Hadoop学习笔记—5.自定义类型处理手机上网日志
转载自http://www.cnblogs.com/edisonchou/p/4288737.html
Hadoop学习笔记—5.自定义类型处理手机上网日志
一、测试数据:手机上网日志
1.1 关于这个日志
假设我们如下一个日志文件,这个文件的内容是来自某个电信运营商的手机上网日志,文件的内容已经经过了优化,格式比较规整,便于学习研究。
该文件的内容如下(这里我只截取了三行):
1363157993044 18211575961 94-71-AC-CD-E6-18:CMCC-EASY 120.196.100.99 iface.qiyi.com 视频网站 15 12 1527 2106 200
1363157995033 15920133257 5C-0E-8B-C7-BA-20:CMCC 120.197.40.4 sug.so.360.cn 信息安全 20 20 3156 2936 200
1363157982040 13502468823 5C-0A-5B-6A-0B-D4:CMCC-EASY 120.196.100.99 y0.ifengimg.com 综合门户 57 102 7335 110349 200
每一行不同的字段有有不同的含义,具体的含义如下图所示:
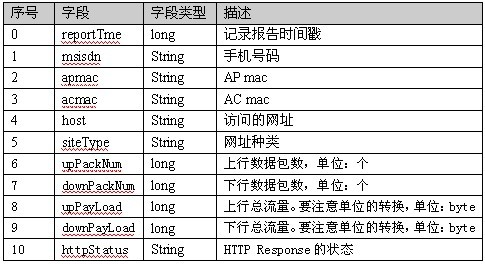
1.2 要实现的目标
有了上面的测试数据—手机上网日志,那么问题来了,如何通过map-reduce实现统计不同手机号用户的上网流量信息?通过上表可知,第 6~9个字段是关于流量的信息,也就是说我们需要为每个用户统计其upPackNum、downPackNum、upPayLoad以及 downPayLoad这个四个字段的数量和,达到以下的显示结果:
13480253104 3 3 180 180
13502468823 57 102 7335 110349
二、解决思路:封装手机流量
2.1 Writable接口
经过上一篇的学习,我们知道了在Hadoop中操作所有的数据类型都需要实现一个叫Writable的接口,实现了该接口才能够支持序列化,才能方便地在Hadoop中进行读取和写入。

public interface Writable {
/**
* Serialize the fields of this object to <code>out</code>.
*/
void write(DataOutput out) throws IOException;
/**
* Deserialize the fields of this object from <code>in</code>.
*/
void readFields(DataInput in) throws IOException;
}
从上面的代码中可以看到Writable 接口只有两个方法的定义,一个是write 方法,一个是readFields 方法。前者是把对象的属性序列化到DataOutput 中去,后者是从DataInput 把数据反序列化到对象的属性中。(简称“读进来”,“写出去”)
java 中的基本类型有char、byte、boolean、short、int、float、double 共7 中基本类型,除了char,都有对应的Writable 类型。但是,没有我们需要的对应类型。于是,我们需要仿照现有的对应Writable 类型封装一个自定义的数据类型,以供本次试验使用。
2.2 封装KpiWritable类型
我们需要为每个用户统计其upPackNum、downPackNum、upPayLoad以及downPayLoad这个四个字段的数量和,而这个四个字段又都是long 类型,于是我们可以封装以下代码:
/*
* 自定义数据类型KpiWritable
*/
public class KpiWritable implements Writable { long upPackNum; // 上行数据包数,单位:个
long downPackNum; // 下行数据包数,单位:个
long upPayLoad; // 上行总流量,单位:byte
long downPayLoad; // 下行总流量,单位:byte public KpiWritable() {
} public KpiWritable(String upPack, String downPack, String upPay,
String downPay) {
upPackNum = Long.parseLong(upPack);
downPackNum = Long.parseLong(downPack);
upPayLoad = Long.parseLong(upPay);
downPayLoad = Long.parseLong(downPay);
} @Override
public String toString() {
String result = upPackNum + "\t" + downPackNum + "\t" + upPayLoad
+ "\t" + downPayLoad;
return result;
} @Override
public void write(DataOutput out) throws IOException {
