课程二(Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization),第一周(Practical aspects of Deep Learning) —— 4.Programming assignments:Gradient Checking
Gradient Checking
Welcome to this week's third programming assignment! You will be implementing gradient checking to make sure that your backpropagation implementation is correct. By completing this assignment you will:
- Implement gradient checking from scratch.
- Understand how to use the difference formula to check your backpropagation implementation.
- Recognize that your backpropagation algorithm should give you similar results as the ones you got by computing the difference formula.
- Learn how to identify which parameter's gradient was computed incorrectly.
Take your time to complete this assignment, and make sure you get the expected outputs when working through the different exercises. In some code blocks, you will find a "#GRADED FUNCTION: functionName" comment. Please do not modify it. After you are done, submit your work and check your results. You need to score 80% to pass. Good luck :) !
【中文翻译】
-从头开始执行梯度检查。
Gradient Checking
Welcome to the final assignment for this week! In this assignment you will learn to implement and use gradient checking.
You are part of a team working to make mobile payments available globally, and are asked to build a deep learning model to detect fraud--whenever someone makes a payment, you want to see if the payment might be fraudulent, such as if the user's account has been taken over by a hacker.
But backpropagation is quite challenging to implement, and sometimes has bugs. Because this is a mission-critical application, your company's CEO wants to be really certain that your implementation of backpropagation is correct. Your CEO says, "Give me a proof that your backpropagation is actually working!" To give this reassurance, you are going to use "gradient checking".
Let's do it!
# Packages
import numpy as np
from testCases import *
from gc_utils import sigmoid, relu, dictionary_to_vector, vector_to_dictionary, gradients_to_vector
1) How does gradient checking work?
Backpropagation computes the gradients , where θ denotes the parameters of the model. J is computed using forward propagation and your loss function.
, where θ denotes the parameters of the model. J is computed using forward propagation and your loss function.
Because forward propagation is relatively easy to implement, you're confident you got that right, and so you're almost 100% sure that you're computing the cost J correctly. Thus, you can use your code for computing J to verify the code for computing
Let's look back at the definition of a derivative (or gradient):

If you're not familiar with the  notation, it's just a way of saying "when ε is really really small."
notation, it's just a way of saying "when ε is really really small."
We know the following:
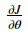 is what you want to make sure you're computing correctly.
is what you want to make sure you're computing correctly.- You can compute J(θ+ε)and J(θ−ε) (in the case that θ is a real number), since you're confident your implementation for J is correct.
Lets use equation (1) and a small value for ε to convince your CEO that your code for computing is correct!
2) 1-dimensional gradient checking
Consider a 1D linear function J(θ)=θx. The model contains only a single real-valued parameter(实值参数) θ, and takes x as input.
You will implement code to compute J(.)and its derivative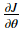 . You will then use gradient checking to make sure your derivative computation for J is correct.
. You will then use gradient checking to make sure your derivative computation for J is correct.

Figure 1 : 1D linear model
The diagram above shows the key computation steps: First start with x, then evaluate the function J(x)("forward propagation"). Then compute the derivative  ("backward propagation").
("backward propagation").
Exercise: implement "forward propagation" and "backward propagation" for this simple function. I.e.(即), compute both J(.) ("forward propagation") and its derivative with respect to ("backward propagation"), in two separate functions.
# GRADED FUNCTION: forward_propagation def forward_propagation(x, theta):
"""
Implement the linear forward propagation (compute J) presented in Figure 1 (J(theta) = theta * x) Arguments:
x -- a real-valued input
theta -- our parameter, a real number as well Returns:
J -- the value of function J, computed using the formula J(theta) = theta * x
""" ### START CODE HERE ### (approx. 1 line)
J = theta * x
### END CODE HERE ### return J
x, theta = 2, 4
J = forward_propagation(x, theta)
print ("J = " + str(J))
【result】
J = 8
Expected Output:
| J | 8 |

【code】
# GRADED FUNCTION: backward_propagation def backward_propagation(x, theta):
"""
Computes the derivative of J with respect to theta (see Figure 1). Arguments:
x -- a real-valued input
theta -- our parameter, a real number as well Returns:
dtheta -- the gradient of the cost with respect to theta
""" ### START CODE HERE ### (approx. 1 line)
dtheta = x
### END CODE HERE ### return dtheta
x, theta = 2, 4
dtheta = backward_propagation(x, theta)
print ("dtheta = " + str(dtheta))
【result】
dtheta = 2
Expected Output:
| dtheta | 2 |
backward_propagation() function is correctly computing the gradient 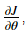 let's implement gradient checking.
let's implement gradient checking.
