为什么是梯度下降?SGD
在机器学习算法中,为了优化损失函数loss function ,我们往往采用梯度下降算法来进行优化。举个例子:
线性SVM的得分函数和损失函数分别为:

一般来说,我们是需要求损失函数的最小值,而损失函数是关于权值矩阵的函数。为了求解权值矩阵,我们一般采用数值求解的方法,但是为什么是梯度呢?
在CS231N课程中给出了解释,首先我们采用
策略1:随机搜寻(不太实用),也就是在一个范围内,任意选择W的值带入到损失函数中,那个损失函数值最小就取谁,这个很不实用。
策略2:随机局部搜索 ,就是在W值的附近,指定一个小方向,沿着这个小方向改变W,将改变方向后的W带入损失函数进行判断。具体步骤是对于一个当前W,我们每次实验和添加δW′,然后看看损失函数是否比当前要低,如果是,就替换掉当前的W。这个方向不明确
策略3 顺着梯度下滑 和策略2对比,实际上上述小方向指定了,也就是说δW′应该等于stepsize*|grad|
然而,为什么是梯度方向呢?上一张图解释:
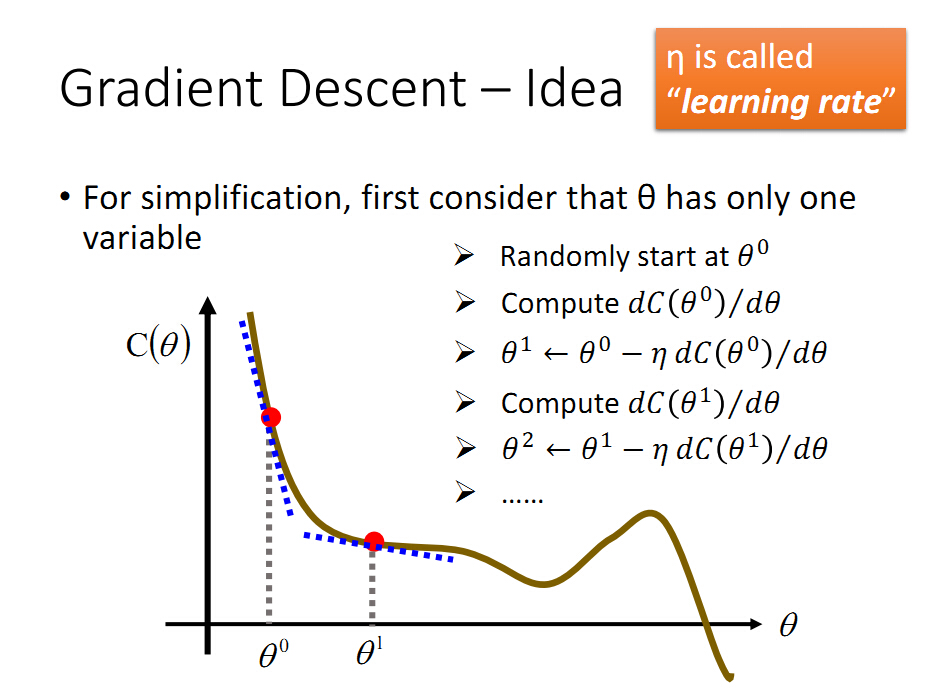
C(θ)是损失函数,θ是权值,为了得到在那个θ下C(θ)最小。一般选取初始点θ0,然后依据上面的搜索策略对θ0进行变更,
但是到底是向前还是向后运动呢?当我们知道图像后,很明显是向前运动,才能使得损失函数变小,但是在我们不知道图像的时候,梯度/导数会告诉我们答案。根据上图可知,在θ0点处的导数,也就是斜率是负的,为了减小损失函数,一般是沿着斜率的负方向运动,也就是
θ1=θ0-ηdc(θ0)/d(θ)
相当于θ1比θ0向正方向运动,也就是向前运动,满足我们的判断。
