[Spark SQL_3] Spark SQL 高级操作
0. 说明
DataSet 介绍 && Spark SQL 访问 JSON 文件 && Spark SQL 访问 Parquet 文件 && Spark SQL 访问 JDBC 数据库 && Spark SQL 作为分布式查询引擎
1. DataSet 介绍
强类型集合,可以转换成并行计算。
Dataset 上可以执行的操作分为 Transfermation 和 Action ,类似于 RDD。
Transfermation 生成新的 DataSet,Action 执行计算并返回结果。
DataSet 是延迟计算,只有当调用 Action 时才会触发执行。内部表现为逻辑计划。
Action 调用时,Spark 的查询优化器对逻辑计划进行优化,生成物理计划,用于分布式行为下高效的执行。
具体的执行计划可以通过 explain函数 来查看,方式如下:
scala> spark.sql("explain select name,class,score from tb_student").show(,false)
结果如图所示,show(1000 , false) 表示显式 1000行数据,结果不截断显式。

2. Spark SQL 访问 JSON 文件
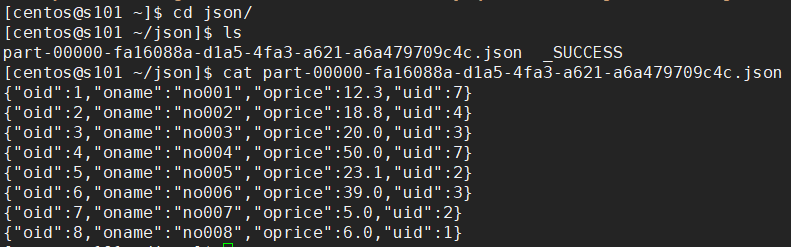
【保存 JSON 文件】
# 创建 DataFrame
scala> val df = spark.sql("select * from orders") # 输出 JSON 文件
scala> df.write.json("file:///home/centos/json")
【读取 JSON 文件】
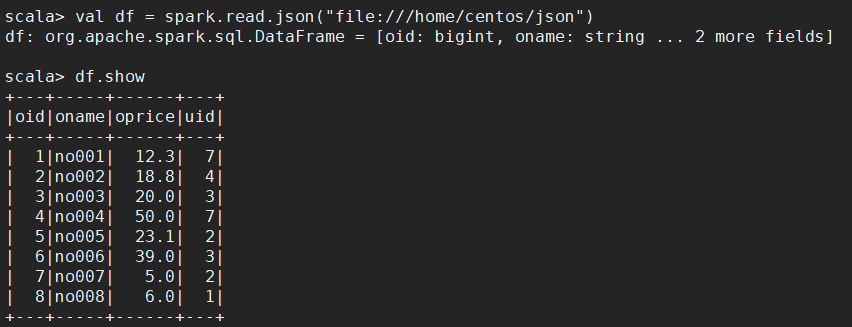
scala> val df = spark.read.json("file:///home/centos/json")
scala> df.show
3. Spark SQL 访问 Parquet 文件
【保存】
# 创建 DataFrame
scala> val df = spark.sql("select * from orders") # 保存成 parquet 文件
scala> df.write.parquet("file:///home/centos/par")
【读取】
# 创建 DataFrame
scala> val df = spark.read.parquet("file:///home/centos/par") # 读取 Parquet 文件
scala> df.show

4. Spark SQL 访问 JDBC 数据库
【4.1 处理第三方 jar】
spark SQL 是分布式数据库访问,需要将驱动程序分发到所有 worker 节点或者通过 --jars 命令指定附件
分发 jar 到所有节点 ,third.jar 为第三方 jar 包
xsync /soft/spark/jars/third.jar
通过--jars 命令指定
spark-shell --master spark://s101:7077 --jars /soft/spark/jars/third.jar
【4.2 读取 MySQL 数据】
val prop = new java.util.Properties()
prop.put("driver" , "com.mysql.jdbc.Driver")
prop.put("user" , "root")
prop.put("password" , "root")
# 读取
val df = spark.read.jdbc("jdbc:mysql://192.168.23.101:3306/big12" , "music" ,prop) ;
# 显示
df.show
【4.3 保存数据到 MySQL 表(表不能存在)】
val prop = new java.util.Properties()
prop.put("driver" , "com.mysql.jdbc.Driver")
prop.put("user" , "root")
prop.put("password" , "root")
# 保存
dataframe.write.jdbc("jdbc:mysql://192.168.231.1:3306/mydb" , "emp" ,prop ) ;
5. Spark SQL 作为分布式查询引擎
【5.1 说明】
终端用户或应用程序可以直接同 Spark SQL 交互,而不需要写其他代码。

【5.2 启动 Spark的 thrift-server 进程】
在 spark/sbin 目录下执行以下操作
[centos@s101 /soft/spark/sbin]$ start-thriftserver.sh --master spark://s101:7077