Instructions:
- First compute "gradapprox" using the formula above (1) and a small value of ε. Here are the Steps to follow:

- Then compute the gradient using backward propagation, and store the result in a variable "grad"
- Finally, compute the relative difference between "gradapprox" and the "grad" using the following formula:

- You will need 3 Steps to compute this formula:
- 1'. compute the numerator(分子) using np.linalg.norm(...)
- 2'. compute the denominator(分母). You will need to call np.linalg.norm(...) twice.
- 3'. divide them.
- If this difference is small (say less than 10−7), you can be quite confident that you have computed your gradient correctly. Otherwise, there may be a mistake in the gradient computation.
【code】
# GRADED FUNCTION: gradient_check def gradient_check(x, theta, epsilon = 1e-7):
"""
Implement the backward propagation presented in Figure 1. Arguments:
x -- a real-valued input
theta -- our parameter, a real number as well
epsilon -- tiny shift to the input to compute approximated gradient with formula(1) Returns:
difference -- difference (2) between the approximated gradient and the backward propagation gradient
""" # Compute gradapprox using left side of formula (1). epsilon is small enough, you don't need to worry about the limit.
### START CODE HERE ### (approx. 5 lines)
thetaplus = theta + epsilon # Step 1
thetaminus = theta - epsilon # Step 2
J_plus = thetaplus * x # Step 3
J_minus = thetaminus * x # Step 4
gradapprox =( J_plus - J_minus)/ (2*epsilon ) # Step 5
### END CODE HERE ### # Check if gradapprox is close enough to the output of backward_propagation()
### START CODE HERE ### (approx. 1 line)
grad = backward_propagation(x, theta)### END CODE HERE ### ### START CODE HERE ### (approx. 1 line)
numerator = np.linalg.norm(grad - gradapprox) # Step 1' numpy.linalg.norm的用法:https://docs.scipy.org/doc/numpy/reference/generated/numpy.linalg.norm.html
denominator =np.linalg.norm(grad)+np.linalg.norm( gradapprox) # Step 2'
difference = numerator/ denominator # Step 3'
### END CODE HERE ### if difference < 1e-7:
print ("The gradient is correct!")
else:
print ("The gradient is wrong!") return difference
x, theta = 2, 4
difference = gradient_check(x, theta)
print("difference = " + str(difference))
【result】
The gradient is correct!
difference = 2.91933588329e-10
Expected Output: The gradient is correct!
| difference | 2.9193358103083e-10 |
Congrats, the difference is smaller than the 10−7 threshold. So you can have high confidence that you've correctly computed the gradient in backward_propagation().
Now, in the more general case, your cost function J has more than a single 1D input. When you are training a neural network, θ actually consists of multiple matrices W[l] and biases b[l]! It is important to know how to do a gradient check with higher-dimensional inputs. Let's do it!
3) N-dimensional gradient checking
The following figure describes the forward and backward propagation of your fraud detection (欺诈检验) model.
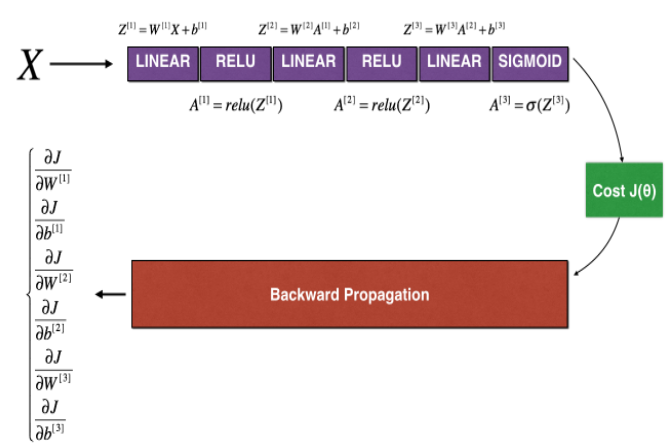
Figure 2 : deep neural network
LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID
Let's look at your implementations (实现) for forward propagation and backward propagation.
