Python爬取网站上面的数据很简单,但是如何爬取APP上面的数据呢
![]()
前言
在我们在爬取手机APP上面的数据的时候,都会借助Fidder来爬取。今天就教大家如何爬取手机APP上面的数据。
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:1097524789
环境配置
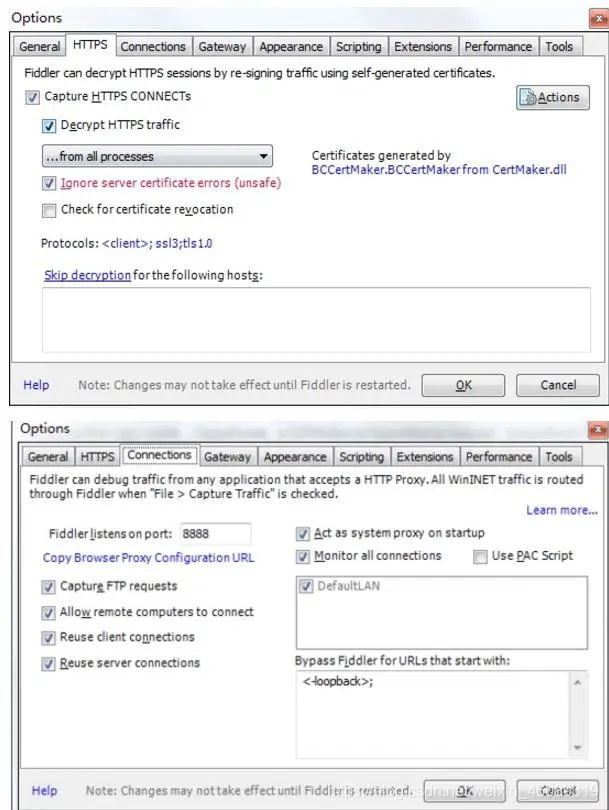
1、Fidder的安装和配置
下载Fidder软件地址:https://www.telerik.com/download/fiddler
然后就是傻瓜式的安装,安装步骤很简单。在安装完成后,打开软件,进行如下设置:
默认的8888端口
![]()
2、手机的配置
首先打开cmd,输入ipconfig查看IP地址,记录下这个IP地址:
![]()
想要使用FIdder进行手机抓包,要让手机和PC处在同一个内网中,方法就是连接同一个无线网络。然后打开手机,进入Wi-FI设置修改代理为手动代理,再把上面的IP地址和8888端口号输入进去:
![]()
然后打开浏览器,输入http://127.0.0.1:8888,会看到如下界面,点击FidderRoot certificate下载证书:
![]()
下载好之后如果出现无法安装的情况,可以进入设置进行手动安装证书,我的安装步骤是“设置->系统安全->从SD卡安装”,不同的手机安装步骤不同,不过也差不多吧。
3、抓包测试
在完成上面的步骤之后,我们先进行一下抓包测试,打开手机的浏览器,然后打开百度的网页,可以看到出现了对应的包,这样就可以进行之后的抓取了。
![]()
抓取步骤
这次使用的APP是王者荣耀盒子,打开APP,点击英雄,可以看到第一个英雄-上官婉儿,然后点进去。
![]()
然后在Fidder中可以找到如下这个包:
![]()
然后在右侧可以看到如下信息:
![]()
把这些信息复制一下,然后解码一下就可以看到如下数据了,包括英雄名字、英雄图片、英雄技能等信息:
![]()
但是在推荐装备的信息里,只有装备的id值,却没有装备的名字,那我们要怎么获得这些装备的名字呢?还是同样的办法,点击查看所有装备,然后抓包,找到对应的包,再进行爬取。在获得所有的装备和对应的id后,可以再爬取所有的英雄名称,然后就可以制作我们自己的英雄攻略了==
运行结果如下:
![]()
完整代码
![]()
Python爬取网站上面的数据很简单,但是如何爬取APP上面的数据呢的更多相关文章
- ORM取数据很简单!是吗?
简介 几乎任何系统都以某种方式与外部数据存储一起运行.大多数情况下,外部数据存储是一个关系数据库,并且在实现时通常将数据提取任务委托给某些 ORM. 尽管 ORM 包含很多 routine 代码,但是 ...
- 轻松搞定Ajax(分享下自己封装ajax函数,其实Ajax使用很简单,难是难在你得到数据后来怎样去使用这些数据)
hey,guys!今天我们一起讨论下ajax吧!此文只适合有一定ajax基础,但还是模糊状态的同志,当然高手也可以略过~~~ 一.概念 Ajax(Asynchronous Javascript + X ...
