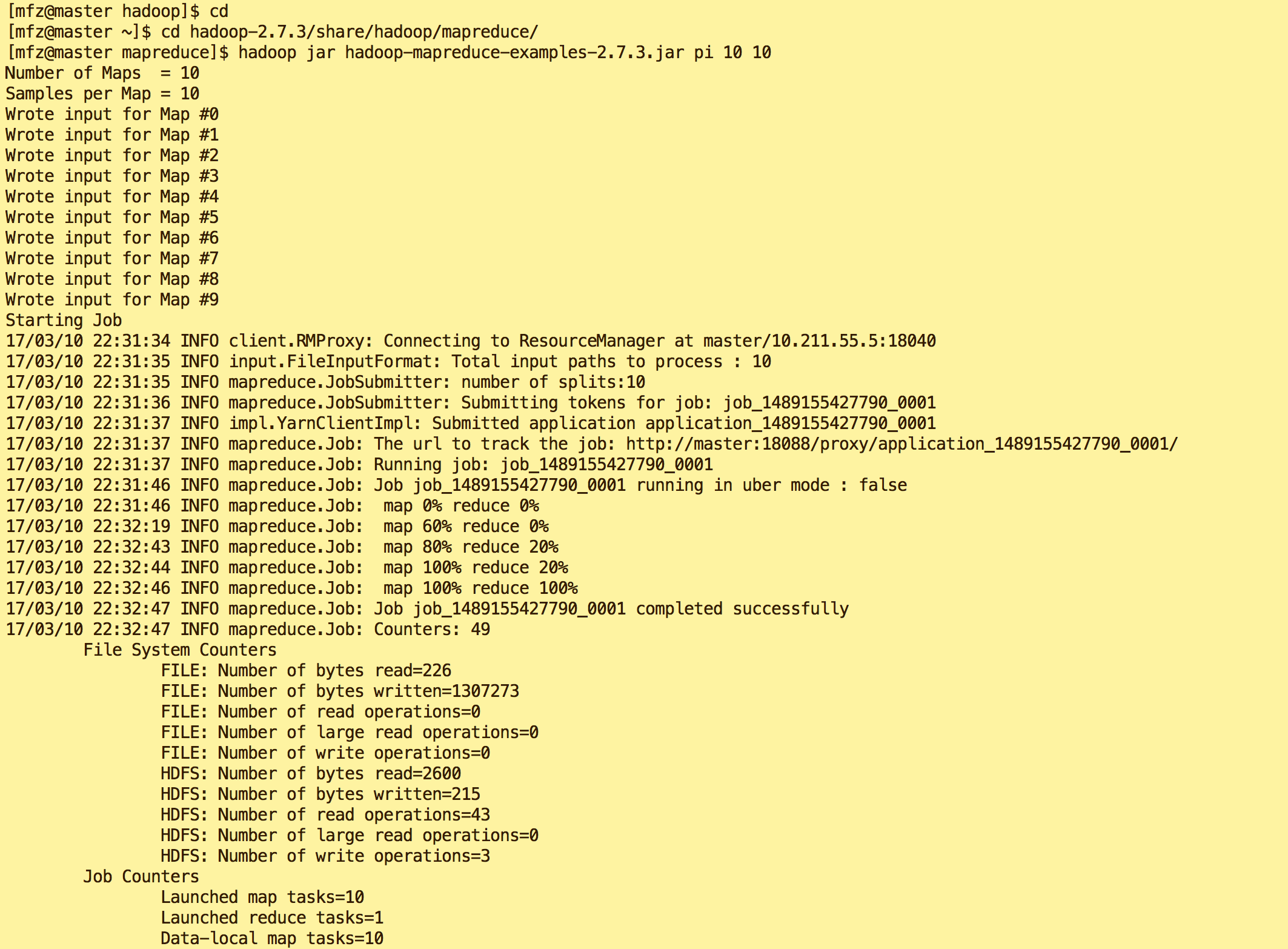
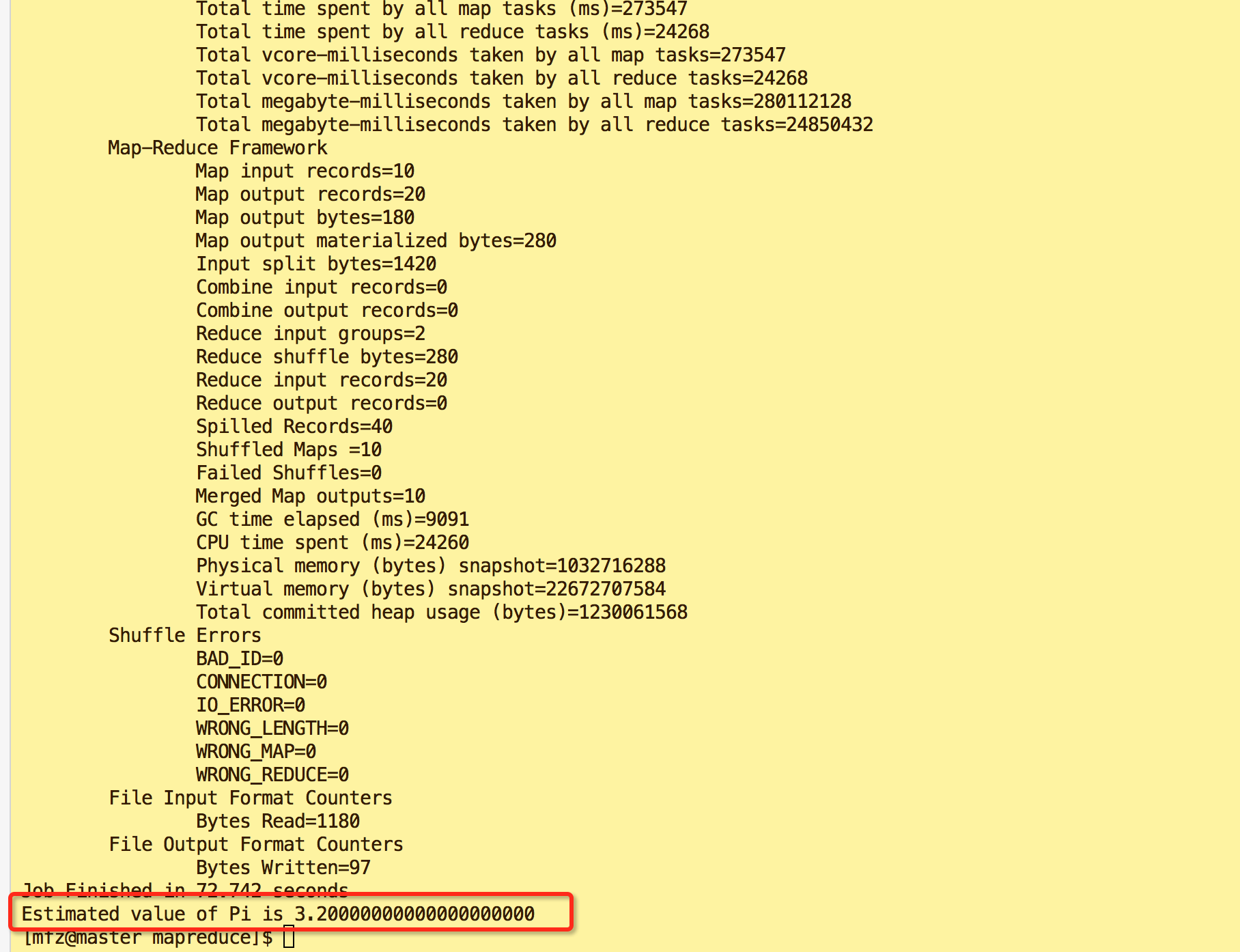
- 以上3个步骤验证都没有问题的话表示你成功完成了Hadoop分布式集群搭建。:)
验证启动结果

大数据系列之Hadoop分布式集群部署的更多相关文章
- Hadoop分布式集群部署(单namenode节点)
Hadoop分布式集群部署 系统系统环境: OS: CentOS 6.8 内存:2G CPU:1核 Software:jdk-8u151-linux-x64.rpm hadoop-2.7.4.tar. ...