out.writeLong(upPackNum);
out.writeLong(downPackNum);
out.writeLong(upPayLoad);
out.writeLong(downPayLoad);
} @Override
public void readFields(DataInput in) throws IOException {
upPackNum = in.readLong();
downPackNum = in.readLong();
upPayLoad = in.readLong();
downPayLoad = in.readLong();
} }
通过实现Writable接口的两个方法,就封装好了KpiWritable类型。
三、编程实现:依然MapReduce
3.1 自定义Mapper类
/*
* 自定义Mapper类,重写了map方法
*/
public static class MyMapper extends
Mapper<LongWritable, Text, Text, KpiWritable> {
protected void map(
LongWritable k1,
Text v1,
org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, KpiWritable>.Context context)
throws IOException, InterruptedException {
String[] spilted = v1.toString().split("\t");
String msisdn = spilted[1]; // 获取手机号码
Text k2 = new Text(msisdn); // 转换为Hadoop数据类型并作为k2
KpiWritable v2 = new KpiWritable(spilted[6], spilted[7],
spilted[8], spilted[9]);
context.write(k2, v2);
};
}
这里将第6~9个字段的数据都封装到KpiWritable类型中,并将手机号和KpiWritable作为<k2,v2>传入下一阶段;
3.2 自定义Reducer类
/*
* 自定义Reducer类,重写了reduce方法
*/
public static class MyReducer extends
Reducer<Text, KpiWritable, Text, KpiWritable> {
protected void reduce(
Text k2,
java.lang.Iterable<KpiWritable> v2s,
org.apache.hadoop.mapreduce.Reducer<Text, KpiWritable, Text, KpiWritable>.Context context)
throws IOException, InterruptedException {
long upPackNum = 0L;
long downPackNum = 0L;
long upPayLoad = 0L;
long downPayLoad = 0L;
for (KpiWritable kpiWritable : v2s) {
upPackNum += kpiWritable.upPackNum;
downPackNum += kpiWritable.downPackNum;
upPayLoad += kpiWritable.upPayLoad;
downPayLoad += kpiWritable.downPayLoad;
} KpiWritable v3 = new KpiWritable(upPackNum + "", downPackNum + "",
upPayLoad + "", downPayLoad + "");
context.write(k2, v3);
};
}
这里将Map阶段每个手机号所对应的流量记录都一一进行相加求和,最后生成一个新的KpiWritable类型对象与手机号作为新的<k3,v3>返回;
3.3 完整代码实现
完整的代码如下所示:
3.4 调试运行效果

附件下载
(1)本次用到的手机上网日志(部分版):http://pan.baidu.com/s/1dDzqHWX
Hadoop学习笔记—5.自定义类型处理手机上网日志的更多相关文章
- Hadoop自定义类型处理手机上网日志
job提交源码分析 在eclipse中的写的代码如何提交作业到JobTracker中的哪?(1)在eclipse中调用的job.waitForCompletion(true)实际上执行如下方法 con ...
- Hadoop日记Day13---使用hadoop自定义类型处理手机上网日志
测试数据的下载地址为:http://pan.baidu.com/s/1gdgSn6r 一.文件分析 首先可以用文本编辑器打开一个HTTP_20130313143750.dat的二进制文件,这个文件的内 ...
- Hadoop学习笔记系列文章导航
一.为何要学习Hadoop? 这是一个信息爆炸的时代.经过数十年的积累,很多企业都聚集了大量的数据.这些数据也是企业的核心财富之一,怎样从累积的数据里寻找价值,变废为宝炼数成金成为当务之急.但数据增长 ...
