MapReduce之WritableComparable排序
@
排序概述
- 排序是MapReduce框架中最重要的操作之一。
- Map Task和ReduceTask均会默认对数据按照key进行排序。该操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。
- 黑默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。
- 对于
MapTask,它会将处理的结果暂时放到一个缓冲区中,当缓冲区使用率达到一定阈值后,再对缓冲区中的数据进行一次排序,并将这些有序数据写到磁盘上,而当数据处理完毕后,它会对磁盘上所有文件进行一次合并,以将这些文件合并成一个大的有序文件。 - 对于
ReduceTask,它从每个MapTak上远程拷贝相应的数据文件,如果文件大小超过一定阑值,则放到磁盘上,否则放到内存中。如果磁盘上文件数目达到一定阈值,则进行一次合并以生成一个更大文件;如果内存中文件大小或者数目超过一定阈值,则进行一次合并后将数据写到磁盘上。当所有数据拷贝完毕后,ReduceTask统一对内存和磁盘上的所有数据进行一次归并排序。 - 排序器:排序器影响的是排序的速度(效率,对什么排序?),QuickSorter
- 比较器:比较器影响的是排序的结果(按照什么规则排序)
获取Mapper输出的key的比较器(源码)
public RawComparator getOutputKeyComparator() {
// 从配置中获取mapreduce.job.output.key.comparator.class的值,必须是RawComparator类型,如果没有配置,默认为null
Class<? extends RawComparator> theClass = getClass(JobContext.KEY_COMPARATOR, null, RawComparator.class);
// 一旦用户配置了此参数,实例化一个用户自定义的比较器实例
if (theClass != null){
return ReflectionUtils.newInstance(theClass, this);
}
//用户没有配置,判断Mapper输出的key的类型是否是WritableComparable的子类,如果不是,就抛异常,如果是,系统会自动为我们提供一个key的比较器
return WritableComparator.get(getMapOutputKeyClass().asSubclass(WritableComparable.class), this);
}
案例实操(区内排序)
需求
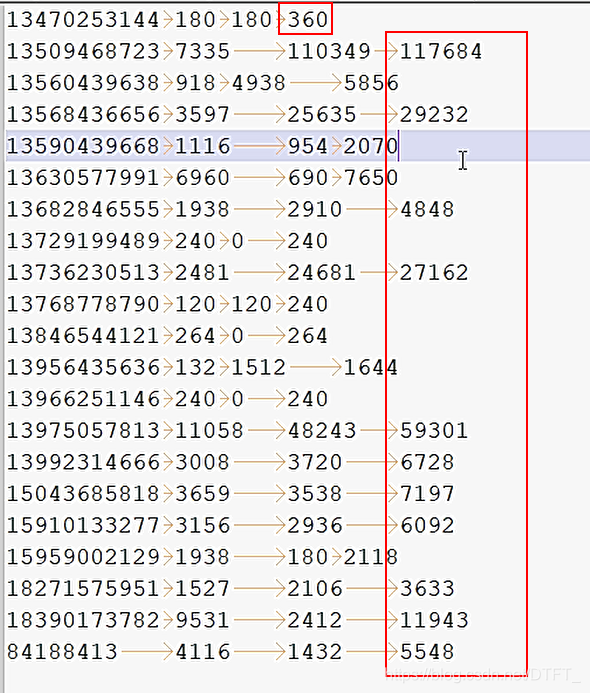
对每个手机号按照上行流量和下行流量的总和进行内部排序。
思考
因为Map Task和ReduceTask均会默认对数据按照key进行排序,所以需要把流量总和设置为Key,手机号等其他内容设置为value
FlowBeanMapper.java
public class FlowBeanMapper extends Mapper<LongWritable, Text, LongWritable, Text>{
private LongWritable out_key=new LongWritable();
private Text out_value=new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.toString().split("\t");
//封装总流量为key
out_key.set(Long.parseLong(words[3]));//切分后,流量和的下标为3
//封装其他内容为value
out_value.set(words[0]+"\t"+words[1]+"\t"+words[2]);
context.write(out_key, out_value);
}
}
FlowBeanReducer.java
public class FlowBeanReducer extends Reducer<LongWritable, Text, Text, LongWritable>{
@Override
protected void reduce(LongWritable key, Iterable<Text> values,
Reducer<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException {
for (Text value : values) {
