ELK logstash 处理MySQL慢查询日志
在生产环境下,logstash 经常会遇到处理多种格式的日志,不同的日志格式,解析方法不同。下面来说说logstash处理多行日志的例子,对MySQL慢查询日志进行分析,这个经常遇到过,网络上疑问也很多。
MySQL慢查询日志格式如下:
|
1
2
3
4
5
|
# User@Host: ttlsa[ttlsa] @ [10.4.10.12] Id: 69641319
# Query_time: 0.000148 Lock_time: 0.000023 Rows_sent: 0 Rows_examined: 202
SET timestamp=1456717595;
select `Id`, `Url` from `File` where `Id` in ('201319', '201300');
# Time: 160229 11:46:37
|
filebeat配置
我这里是使用filebeat 1.1.1版本的,之前版本没有multiline配置项,具体方法看后面那种。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
filebeat:
prospectors:
-
paths:
- /www.ttlsa.com/logs/mysql/slow.log
document_type: mysqlslowlog
input_type: log
multiline:
negate: true
match: after
registry_file: /var/lib/filebeat/registry
output:
logstash:
hosts: ["10.6.66.14:5046"]
shipper:
logging:
files:
|
logstash配置
1. input段配置
|
1
2
3
4
5
6
7
|
# vi /etc/logstash/conf.d/01-beats-input.conf
input {
beats {
port => 5046
host => "10.6.66.14"
}
}
|
2. filter 段配置
|
1
2
3
4
5
6
7
8
9
10
11
12
|
# vi /etc/logstash/conf.d/16-mysqlslowlog.log
filter {
if [type] == "mysqlslowlog" {
grok {
match => { "message" => "(?m)^#\s+User@Host:\s+%{USER:user}\[[^\]]+\]\s+@\s+(?:(?<clienthost>\S*) )?\[(?:%{IPV4:clientip})?\]\s+Id:\s+%{NUMBER:row_id:int}\n#\s+Query_time:\s+%{NUMBER:query_time:float}\s+Lock_time:\s+%{NUMBER:lock_time:float}\s+Rows_sent:\s+%{NUMBER:rows_sent:int}\s+Rows_examined:\s+%{NUMBER:rows_examined:int}\n\s*(?:use %{DATA:database};\s*\n)?SET\s+timestamp=%{NUMBER:timestamp};\n\s*(?<sql>(?<action>\w+)\b.*;)\s*(?:\n#\s+Time)?.*$" }
}
date {
match => [ "timestamp", "UNIX", "YYYY-MM-dd HH:mm:ss"]
remove_field => [ "timestamp" ]
}
}
}
|
关键之重是grok正则的配置。
3. output段配置
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# vi /etc/logstash/conf.d/30-beats-output.conf