- POI导出大量数据的简单解决方案(附源码)-Java-POI导出大量数据,导出Excel文件,压缩ZIP(转载自iteye.com)
说明:我的电脑 2.0CPU 2G内存 能够十秒钟导出 20W 条数据 ,12.8M的excel内容压缩后2.68M 我们知道在POI导出Excel时,数据量大了,很容易导致内存溢出.由于Excel ...
- webmagic 二次开发爬虫 爬取网站图片
webmagic的是一个无须配置.便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫. webmagic介绍 编写一个简单的爬虫 webmagic的使用文档:http://w ...
- Python爬虫入门教程 47-100 mitmproxy安装与安卓模拟器的配合使用-手机APP爬虫部分
1. 准备下载软件 介绍一款爬虫辅助工具mitmproxy ,mitmproxy 就是用于MITM的proxy,MITM中间人攻击.说白了就是服务器和客户机中间通讯多增加了一层.跟Fiddler和Ch ...
- UWP开发:APP之间的数据交互(以微信为例)
目录 说明 UWP应用唤醒方式 跟微信APP交互数据 APP之间交互数据的前提 说明 我们经常看到,在手机上不需要退到桌面,APP之间就可以相互切换,并且可以传递数据.比如我在使用知乎APP的时候,需 ...
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
- python爬取网站数据保存使用的方法
这篇文章主要介绍了使用Python从网上爬取特定属性数据保存的方法,其中解决了编码问题和如何使用正则匹配数据的方法,详情看下文 编码问题因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这 ...
- python获取动态网站上面的动态加载的数据(初级)
我们在处理一些网站数据的时候,有时候我们需要的数据很多都是动态加载的,而不都是静态的,以下以一个实例来介绍简单的获取动态数据,首先申明本人小白,还在学习python中,这个方法还是比较笨拙的,但是对于 ...
随机推荐
- nginx配置使用, 入门到实践
1. 本文做自己学习配置使用, 转自: https://mp.weixin.qq.com/s?__biz=Mzg2MjEwMjI1Mg%3D%3D&chksm=ce0dae4df97a275b ...
- Viper解析&加载配置
Viper解析&加载配置 1 Viper是什么 Viper是一个方便Go语言应用程序处理配置信息的库.它可以处理多种格式的配置.它支持的特性: 设置默认值 从JSON.TOML.YAML ...
- js获取url并截取相应的字段,js解决url获取中文字段乱码问题
相信url截取信息是一个很常用的小功能页面跳转传参的时候可以在A页面的url挂一些参数到B页面获取正常的页面传参都是以数字和英文为主正常情况下中文获取的时候是有乱码的所谓上有政策下有对策一个正常的ur ...
- Ethical Hacking - Web Penetration Testing(3)
EXPLOITATION -File Upload VULNS Simple type of vulnerabilities. Allow users to upload executable fil ...
- nc - 网络工具箱中的「瑞士军刀」
nc 是 Linux下强大的网络命令行工具,主要用于 TCP.UDP.UNIX域套接字 相关的操作 它被设计成可以由其他程序灵活驱动可靠的后台工具,拥有 "瑞士军刀" 的美称,每个 ...
- super,this关键字用法 Java
super 用法 1.调用父类变量2.调用父类方法3.子类构造方法第一句 this 用法 super关键字用来访问父类内容, this 关键字用来访问本类中的内容, 有三种用法 1.在本类的成员方法中 ...
- 做软件测试要月入20k?听听腾讯大牛怎么说
作者:兰色链接:https://www.zhihu.com/question/373819487/answer/1183309514来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请 ...
- Unable to find a constructor that takes a String param or a valueOf() or fromString() method
Unable to find a constructor that takes a String param or a valueOf() or fromString() method 最近在做服务的 ...
- 说出来也许你不信,我被 Linux 终端嘲笑了……
人这一辈子,真的是非常不容易:读书时,被老师.同学嘲笑,工作时,被老板.同事嘲笑,就连出去撸个串儿,还可能被朋友嘲笑-- 这些也就算了,毕竟大家还都是同类,都是活生生的人.但是,你如果被 Linux ...
- gitlab的还原
源服务器: ip: 192.168.0.199 系统:CentOS7.2 内核: 3.10.0-327 gitlab版本: gitlab-ce-8.0.5 新服务器: ip: 192.168.0.19 ...