操作系统:x86下内存分页机制 (1)
前置知识:
分段的概念(当然手写过肯定是坠吼的
为什么要分页
当我们写程序的时候,总是倾向于把一个完整的程序分成最基本的数据段,代码段,栈段。并且普通的分段机制就是在进程所属的LDT中把每一个段给标识出来。但是在实际运用中,大多数进程不会无限地运行下去。当进程结束之后它占有的内存空间也会被释放。但是这样就会出现一个问题:内存碎片导致的内存使用效率低下
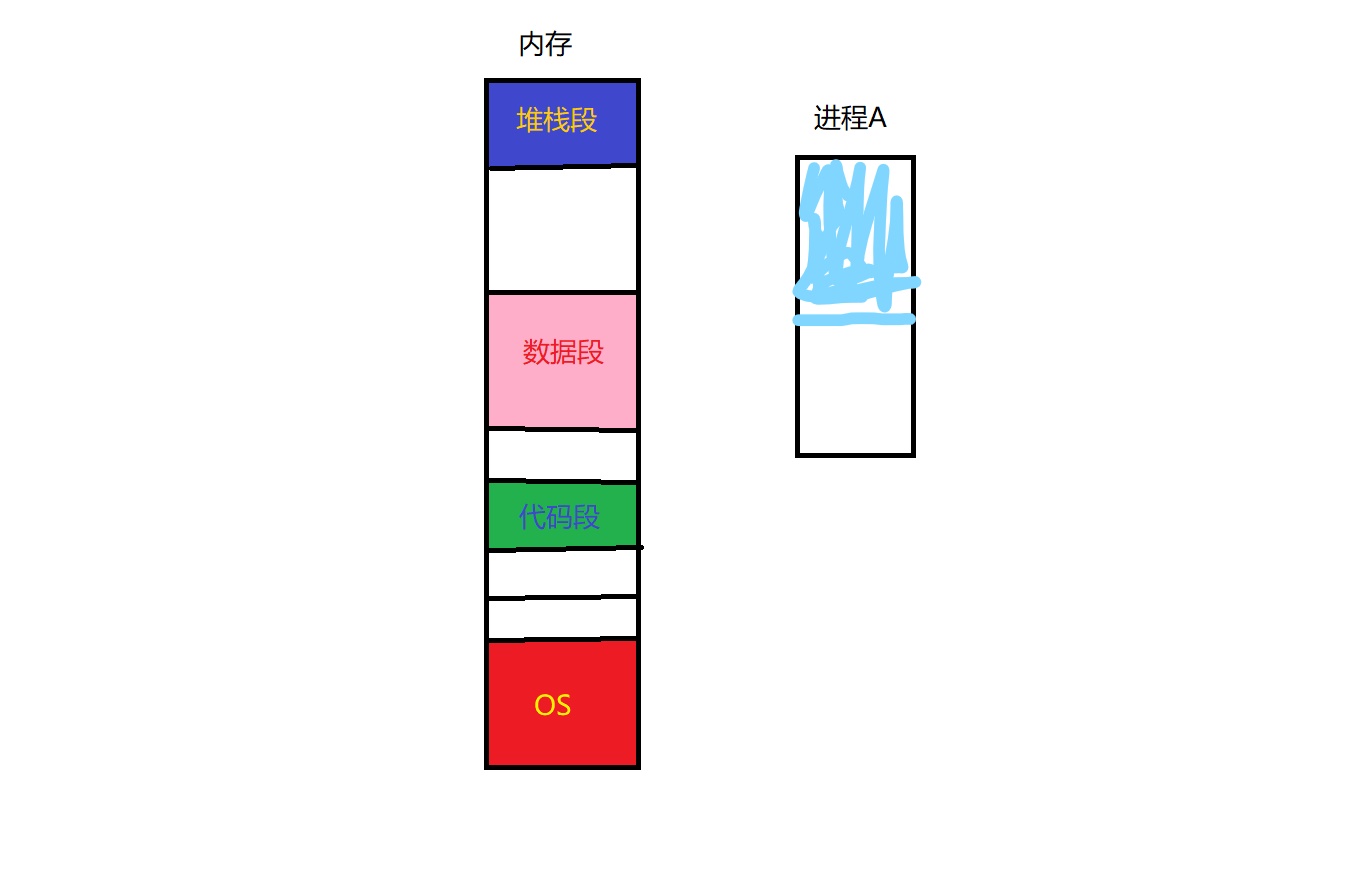
当进程A准备载入内存的时候,实际上内存的总剩余空间是足够放下的。但是进程A中的蓝色段无法直接放入内存中(假设这一段是代码段)。也就是说我们必须等待内存中的进程被释放的时候才能载入进程A。很明显,等待的工作是非常令人厌烦的,所以我们必须得想出一种办法可以避免这种等待。
分页基本思想
其实我们可以类比分段的思想——分段其实是站在程序员的角度来解读程序:代码段,数据段,堆栈段等等等等,每一个段都不定长,但是都有着很明显的用途。分段其实是站在操作系统的角度来看程序:我们直接把程序分成一个个固定长度的页,同时也把物理内存也分成同等大小的页,然后通过一个进程内部的表来把页和页映射起来。这种映射并不保证在物理内存上,页和页是连续的。但是会保证在程序的角度的内存,也就是虚拟内存上是连续的。通过一个表把连续的虚拟内存映射到不连续的物理内存上去来解决上面的问题。就像这样:
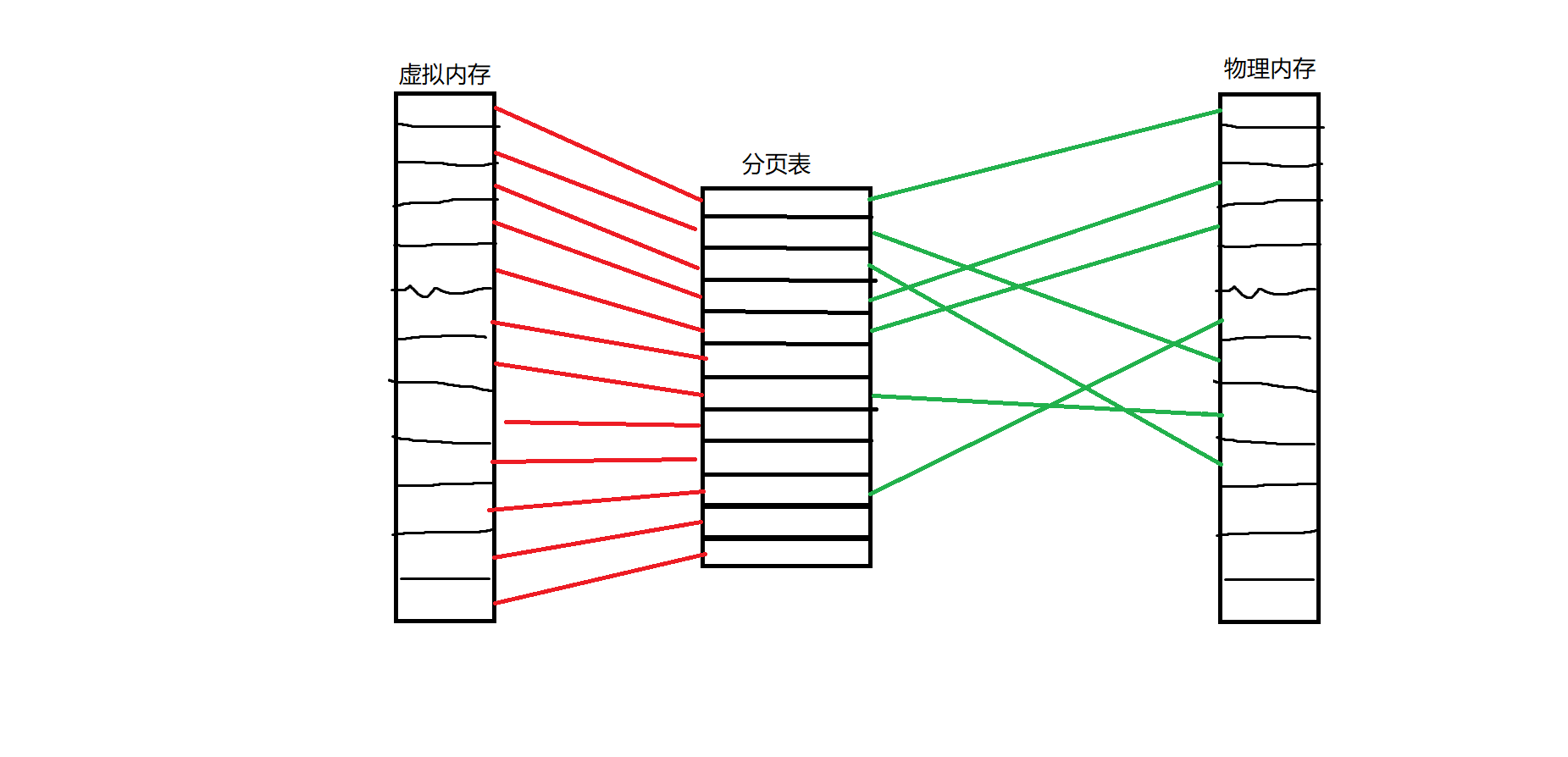
特别地,我们称在虚拟内存页面中每一个页叫做“页面”,物理内存中每一个也叫做“页框”。程序在执行的时候通常只会提供虚拟内存地址,然后cpu通过MMU(内存管理单元)来实现从虚拟地址到物理地址的映射查询。程序对这个过程完全不知道,程序只知道自己给出了一个地址,cpu返回了地址上的值。
打个比方
程序需要访问8745的虚拟内存地址,8745=2 * 4096+553,假设分页表里面2号页面对应着13号页框。cpu会访问13号页框下的553偏移处的数据,也就是13 * 4096+553=53801处的内存。每一个进程都会保留一个分页表,也就是说对于一开始的例子,我们只用把这些零散的内存映射到连续的虚拟内存中去就好了。
页的大小通常为4k,也就是4096个字节。
但是此时又会有一个问题,就是我们存储页表本身所占据的空间会被拉大。假设每一个进程所附带的页表中页的数量为1M,并且每一页的大小为4k,也就是说一个进程会使用大概4M的空间用来寻址。一半类似于windows的大型操作系统在初始化的时候会同时加载50多个进程,也就是说光用来寻址的内存占用就有大概200M。这个开销还是比较大的,所以我们通过使用二级页表来缩小这种内存上的开销。
层次化的分页结构