到此,我们可以看出,梯度下降的方法的步骤就是选择权值一个初始点,然后对权值进行小范围的迭代更新,然而小范围更新的方向为损失函数
对权值选择点的导数负方向,这样就能保证损失函数逐渐取得最小值。
比较三种梯度下降法:批量梯度下降法(Batch Gradient Descent,简称BGD)、随机梯度下降法(Stochastic Gradient Descent,简称SGD)和
小批量梯度下降法(Mini-batch Gradient Descent,简称MBGD)
设特征有n+1维度,对应特征向量是X0-XN,系数向量是θ0-θN
每一个特征向量为x(i) ,一共有M个特征向量,或者说M个数据。
BGD:最原始的梯度下降,它的具体思路是在更新每一参数时都使用所有的样本来进行更新,其数学形式如下:

SGD:由于批量梯度下降法在更新每一个参数时,都需要所有的训练样本,所以训练过程会随着样本数量的加大而变得异常的缓慢。
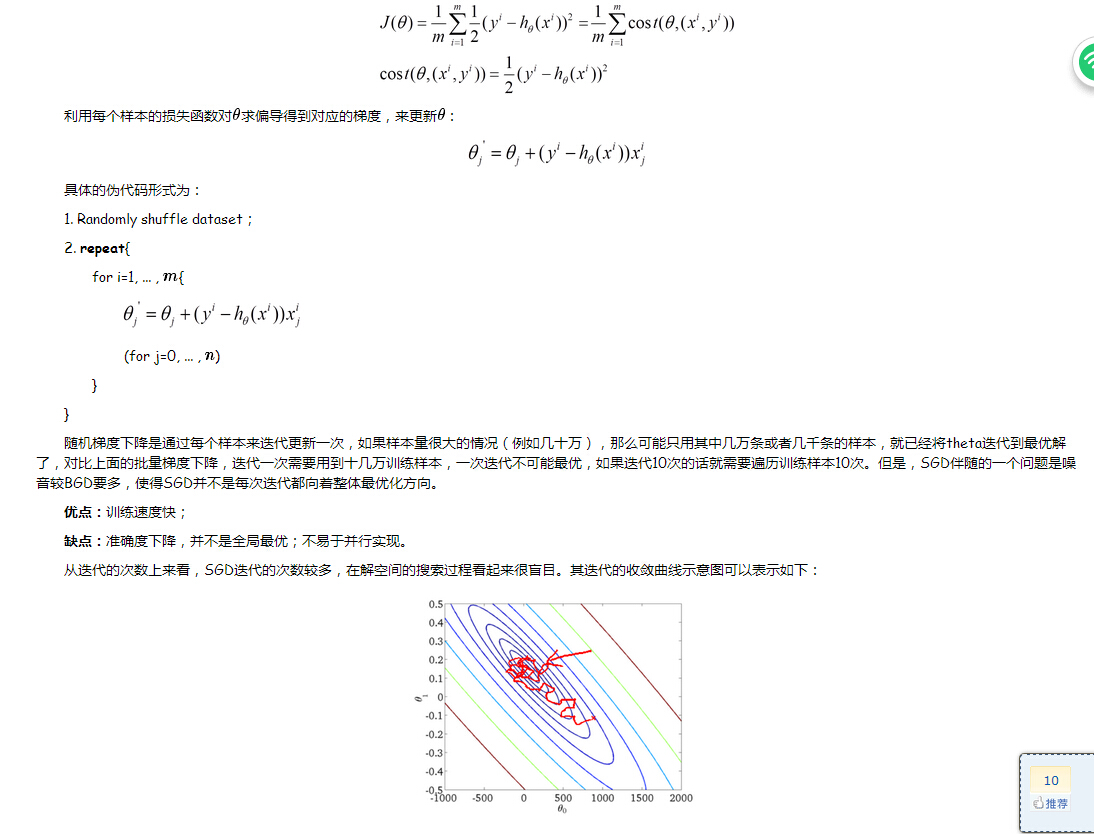
实际上,这个只是把上面的1-M所有的数据求和去掉了,也就是来一个数据更新一次。
MBGD:是一个折中的方案,也就是说M太大了,1太小了,自己定义一个batch值来更新数据,每多少个batch值更新一下权值。

显而易见,只是把上面的M换成了10.
为什么是梯度下降?SGD的更多相关文章
- 优化-最小化损失函数的三种主要方法:梯度下降(BGD)、随机梯度下降(SGD)、mini-batch SGD
优化函数 损失函数 BGD 我们平时说的梯度现将也叫做最速梯度下降,也叫做批量梯度下降(Batch Gradient Descent). 对目标(损失)函数求导 沿导数相反方向移动参数 在梯度下降中, ...