【5.3 验证】
查看 Spark WebUI,访问 http://s101:8080
端口检查,检查10000端口是否启动
netstat -anop | grep
【5.4 使用 Spark 的 beeline 程序测试】
在 spark/bin 目录下执行以下操作
# 进入 Spark 的 beeline
[centos@s101 /soft/spark/bin]$ ./beeline # 连接 Hive
!connect jdbc:hive2://localhost:10000/big12;auth=noSasl # 查看表
: jdbc:hive2://localhost:10000/big12> show tables;
【5.5 编写客户端 Java 程序与 Spark 分布式查询引擎交互】
[添加依赖]
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.1.0</version>
</dependency>
[代码编写]
package com.share.sparksql; import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet; /**
* 使用 Spark SQL 分布式查询引擎
*/
public class ThriftServerDemo {
public static void main(String[] args) {
try {
Class.forName("org.apache.hive.jdbc.HiveDriver");
Connection connection = DriverManager.getConnection("jdbc:hive2://s101:10000/big12;auth=noSasl");
ResultSet rs = connection.createStatement().executeQuery("select * from orders");
while (rs.next()) {
System.out.printf("%d / %s\r\n", rs.getInt(1), rs.getString(2));
}
rs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
[特别说明]
以上黄色部分为 HiveServer2 的验证模式,如果未添加以上黄色部分则会报错,报错如下:

[Spark SQL_3] Spark SQL 高级操作的更多相关文章
- 大数据学习day25------spark08-----1. 读取数据库的形式创建DataFrame 2. Parquet格式的数据源 3. Orc格式的数据源 4.spark_sql整合hive 5.在IDEA中编写spark程序(用来操作hive) 6. SQL风格和DSL风格以及RDD的形式计算连续登陆三天的用户
1. 读取数据库的形式创建DataFrame DataFrameFromJDBC object DataFrameFromJDBC { def main(args: Array[String]): U ...
- 【转】【技术博客】Spark性能优化指南——高级篇
http://mp.weixin.qq.com/s?__biz=MjM5NjQ5MTI5OA==&mid=2651745207&idx=1&sn=3d70d59cede236e ...
- Spark性能优化指南——高级篇
本文转载自:https://tech.meituan.com/spark-tuning-pro.html 美团技术点评团队) Spark性能优化指南——高级篇 李雪蕤 ·2016-05-12 14:4 ...
- 大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池
第0章 预备知识0.1 Scala0.1.1 Scala 操作符0.1.2 拉链操作0.2 Spark Core0.2.1 Spark RDD 持久化0.2.2 Spark 共享变量0.3 Spark ...
- 小记---------spark组件与其他组件的比较 spark/mapreduce ;spark sql/hive ; spark streaming/storm
Spark与Hadoop的对比 Scala是Spark的主要编程语言,但Spark还支持Java.Python.R作为编程语言 Hadoop的编程语言是Java
- [Spark] 05 - Spark SQL
关于Spark SQL,首先会想到一个问题:Apache Hive vs Apache Spark SQL – 13 Amazing Differences Hive has been known t ...