这里我需要把上面所说到了"页表"的概念拆开成两个东西——"页目录表"和"页表"。32位操作系统可以访问的内存有4GB,也就是1024 * 1024 * 4k,也就是说对应着1024 * 1024个页表。我们还是每1024页分一个页表,然后通过一个新的特殊页表(叫做页目录)来存放这些页表的基址(页目录的基址存放在cr3寄存器中,并且每一个进程都有一个自己的页目录)。
表面上来看这样并不会节省空间,但是实际上每一个进程只用保证页目录表在物理内存中就好了,页表可以在后续操作中分配,也就是说不用一次性存储所有的页表。
可以把页目录表看成页表的索引,或者类似于二级指针的东西。
对于一个32位地址,如果我们采取二级页表的方式寻址,则其寻址规则是这样的:
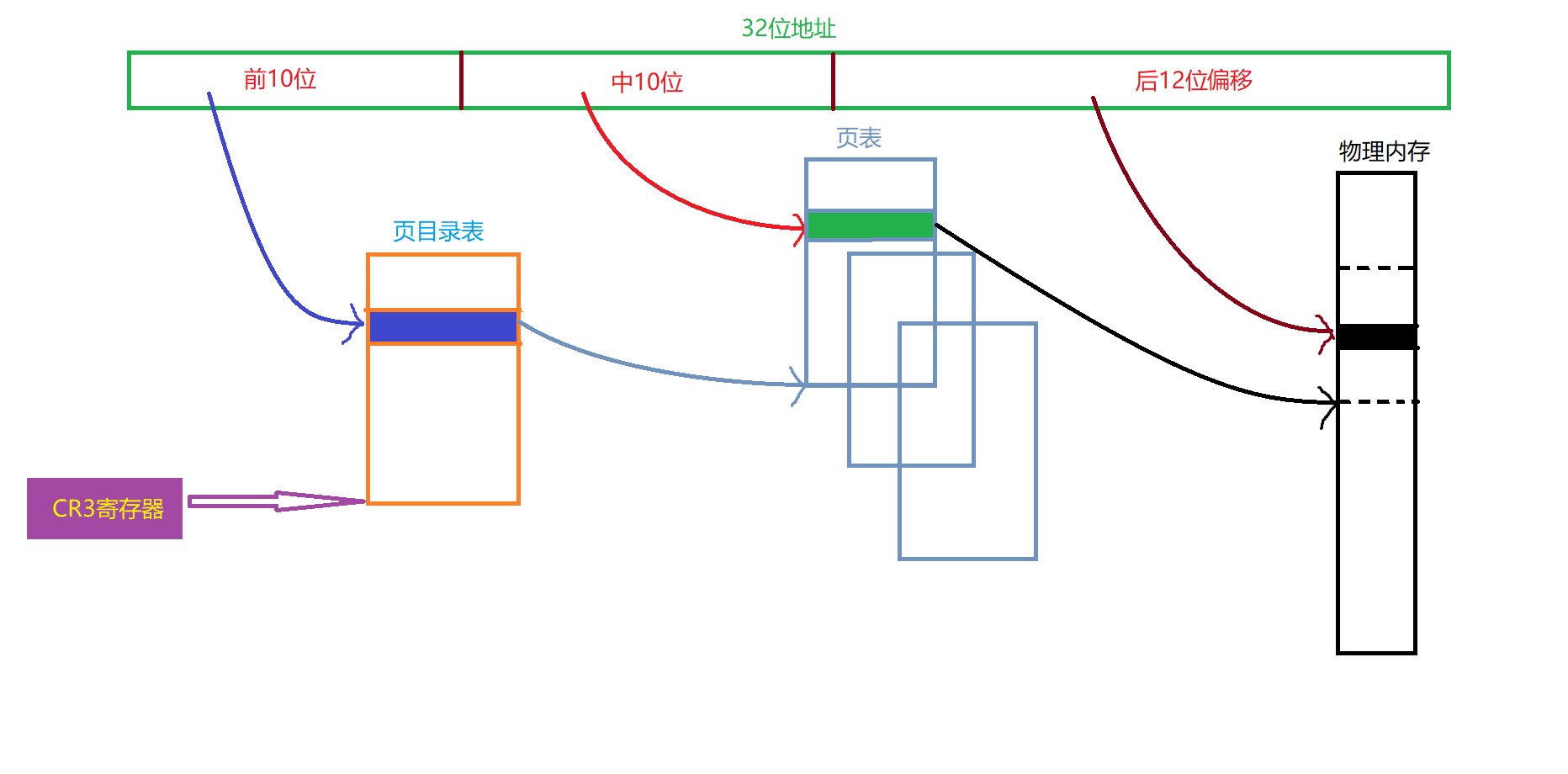
CR3存储的是页目录表的基地址,地址前10位存储的是页目录表内的偏移(具体指向了某一个页表的基地址),中10位存储的是页表内的偏移,通过访问具体的页表项得到物理内存中某一个页框的基地址,然后最后12位用来存储基址向上的偏移。这个过程相信通过图片已经可以很清晰地看出来了,这里就不再多说了。
页表项的构成
其实页表中的页表项并不是完全只存储页框基地址的,在里面还会存储页框的属性。
保护位