【code】
def forward_propagation_n(X, Y, parameters):
"""
Implements the forward propagation (and computes the cost) presented in Figure 2. Arguments:
X -- training set for m examples
Y -- labels for m examples
parameters -- python dictionary containing your parameters "W1", "b1", "W2", "b2", "W3", "b3":
W1 -- weight matrix of shape (5, 4)
b1 -- bias vector of shape (5, 1)
W2 -- weight matrix of shape (3, 5)
b2 -- bias vector of shape (3, 1)
W3 -- weight matrix of shape (1, 3)
b3 -- bias vector of shape (1, 1) Returns:
cost -- the cost function (logistic cost for one example)
""" # retrieve (检索)parameters
m = X.shape[1]
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
W3 = parameters["W3"]
b3 = parameters["b3"] # LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID
Z1 = np.dot(W1, X) + b1
A1 = relu(Z1)
Z2 = np.dot(W2, A1) + b2
A2 = relu(Z2)
Z3 = np.dot(W3, A2) + b3
A3 = sigmoid(Z3) # Cost
logprobs = np.multiply(-np.log(A3),Y) + np.multiply(-np.log(1 - A3), 1 - Y)
cost = 1./m * np.sum(logprobs) cache = (Z1, A1, W1, b1, Z2, A2, W2, b2, Z3, A3, W3, b3) return cost, cache
Now, run backward propagation.
def backward_propagation_n(X, Y, cache):
"""
Implement the backward propagation presented in figure 2. Arguments:
X -- input datapoint, of shape (input size, 1)
Y -- true "label"
cache -- cache output from forward_propagation_n() Returns:
gradients -- A dictionary with the gradients of the cost with respect to each parameter, activation and pre-activation variables.
""" m = X.shape[1]
(Z1, A1, W1, b1, Z2, A2, W2, b2, Z3, A3, W3, b3) = cache dZ3 = A3 - Y
dW3 = 1./m * np.dot(dZ3, A2.T)
db3 = 1./m * np.sum(dZ3, axis=1, keepdims = True) dA2 = np.dot(W3.T, dZ3)
dZ2 = np.multiply(dA2, np.int64(A2 > 0))
dW2 = 1./m * np.dot(dZ2, A1.T) * 2 # ??? 此处有错误,应该为 dW2 = 1./m * np.dot(dZ2, A1.T)
db2 = 1./m * np.sum(dZ2, axis=1, keepdims = True) dA1 = np.dot(W2.T, dZ2)
dZ1 = np.multiply(dA1, np.int64(A1 > 0))
dW1 = 1./m * np.dot(dZ1, X.T)
db1 = 4./m * np.sum(dZ1, axis=1, keepdims = True) # ??? 此处有错误,应该为 db1 = 1./m * np.sum(dZ1, axis=1, keepdims = True) gradients = {"dZ3": dZ3, "dW3": dW3, "db3": db3,
"dA2": dA2, "dZ2": dZ2, "dW2": dW2, "db2": db2,
"dA1": dA1, "dZ1": dZ1, "dW1": dW1, "db1": db1} return gradients
You obtained some results on the fraud detection test set but you are not 100% sure of your model. Nobody's perfect! Let's implement gradient checking to verify if your gradients are correct.
How does gradient checking work?.
As in 1) and 2), you want to compare "gradapprox" to the gradient computed by backpropagation. The formula is still:

However, θ is not a scalar anymore. It is a dictionary called "parameters". We implemented a function "dictionary_to_vector()" for you. It converts the "parameters" dictionary into a vector called "values", obtained by reshaping all parameters (W1, b1, W2, b2, W3, b3) into vectors and concatenating them(通过将所有参数 (W1、b1、W2、b2、W3、b3) 重新整形, 并将它们串联起来。).
The inverse function is "vector_to_dictionary" which outputs back the "parameters" dictionary.
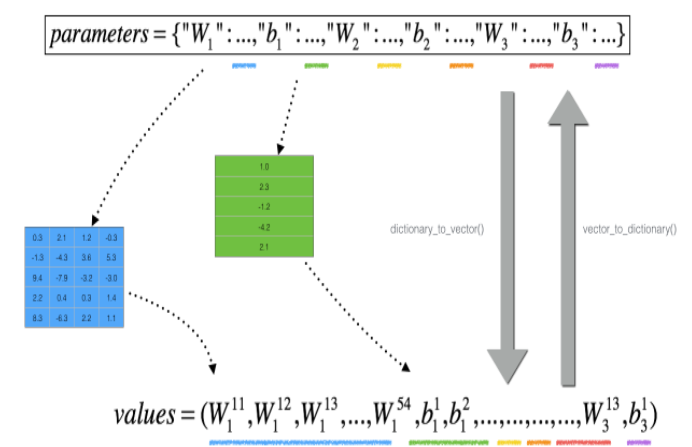
Figure 2 : dictionary_to_vector() and vector_to_dictionary()
You will need these functions in gradient_check_n()
We have also converted the "gradients" dictionary into a vector "grad" using gradients_to_vector(). You don't need to worry about that.
Exercise: Implement gradient_check_n().
Instructions: Here is pseudo-code(伪代码) that will help you implement the gradient check.