output {
if "_grokparsefailure" in [tags] {
file { path => "/var/log/logstash/grokparsefailure-%{[type]}-%{+YYYY.MM.dd}.log" }
}
if [@metadata][type] in [ "mysqlslowlog" ] {
elasticsearch {
hosts => ["10.6.66.14:9200"]
sniffing => true
manage_template => false
template_overwrite => true
index => "%{[@metadata][beat]}-%{[type]}-%{+YYYY.MM.dd}"
document_type => "%{[@metadata][type]}"
}
}
}
|
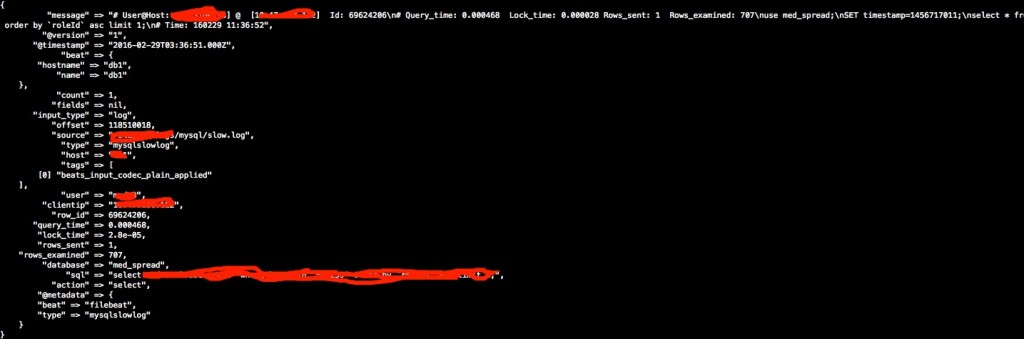
标准输出结果截图
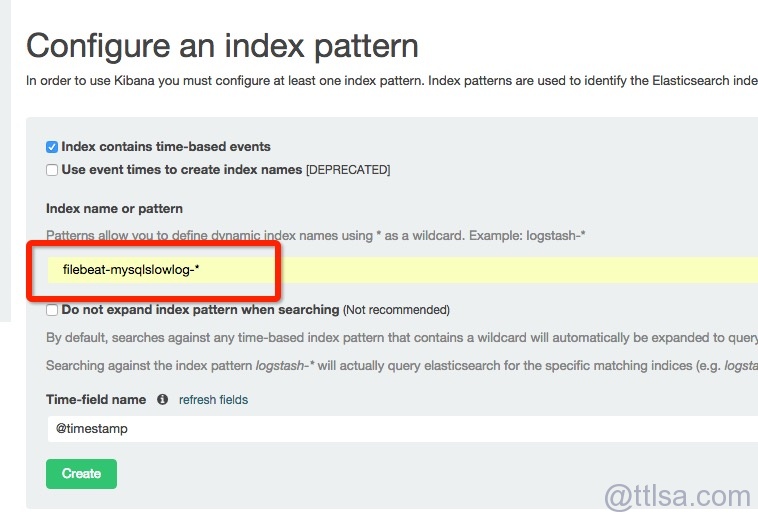
elasticsearch结果截图

如果是使用filebeat1.1.1之前的版本,配置如下:
1. filebeat配置
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
filebeat:
prospectors:
-
paths:
- /www.ttlsa.com/logs/mysql/slow.log
document_type: mysqlslowlog
input_type: log
registry_file: /var/lib/filebeat/registry
output:
logstash:
hosts: ["10.6.66.14:5046"]
shipper:
logging:
files:
|
2. logstash input段配置
|
1
2
3
4
5
6
7
8
9
10
11
|
input {
beats {
port => 5046
host => "10.6.66.14"
codec => multiline {
pattern => "^# User@Host:"
negate => true
what => previous
}
}
}
|
其它配置不变。
如有疑问跟帖,或者加群沟通。
ELK logstash 处理MySQL慢查询日志的更多相关文章
- ELK logstash 处理MySQL慢查询日志(初步)
写在前面:在做ELK logstash 处理MySQL慢查询日志的时候出现的问题: 1.测试数据库没有慢日志,所以没有日志信息,导致 IP:9200/_plugin/head/界面异常(忽然出现日志数 ...
- logstash收集MySQL慢查询日志
#此处以收集mysql慢查询日志为准,根据文件名不同添加不同的字段值input { file { path => "/data/order-slave-slow.log" t ...
- 使用ELK收集分析MySQL慢查询日志
参考文档:https://www.cnblogs.com/bixiaoyu/p/9638505.html MySQL开启慢查询不详述 MySQL5.7慢查询日志格式如下 /usr/local/mysq ...
- 通过logstash收集mysql慢查询日志转换为json
input { file { type => "mysql-slow" path => "/var/log/slow_mysqld.log" sta ...
- 企业级中带你ELK如何实时收集分析Mysql慢查询日志
什么是Mysql慢查询日志? 当SQL语句执行时间超过设定的阈值时,便于记录到指定的日志文件中或者表中,所有记录称之为慢查询日志 为什么要收集Mysql慢查询日志? 数据库在运行期间,可能会存在这很多 ...