顾名思义,保护位就是代表着某个表项允许什么类型的访问,最简单的就是读或者写(0是只读,1是读写),再就是是否可执行。一个保护位一般有2bit。
修改位 & 访问位
这一位在计算机对某一个页面进行访问/修改的时候会发生变化,它们主要被用来为内存换入/换出算法提供一个参考。
禁止高速缓存位
当内存中的某些页面被映射到IO设备,并且系统正在等待着IO设备响应时,这些页面不能被加载到高速缓存中去,否则系统访问的就是一个旧的,在高速缓存中的副本而不是源源不断地从设备处获取数据。
开启分页功能:
PageDirBase equ 200000h ; 页目录开始地址: 2M
PageTblBase equ 201000h ; 页表开始地址: 2M+4K
LABEL_DESC_PAGE_DIR: Descriptor PageDirBase, 4095, DA_DRW;Page Directory
LABEL_DESC_PAGE_TBL: Descriptor PageTblBase, 1023, DA_DRW|DA_LIMIT_4K;Page Tables
SelectorPageDir equ LABEL_DESC_PAGE_DIR - LABEL_GDT
SelectorPageTbl equ LABEL_DESC_PAGE_TBL - LABEL_GDT
SetupPaging:
; 为简化处理, 所有线性地址对应相等的物理地址.