For each i in num_parameters:

Thus, you get a vector gradapprox, where gradapprox[i] is an approximation of the gradient with respect to parameter_values[i]. You can now compare this gradapprox vector to the gradients vector from backpropagation. Just like for the 1D case (Steps 1', 2', 3'), compute:

【code】
# GRADED FUNCTION: gradient_check_n def gradient_check_n(parameters, gradients, X, Y, epsilon = 1e-7):
"""
Checks if backward_propagation_n computes correctly the gradient of the cost output by forward_propagation_n Arguments:
parameters -- python dictionary containing your parameters "W1", "b1", "W2", "b2", "W3", "b3":
grad -- output of backward_propagation_n, contains gradients of the cost with respect to the parameters.
X -- input datapoint, of shape (input size, 1)
Y -- true "label"
epsilon -- tiny shift to the input to compute approximated gradient with formula(1) Returns:
difference -- difference (2) between the approximated gradient and the backward propagation gradient
""" # Set-up variables
parameters_values, _ = dictionary_to_vector(parameters)
grad = gradients_to_vector(gradients)
num_parameters = parameters_values.shape[0] # ??? num_parameters应该是列向量,图2中是行向量
J_plus = np.zeros((num_parameters, 1))
J_minus = np.zeros((num_parameters, 1))
gradapprox = np.zeros((num_parameters, 1)) # Compute gradapprox
for i in range(num_parameters): # Compute J_plus[i]. Inputs: "parameters_values, epsilon". Output = "J_plus[i]".
# "_" is used because the function you have to outputs two parameters but we only care about the first one
### START CODE HERE ### (approx. 3 lines)
thetaplus = np.copy(parameters_values) # Step 1
thetaplus[i][0] = thetaplus[i][0]+ epsilon # Step 2
J_plus[i], _ = forward_propagation_n(X, Y, vector_to_dictionary( thetaplus )) # Step 3
### END CODE HERE ### # Compute J_minus[i]. Inputs: "parameters_values, epsilon". Output = "J_minus[i]".
### START CODE HERE ### (approx. 3 lines)
thetaminus = np.copy(parameters_values) # Step 1
thetaminus[i][0] = thetaminus[i][0]- epsilon # Step 2
J_minus[i], _ = forward_propagation_n(X, Y, vector_to_dictionary( thetaminus )) # Step 3
### END CODE HERE ### # Compute gradapprox[i]
### START CODE HERE ### (approx. 1 line)
gradapprox[i] = ( J_plus[i]- J_minus[i])/ (2*epsilon )
### END CODE HERE ### # Compare gradapprox to backward propagation gradients by computing difference.
### START CODE HERE ### (approx. 1 line)
numerator = np.linalg.norm(grad - gradapprox) # Step 1'
denominator = np.linalg.norm(grad)+np.linalg.norm( gradapprox) # Step 2'
difference =numerator / denominator # Step 3'
### END CODE HERE ### if difference > 2e-7:
print ("\033[93m" + "There is a mistake in the backward propagation! difference = " + str(difference) + "\033[0m")
else:
print ("\033[92m" + "Your backward propagation works perfectly fine! difference = " + str(difference) + "\033[0m") return difference
X, Y, parameters = gradient_check_n_test_case() cost, cache = forward_propagation_n(X, Y, parameters)
gradients = backward_propagation_n(X, Y, cache)
difference = gradient_check_n(parameters, gradients, X, Y)
【result】
here is a mistake in the backward propagation! difference = 0.285093156781
Expected output:
| There is a mistake in the backward propagation! | difference = 0.285093156781 |
It seems that there were errors in the backward_propagation_n code we gave you! Good that you've implemented the gradient check. Go back to backward_propagation and try to find/correct the errors (Hint: check dW2 and db1). Rerun the gradient check when you think you've fixed it. Remember you'll need to re-execute the cell defining backward_propagation_n() if you modify the code.
Can you get gradient check to declare your derivative computation correct? Even though this part of the assignment isn't graded, we strongly urge you to try to find the bug and re-run gradient check until you're convinced backprop is now correctly implemented.
Note
- Gradient Checking is slow! Approximating (逼近)the gradient with
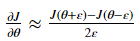 is computationally costly. For this reason, we don't run gradient checking at every iteration during training. Just a few times to check if the gradient is correct.
is computationally costly. For this reason, we don't run gradient checking at every iteration during training. Just a few times to check if the gradient is correct. - Gradient Checking, at least as we've presented it(至少正如我们所介绍的), doesn't work with dropout. You would usually run the gradient check algorithm without dropout to make sure your backprop is correct, then add dropout.