- mysql慢查询日志分析工具 mysqlsla(转)
mysql数据库的慢查询日志是非常重要的一项调优辅助日志,但是mysql默认记录的日志格式阅读时不够友好,这是由mysql日志记录规则所决定的,捕获一条就记录一条,虽说记录的信息足够详尽,但如果将浏览 ...
- MySQL 慢查询日志分析及可视化结果
MySQL 慢查询日志分析及可视化结果 MySQL 慢查询日志分析 pt-query-digest分析慢查询日志 pt-query-digest --report slow.log 报告最近半个小时的 ...
- MySQL慢查询日志
实验环境: OS X EI Captian + MySQL 5.7 一.配置MySQL自动记录慢查询日志 查看变量,也就是配置信息 show (global) variables like '%slo ...
- MySQL慢查询日志释疑总结
之前写了一篇"MySQL慢查询日志总结",总结了一些MySQL慢查询日志常用的相关知识,这里总结一下在工作当中遇到关于MySQL慢查询日志的相关细节问题,有些是释疑或自己有疑惑 ...
随机推荐
- mfc 控件添加变量
关联控件变量 初始化数据 一.关联控件变量 .为Edit控件关联数值类变量 变量名 m_edt1_s .为Edit控件关联控件类变量 变量名 m_edt1_ctl 二.控件变量的使用 HWND h=: ...
- Android与Libgdx入门实例
本文讲解如何实现Android与Libgdx各自的Hello World过程. 1. Android版Hello World 点击Eclipse快捷方式,选择New Android Applicati ...
- MVC5.0知识点梳理
我们在使用MVC的时候或许总是在使用着自己一直熟悉的知识点去实现已有的功能,多梳理一些知识点让每种功能的实现方式可以多样化. 我们在开发小型系统时总是使用微软MVC的脚手架功能,比如路由可能就是使用了 ...
- 命令行启用IIS Express
我们在调试WEB程序的时候可以把本地web程序挂载到本地IIS,然后访问程序,通过附加进程的方式(w3wp)来调试程序(个人非常喜欢的一种调试方式),还有一种比较传统的方式就是通过VS自带的F5来执行 ...
- MIT-6.824 MapReduce
概述 MapReduce是由JeffreyDean提出的一种处理大数据的编程模型,用户定义map和reduce函数,map函数处理原始数据生成一系列键值对中间数据,reduce函数并合相同key的键值 ...
- PAT甲题题解-1111. Online Map (30)-PAT甲级真题(模板题,两次Dijkstra,同时记下最短路径)
题意:给了图,以及s和t,让你求s到t花费的最短路程.最短时间,以及输出对应的路径. 对于最短路程,如果路程一样,输出时间最少的. 对于最短时间,如果时间一样,输出节点数最少的. 如果最短路程 ...
- 20181204-2 Final发布
此作业要求参见:https://edu.cnblogs.com/campus/nenu/2018fall/homework/2476 小组介绍 组长:付佳 组员:张俊余 李文涛 孙赛佳 田良 于洋 段 ...
- Beta版本冲刺(三)
目录 组员情况 组员1(组长):胡绪佩 组员2:胡青元 组员3:庄卉 组员4:家灿 组员5:凯琳 组员6:翟丹丹 组员7:何家伟 组员8:政演 组员9:黄鸿杰 组员10:刘一好 组员11:何宇恒 展示 ...
- C#(近期目标)
最近很多同学为了实习都在学Java,但是我个人更偏好C#,首先因为自己基础不是太好,而C#又更容易入门,拥有比较完善的开发环境,是微软开发出来的语言.它吸收了C++和Java两门语言的所有有点,因为它 ...
- Alpha冲刺——测试随笔
写在前面 作业链接 测试工作安排 测试模块 用户登录 日常管理模块 项目展示模块 测试计划 用户登录 测试功能 测试项 输入/操作 检验点 预期效果 用户登录 登录动作 点击登录 报错提示 无法登录, ...