- Hadoop教程(五)Hadoop分布式集群部署安装
Hadoop教程(五)Hadoop分布式集群部署安装 1 Hadoop分布式集群部署安装 在hadoop2.0中通常由两个NameNode组成,一个处于active状态,还有一个处于standby状态 ...
- hadoop分布式集群部署①
Linux系统的安装和配置.(在VM虚拟机上) 一:安装虚拟机VMware Workstation 14 Pro 以上,虚拟机软件安装完成. 二:创建虚拟机. 三:安装CentOS系统 (1)上面步 ...
- 大数据平台搭建-hadoop/hbase集群的搭建
版本要求 java 版本:1.8.*(1.8.0_60) 下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downl ...
- Hadoop实战:Hadoop分布式集群部署(一)
一.系统参数优化配置 1.1 系统内核参数优化配置 修改文件/etc/sysctl.conf,使用sysctl -p命令即时生效. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ...
- 大数据【三】YARN集群部署
一 概述 YARN是一个资源管理.任务调度的框架,采用master/slave架构,主要包含三大模块:ResourceManager(RM).NodeManager(NM).ApplicationMa ...
- Hadoop分布式集群部署
环境准备 IP HOSTNAME SYSTEM 192.168.131.129 hadoop-master CentOS 7.6 192.168.131.135 hadoop-slave1 CentO ...
- CentOS6安装各种大数据软件 第四章:Hadoop分布式集群配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 基于Hadoop分布式集群YARN模式下的TensorFlowOnSpark平台搭建
1. 介绍 在过去几年中,神经网络已经有了很壮观的进展,现在他们几乎已经是图像识别和自动翻译领域中最强者[1].为了从海量数据中获得洞察力,需要部署分布式深度学习.现有的DL框架通常需要为深度学习设置 ...
随机推荐
- PHP中file_exists与is_file、is_dir的区别,以及执行效率的比较
判断文件是否存在,有2个常用的PHP函数:is_file 和 file_exists, 判断文件夹是否存在,有2个常用PHP函数:is_dir 和 file_exists, 即 file_exists ...
- Delphi 常用API 函数
Delphi 常用API 函数 AdjustWindowRect 给定一种窗口样式,计算获得目标客户区矩形所需的窗口大小 AnyPopup 判断屏幕上是否存在任何弹出式窗口 ArrangeIconic ...
- Shell 基础
1.结构 #!指定执行脚本的shell #!/bin/sh # 注释行 命令和控制结构 2.修改权限 chmod +x ... 3 ...
- mysql 常用技巧
1.正则使用 比 LIKE 会牺牲很多的系统资源 尽量不要用 正则的语法和JS PHP 差不多 select * from t1 where email REGEXP "@163[,.]co ...
- Tamper Data 安装与使用
Tamper Data概览 注意:我将会讲述一些有关Tamper Data的基本常识,包括它的基本功能,如何安装等. Tamper Data是什么? Tamper Data 的真实含义,即&q ...
- 天兔(Lepus)监控系统慢查询分析平台安装配置
被监控端要安装pt工具 [root@HE1~]## yum -y install perl-IO-Socket-SSL [root@HE1~]## yum -y install perl-DBI [r ...
- HDU5057(分块)
Argestes and Sequence Time Limit: 5000/2500 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Ot ...
- 一次开放接口从需求分析到发布sdk线上包
新年开场篇,欢迎来点赞:本篇和大家分享的是使用webapi做得接口服务验证框架,需求来源是我打算把上篇提到的图片验证码做成一种服务提供给大家,尽管我在上篇已经把代码打包开源了,但是如果有一种快速对接成 ...
- Java异常处理机制以及try-catch-finally-return执行顺序
一,简单描述: 当出现程序无法控制的外部环境问题(用户提供的文件不存在,文件内容损坏,网络不可用...)时,JAVA就会用异常对象来描述. 二,JAVA中用2种方法处理异常: 1.在发生异常的地方直接 ...
- ORACLE_INSERT
Insert是T-sql中常用语句,Insert INTO table(field1,field2,...) values(value1,value2,...)这种形式的在应用程序开发中必不可少.但我 ...