Congrats, you can be confident that your deep learning model for fraud detection is working correctly! You can even use this to convince your CEO. :)
What you should remember from this notebook:
- Gradient checking verifies closeness between the gradients from backpropagation and the numerical approximation of the gradient (computed using forward propagation).
- Gradient checking is slow, so we don't run it in every iteration of training. You would usually run it only to make sure your code is correct, then turn it off and use backprop for the actual learning process.
【中文翻译】
您应该记住的:
课程二(Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization),第一周(Practical aspects of Deep Learning) —— 4.Programming assignments:Gradient Checking的更多相关文章
- 吴恩达《深度学习》-课后测验-第二门课 (Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization)-Week 1 - Practical aspects of deep learning(第一周测验 - 深度学习的实践)
Week 1 Quiz - Practical aspects of deep learning(第一周测验 - 深度学习的实践) \1. If you have 10,000,000 example ...
- 吴恩达《深度学习》-第二门课 (Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization)-第一周:深度学习的实践层面 (Practical aspects of Deep Learning) -课程笔记
第一周:深度学习的实践层面 (Practical aspects of Deep Learning) 1.1 训练,验证,测试集(Train / Dev / Test sets) 创建新应用的过程中, ...
- 《Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization》课堂笔记
Lesson 2 Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization 这篇文章其 ...
- [C4] Andrew Ng - Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization
About this Course This course will teach you the "magic" of getting deep learning to work ...
- Coursera Deep Learning 2 Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization - week1, Assignment(Initialization)
声明:所有内容来自coursera,作为个人学习笔记记录在这里. Initialization Welcome to the first assignment of "Improving D ...
- Coursera, Deep Learning 2, Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization - week1, Course
Train/Dev/Test set Bias/Variance Regularization 有下面一些regularization的方法. L2 regularation drop out da ...
- 课程二(Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization),第二周(Optimization algorithms) —— 2.Programming assignments:Optimization
Optimization Welcome to the optimization's programming assignment of the hyper-parameters tuning spe ...
- 课程二(Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization),第三周(Hyperparameter tuning, Batch Normalization and Programming Frameworks) —— 2.Programming assignments
Tensorflow Welcome to the Tensorflow Tutorial! In this notebook you will learn all the basics of Ten ...
- Coursera Deep Learning 2 Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization - week2, Assignment(Optimization Methods)
声明:所有内容来自coursera,作为个人学习笔记记录在这里. 请不要ctrl+c/ctrl+v作业. Optimization Methods Until now, you've always u ...
随机推荐
- keras backend的修改
方法一: vim .keras/keras.json 修改“backend”:"tensorflow" 方法二: 每次在python文档中输入, import os os.envi ...
- 关于CSS的优先级,CSS优先级计算,多个class引用
原则一: 继承不如指定 原则二: #id > .class > 标签选择符 原则三:越具体越强大 原则四:标签#id >#id ; 标签.class > .class CSS优 ...
- 模块import,from ..import...
首次导入模块发生3件事 1.创建一个模块的名称空间 2.执行文件spam.py,将执行过程中产生的名字都放到模块的名称空间中 3.在当前执行文件中直接拿到一个名字,该名字就是执行模块中相对应的名字 f ...
- What's New In Python 3.X
As Python updating to python 3.6, its performance is better than Python 2.x, which is good news to e ...
- C++二级指针第一种内存模型(指针数组)
二级指针第一种内存模型(指针数组) 指针的输入特性:在主调函数里面分配内存,在被调用函数里面使用指针的输出特性:在被调用函数里面分配内存,主要是把运算结果甩出来 指针数组 在C语言和C++语言中,数组 ...
- (转)WAMP多站点配置
转自:http://wislab.net/archives/43.html Wamp正在被广泛使用,其傻瓜式的安装配置,使得我们可以得心应手地完成以往较为烦琐的服务器环境搭建过程,直接进入到网页程序的 ...
- noip第2课资料
- 12.equals()方法总结
超类Object中有这个equals()方法,该方法主要用于比较两个对象是否相等.该方法的源码如下: 我们知道所有对象都有表示(内存地址)和状态(数据),看上面代码是用"=="来比 ...
- [au3]复制选择性粘贴文本到excel
案例:在一张网页上有许多你要复制的内容,但是你必须一个一个找到他们,然后一个一个复制出来粘贴到excel表格里.时间一长你的眼睛容易花,而且复制多了容易出错. 方法:当然有许多方法可以自动化的做这一件 ...
- php支持连接sqlserver数据库
php支持连接sqlserver数据库 1.软件配置 Win7 64 +wampserver2.2d-x32+SQL Server 2008 R2数据库,wamp2.2中的php版本是5.3.10. ...