context.write(value, key);
}
}
}
FlowBeanDriver.java
public class FlowBeanDriver {
public static void main(String[] args) throws Exception {
Path inputPath=new Path("E:\\mroutput\\flowbean");
Path outputPath=new Path("e:/mroutput/flowbeanSort1");
//作为整个Job的配置
Configuration conf = new Configuration();
//保证输出目录不存在
FileSystem fs=FileSystem.get(conf);
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
// ①创建Job
Job job = Job.getInstance(conf);
// ②设置Job
// 设置Job运行的Mapper,Reducer类型,Mapper,Reducer输出的key-value类型
job.setMapperClass(FlowBeanMapper.class);
job.setReducerClass(FlowBeanReducer.class);
// Job需要根据Mapper和Reducer输出的Key-value类型准备序列化器,通过序列化器对输出的key-value进行序列化和反序列化
// 如果Mapper和Reducer输出的Key-value类型一致,直接设置Job最终的输出类型
//由于Mapper和Reducer输出的Key-value类型不一致(maper输出类型是long-text,而reducer是text-value)
//所以需要额外设定
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 设置输入目录和输出目录
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
// 默认升序排,可以设置使用自定义的比较器
//job.setSortComparatorClass(DecreasingComparator.class);
// ③运行Job
job.waitForCompletion(true);
}
}
运行结果(默认升序排)
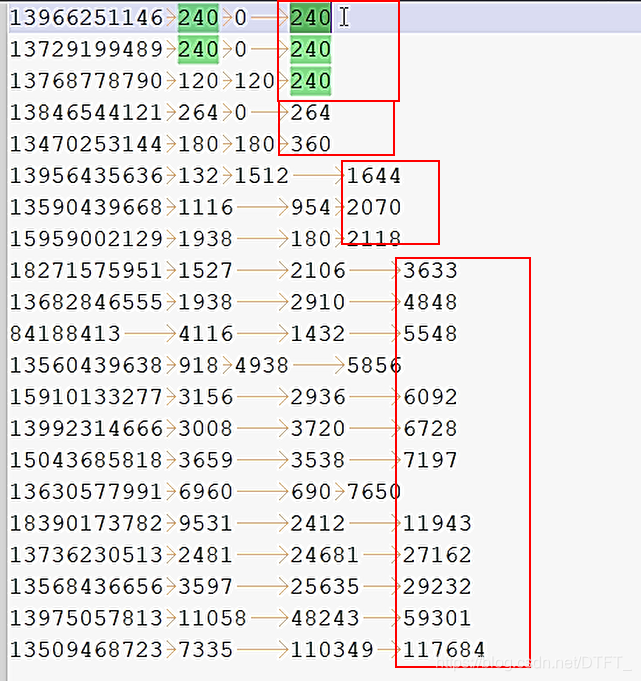
自定义排序器,使用降序
方法一:自定义类,这个类必须是
RawComparator类型,通过设置mapreduce.job.output.key.comparator.class自定义的类的类型。
自定义类时,可以继承WriableComparator类,也可以实现RawCompartor
调用方法时,先调用RawCompartor. compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2),再调用RawCompartor.compare()方法二:定义Mapper输出的key,让key实现
WritableComparable,实现CompareTo()
MyDescComparator.java
public class MyDescComparator extends WritableComparator{
@Override
public int compare(byte[] b1, int s1, int l1,byte[] b2, int s2, int l2) {
long thisValue = readLong(b1, s1);
long thatValue = readLong(b2, s2);
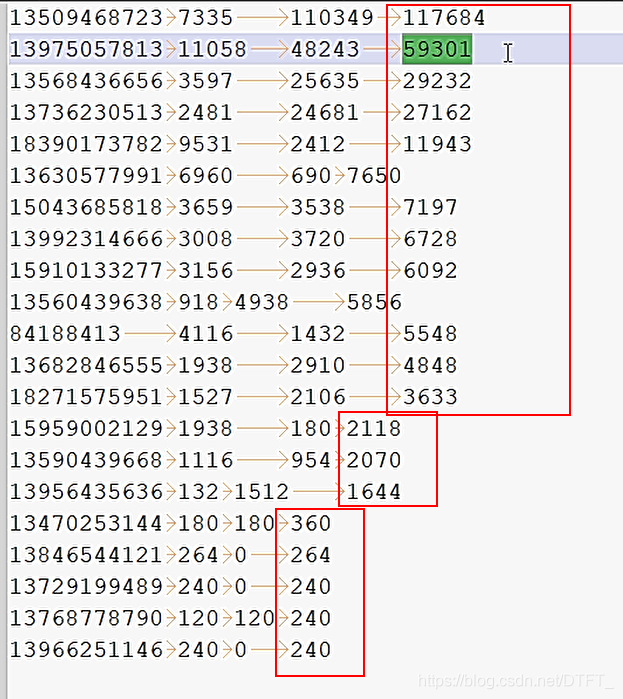
//这里把第一个-1改成1,把第二个1改成-1,就是降序排
return (thisValue<thatValue ? 1 : (thisValue==thatValue ? 0 : -1));
}
}
运行结果
MapReduce之WritableComparable排序的更多相关文章
- Hadoop(18)-MapReduce框架原理-WritableComparable排序和GroupingComparator分组
1.排序概述 2.排序分类 3.WritableComparable案例 这个文件,是大数据-Hadoop生态(12)-Hadoop序列化和源码追踪的输出文件,可以看到,文件根据key,也就是手机号进 ...