- Hadoop学习笔记系列
Hadoop学习笔记系列 一.为何要学习Hadoop? 这是一个信息爆炸的时代.经过数十年的积累,很多企业都聚集了大量的数据.这些数据也是企业的核心财富之一,怎样从累积的数据里寻找价值,变废为宝炼 ...
- Hadoop学习笔记—15.HBase框架学习(基础实践篇)
一.HBase的安装配置 1.1 伪分布模式安装 伪分布模式安装即在一台计算机上部署HBase的各个角色,HMaster.HRegionServer以及ZooKeeper都在一台计算机上来模拟. 首先 ...
- Hadoop学习笔记—16.Pig框架学习
一.关于Pig:别以为猪不能干活 1.1 Pig的简介 Pig是一个基于Hadoop的大规模数据分析平台,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换 ...
- Hadoop学习笔记—9.Partitioner与自定义Partitioner
一.初步探索Partitioner 1.1 再次回顾Map阶段五大步骤 在第四篇博文<初识MapReduce>中,我们认识了MapReduce的八大步凑,其中在Map阶段总共五个步骤,如下 ...
- Hadoop学习笔记(7) ——高级编程
Hadoop学习笔记(7) ——高级编程 从前面的学习中,我们了解到了MapReduce整个过程需要经过以下几个步骤: 1.输入(input):将输入数据分成一个个split,并将split进一步拆成 ...
- Hadoop学习笔记—12.MapReduce中的常见算法
一.MapReduce中有哪些常见算法 (1)经典之王:单词计数 这个是MapReduce的经典案例,经典的不能再经典了! (2)数据去重 "数据去重"主要是为了掌握和利用并行化思 ...
随机推荐
- C库 - 常用文件IO函数
#include<stdio.h> 0. 文件打开关闭FILE *fp = fopen("C:\\a.dat","wb+");fclose(fp); ...
- intellij中javax包的导入
新建intellij的maven web想项目的时候,出现的问题,import javax.servlet.http相关的包出错 好久不搭建也好久没用intellij了,都忘了,在这里笔记一下 再次吐 ...
- 引用WCF地址报下载“https://xxx:8004/TerminalHandler.svc?disco”时出错问题
服务发布了wcf服务后,在客户端引用发现出现以下错误 - 来自“DISCO 文档”的报告是“下载“https://servername:8004/TerminalHandler.svc?disco”时 ...
- apicloud教程
http://community.apicloud.com/bbs/forum.php?mod=viewthread&tid=15939
- LYF模板连接.txt
在解决方案里创建了一个新建网站,在其右键下添加一个模板后,准备使用模板的,在添加新建项里突然没有“使用模板页的web窗体”,顿时感觉悲剧... 解决方法:模板页代码---LYFMaterPage.Ma ...
- ExecutorService的submit(Runnable x)和execute(Runnable x) 两个方法的本质区别
Runnable任务没有返回值,而Callable任务有返回值.并且Callable的call()方法只能通过ExecutorService的submit(Callable <T> tas ...
- iosUISegmentedControl的基本设置
//创建segmentControl 分段控件 UISegmentedControl *segC = [[UISegmentedControl alloc]initWithFrame:CGRectMa ...
- ios导航栏又按钮添加图片后使其保持原色
UIBarButtonItem *rightBarItem = [[UIBarButtonItem alloc] initWithTitle:nil style:UIBarButtonItemStyl ...
- 多个git账户生成多份rsa秘钥实现多个账户同时使用配置
下文分享一个多个git账户生成多份rsa秘钥实现多个账户同时使用配置例子了,这个例子非常的好用对于有多个git的朋友有不小的帮助. 使用过git的童鞋应该对id_rsa秘钥不陌生,总得用github吧 ...
- HDU2519:新生晚会
Problem Description 开学了,杭电又迎来了好多新生.ACMer想为新生准备一个节目.来报名要表演节目的人很多,多达N个,但是只需要从这N个人中选M个就够了,一共有多少种选择方法? ...