- 批量梯度下降(BGD)、随机梯度下降(SGD)以及小批量梯度下降(MBGD)的理解
梯度下降法作为机器学习中较常使用的优化算法,其有着三种不同的形式:批量梯度下降(Batch Gradient Descent).随机梯度下降(Stochastic Gradient Descent ...
- [sklearn] 实现随即梯度下降(SGD)&分类器评价参数查看
直接贴代码吧: 1 # -*- coding:UTF-8 -*- 2 from sklearn import datasets 3 from sklearn.cross_validation impo ...
- 梯度下降GD,随机梯度下降SGD,小批量梯度下降MBGD
阅读过程中的其他解释: Batch和miniBatch:(广义)离线和在线的不同
- Pytorch_第七篇_深度学习 (DeepLearning) 基础 [3]---梯度下降
深度学习 (DeepLearning) 基础 [3]---梯度下降法 Introduce 在上一篇"深度学习 (DeepLearning) 基础 [2]---神经网络常用的损失函数" ...
- 各种梯度下降 bgd sgd mbgd adam
转载 https://blog.csdn.net/itchosen/article/details/77200322 各种神经网络优化算法:从梯度下降到Adam方法 在调整模型更新权重和偏差 ...
- 深度学习笔记之【随机梯度下降(SGD)】
随机梯度下降 几乎所有的深度学习算法都用到了一个非常重要的算法:随机梯度下降(stochastic gradient descent,SGD) 随机梯度下降是梯度下降算法的一个扩展 机器学习中一个反复 ...
- 深度学习必备:随机梯度下降(SGD)优化算法及可视化
补充在前:实际上在我使用LSTM为流量基线建模时候,发现有效的激活函数是elu.relu.linear.prelu.leaky_relu.softplus,对应的梯度算法是adam.mom.rmspr ...
- 梯度下降:SGD vs Momentum vs NAG vs Adagrad vs Adadelta vs RMSprop vs Adam
原文地址:https://www.jianshu.com/p/7a049ae73f56 梯度下降优化基本公式:\({\theta\leftarrow\theta-\eta\cdot\nabla_\th ...
随机推荐
- MediaWiki安装与配置(Ubuntu 10.4)
实验室准备发布一个网站,本来是准备外包给别人做的,后来自己调研了一下,发现也没有想象的复杂和困难,于是最近一周自己吭哧吭哧地把网站搭好了. 之所以使用Mediawiki,一是考虑到是以实验室发布,不想 ...
- java上传图片或者文件
package com.pat.postrequestemulator; import java.io.BufferedReader; import java.io.DataInputStream; ...
- 【WPF】分享自用 白板窗口(空窗口) 控件 BlankWindow,基于WindowChrome。
一.背景 吃产品的亏,上设计的当,最后死在变化上. 现在的产品和设计都喜欢在窗口上做一些事,比如让Title做很多事,好像跟人家用一样的窗口很Low似的,好像真的挺Low的. 所以,还不如弄一个黑板似 ...
- node(websocket)
websocket原本是html5下实现长链接的一个特性,当前已被众多浏览器支持. 在websocket协议中,首先通过http交换一次握手,明确将协议升级至websocket.同时建立一个TCP通道 ...
- Java IO3:字节流
流类 Java的流式输入/输出是建立在四个抽象类的基础上的:InputStream.OutputStream.Reader.Writer.它们用来创建具体的流式子类.尽管程序通过具体子类执行输入/输出 ...
- SpringMVC自定义注入controller变量
springmvc config the controller parameter injection 问题描述 在SpringMVC中默认可以注入Model,ModelAndView,@Reques ...
- Bootstrap~多级导航(级联导航)的实现
回到目录 在bootstrap官方来说,导航最多就是两级,两级以上是无法实现的,大叔找了一些第三方的资料,终于找到一个不错的插件,使用上和效果上都还不错,现在和大家分享一下 插件地址:http://v ...
- Android开发小问题总结
Android开发遇到的小问题之小解: ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ ...
- tool list
http://www.pairwise.org/tools.asp 用例设计工具 组合测试工具pict 代码调试 Findbugs 介绍及使用方法 接口测试工具 webservices studi ...
- Java 线程 — ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor 该类继承自ThreadPoolExecutor,增加了定时执行线程和延迟启动的功能,这两个功能是通过延时队列DelayedWorkQueue辅助 ...