- Hadoop学习笔记—11.MapReduce中的排序和分组
一.写在之前的 1.1 回顾Map阶段四大步骤 首先,我们回顾一下在MapReduce中,排序和分组在哪里被执行: 从上图中可以清楚地看出,在Step1.4也就是第四步中,需要对不同分区中的数据进行排 ...
- Hadoop学习笔记: MapReduce二次排序
本文给出一个实现MapReduce二次排序的例子 package SortTest; import java.io.DataInput; import java.io.DataOutput; impo ...
- (转)MapReduce二次排序
一.概述 MapReduce框架对处理结果的输出会根据key值进行默认的排序,这个默认排序可以满足一部分需求,但是也是十分有限的.在我们实际的需求当中,往往有要对reduce输出结果进行二次排序的需求 ...
- 详细讲解MapReduce二次排序过程
我在15年处理大数据的时候还都是使用MapReduce, 随着时间的推移, 计算工具的发展, 内存越来越便宜, 计算方式也有了极大的改变. 到现在再做大数据开发的好多同学都是直接使用spark, hi ...
- mapreduce数据处理——统计排序
接上篇https://www.cnblogs.com/sengzhao666/p/11850849.html 2.数据处理: ·统计最受欢迎的视频/文章的Top10访问次数 (id) ·按照地市统计最 ...
- mapreduce 实现数子排序
设计思路: 使用mapreduce的默认排序,按照key值进行排序的,如果key为封装int的IntWritable类型,那么MapReduce按照数字大小对key排序,如果key为封装为String ...
- MapReduce二次排序
默认情况下,Map 输出的结果会对 Key 进行默认的排序,但是有时候需要对 Key 排序的同时再对 Value 进行排序,这时候就要用到二次排序了.下面让我们来介绍一下什么是二次排序. 二次排序原理 ...
- Hadoop MapReduce 二次排序原理及其应用
关于二次排序主要涉及到这么几个东西: 在0.20.0 以前使用的是 setPartitionerClass setOutputkeyComparatorClass setOutputValueGrou ...
随机推荐
- Spring 容器的初始化
读完这篇文章你将会收获到 了解到 Spring 容器初始化流程 ThreadLocal 在 Spring 中的最佳实践 面试中回答 Spring 容器初始化流程 引言 我们先从一个简单常见的代码入手分 ...
- Docker(六)容器数据卷
容器数据卷 docker的理念回顾 将应用和环境打包成一个镜像 需求:数据可以持久化和同步 使用数据卷 指定路径挂载 docker run -it -v 主机目录:容器内目录 # 测试 [root@h ...
- 服务消费者(Ribbon)
上一篇文章,简单概述了服务注册与发现,在微服务架构中,业务都会被拆分成一个独立的服务,服务之间的通讯是基于http restful的,Ribbon可以很好地控制HTTP和TCP客户端的行为,Sprin ...
- 手写SpringMVC框架(三)-------具体方法的实现
续接前文 手写SpringMVC框架(二)结构开发设计 本节我们来开始具体方法的代码实现. doLoadConfig()方法的开发 思路:我们需要将contextConfigLocation路径读取过 ...
- day33 网络编程(下)
目录 上节课回顾: 一.传输层 二.应用层 三.socket 四.如何获取目标ip地址 五.网络通信的流程 上节课回顾: 通过ip地址如何找到另外一台设备 ip地址分为子网部分和主机部分 我们要和其他 ...
- shell专题(一):Shell概述
大数据程序员为什么要学习Shell呢? 1)需要看懂运维人员编写的Shell程序. 2)偶尔会编写一些简单Shell程序来管理集群.提高开发效
- 爬虫页面解析 lxml 简单教程
一.与字符串的相互转换 1.字符串转变为etree 对象 import lxml.html tree = lxml.html.fromstring(content) # content 字符串对象 2 ...
- 数据可视化之powerBI入门(二)体验PowerBI:零基础分分钟生成一份交互报表
https://zhuanlan.zhihu.com/p/64144595 体验PowerBI:零基础分分钟生成一份交互报表 首先我们准备一份数据,Excel格式 数据是从2006年到2015年10年 ...
- 使用Python进行自动化测试
目前大家对Python都有一个共识,就是他对测试非常有用,自动化测试里Python用途也很广,但是Python到底怎么进行自动化测试呢?今天就简单的向大家介绍一下怎么使用Python进行自动化测试,本 ...
- javascript原型:写一个合并后数组去掉同类项的方法
<!DOCTYPE html> <html> <head> <title>test013_Array_prototype_unique()</ti ...