- Hive on Spark和Spark sql on Hive,你能分的清楚么
摘要:结构上Hive On Spark和SparkSQL都是一个翻译层,把一个SQL翻译成分布式可执行的Spark程序. 本文分享自华为云社区<Hive on Spark和Spark sql o ...
- Spark 键值对RDD操作
键值对的RDD操作与基本RDD操作一样,只是操作的元素由基本类型改为二元组. 概述 键值对RDD是Spark操作中最常用的RDD,它是很多程序的构成要素,因为他们提供了并行操作各个键或跨界点重新进行数 ...
- spark中RDD的转化操作和行动操作
本文主要是讲解spark里RDD的基础操作.RDD是spark特有的数据模型,谈到RDD就会提到什么弹性分布式数据集,什么有向无环图,本文暂时不去展开这些高深概念,在阅读本文时候,大家可以就把RDD当 ...
随机推荐
- LNP环境下Nginx与PHP配合解析的原理
正在理解中,查阅资料,加上自我理解,得出如下结论,如有错误,欢迎指正.... LNP环境,Nginx与PHP配合运行的原理解释: 以前的互联网时代我们成为web1.0时代,那时用户是被动接受网络信息, ...
- 学了近一个月的java web 感想
对于每天学习的新知识进行一定的总结,是有必要的. 之前我学的每一门知识,我都没有怎么总结自己的问题,也没有怎么去想想该怎样才能学的更好,把知识掌握的更牢固.从现在开始呢,我会每半个月,或每一个月总结总 ...
- c语言-遍历pci设备(1)io访问
前言 最近楼主比较苦逼啊,主管布置了一道访问pci的作业,这个作业使用io方式还可以非常浪地将所有的东西都给读取出来,虽然不能读取出pci-e设备的所有信息,但是还是可以将256位的其他东西给读出来的 ...
- .5-浅析webpack源码之入口函数
从convert-argv出来后,目前进度在这: yargs.parse(process.argv.slice(2), (err, argv, output) => { // ... // 从这 ...
- C# Azure 设置云端应用程序的默认时间
在微软云Azure中,应用程序(website)的默认时间是按照美国UTC的时间的. 例如,在应用程序中获取DateTime.Now,的时候,是获取UTC的时间,不是中国的时间. 所以我们开始在这里设 ...
- 设计模式学习总结(一)——设计原则与UML统一建模语言
一.概要 设计模式(Design Pattern)是一套被反复使用.多数人知晓的.经过分类的.代码设计经验的总结. 使用设计模式的目的:为了代码可重用性.让代码更容易被他人理解.保证代码可靠性. 设计 ...
- SQL Server T—SQL 视图 事务
一 视图 视图是存储在数据库中的查询的SQL 语句, 视图是从一个或多个表或视图中导出的表,是一张虚表,只能对视图进行查询,不能增.删.改. 对视图进行修改要在相应的基本表中进行修改,修改会自动的反应 ...
- [日常] C语言中的字符数组和字符串
c语言字符数组和字符串:1.存放字符的数组称为字符数组 char str[]2.'\0'也被称为字符串结束标志3.由" "包围的字符串会自动在末尾添加'\0'4.逐个字符地给数组赋 ...
- 37.Linux驱动调试-根据oops的栈信息,确定函数调用过程
上章链接入口: http://www.cnblogs.com/lifexy/p/8006748.html 在上章里,我们分析了oops的PC值在哪个函数出错的 本章便通过栈信息来分析函数调用过程 1. ...
- Navicat11全系列激活工具和使用方法
Navicat特别好使,但是就是得注册,在网上看到了一个激活工具,成功激活了Navicat...工具链接地址是.. https://files.cnblogs.com/files/miantiaoan ...