; 首先初始化页目录
mov ax, SelectorPageDir ; 此段首地址为 PageDirBase
mov es, ax
mov ecx, 1024 ; 共 1K 个表项
xor edi, edi
xor eax, eax
mov eax, PageTblBase | PG_P | PG_USU | PG_RWW
.1:
stosd
add eax, 4096 ; 为了简化, 所有页表在内存中是连续的.
loop .1
; 再初始化所有页表 (1K 个, 4M 内存空间)
mov ax, SelectorPageTbl ; 此段首地址为 PageTblBase
mov es, ax
mov ecx, 1024 * 1024 ; 共 1M 个页表项, 也即有 1M 个页
xor edi, edi
xor eax, eax
mov eax, PG_P | PG_USU | PG_RWW
.2:
stosd
add eax, 4096 ; 每一页指向 4K 的空间
loop .2
mov eax, PageDirBase
mov cr3, eax
mov eax, cr0
or eax, 80000000h
mov cr0, eax
jmp short .3
.3:
nop
ret
除了一开始初始化了段和段选择子(用作正常的内存访问),其实就是初始化了页目录表和页表,同时用页目录表基址填充cr3寄存器。这里为了方便起见,页目录表和页表的位置都是连续的(毕竟只是一个demo)。
操作系统:x86下内存分页机制 (1)的更多相关文章
- 轻量级操作系统FreeRTOS的内存管理机制(一)
本文由嵌入式企鹅圈原创团队成员朱衡德(Hunter_Zhu)供稿. 近几年来,FreeRTOS在嵌入式操作系统排行榜中一直位居前列,作为开源的嵌入式操作系统之一,它支持许多不同架构的处理器以及多种编译 ...
- C#实现的内存分页机制的一个实例
C#实现的内存分页机制的一个实例 //多页索引表管理类(全局主索引表管理类) public class MuliPageIndexFeatureClass : IDisposable { protec ...
- x86架构:分页机制和原理
分页是现在CPU核心的管理内存方式,网上介绍材料很多,这里不赘述,简单介绍一下分页的背景和原理 1.先说说为什么要分段 实模式下程序之间不隔离,互相能直接读写对方内存,或跳转到其他进程的代码运行,导致 ...
- CPU内存管理和linux内存分页机制
一.概念 物理地址(physical address)用于内存芯片级的单元寻址,与处理器和CPU连接的地址总线相对应.——这个概念应该是这几个概念中最好理解的一个,但是值得一提的是,虽然可以直接把物理 ...
- x86 分页机制——虚拟地址到物理地址寻址
x86下的分页机制有一个特点:PAE模式 PAE模式 物理地址扩展,是基于x86 的服务器的一种功能,它使运行 Windows Server 2003, Enterprise Edition 和 Wi ...
- Linux分页机制
地址长度 在Linux下,unsigned long可以与地址的长度保持一致,即32位系统下unsigned long为32位,而64位系统下为64位长. 虚拟地址的分解 如图所示,通过XXX_SHI ...
- Android 操作系统的内存回收机制(转载)
Android 操作系统的内存回收机制(转载) Android APP 的运行环境 Android 是一款基于 Linux 内核,面向移动终端的操作系统.为适应其作为移动平台操作系统的特殊需要,谷歌对 ...
- Android 操作系统的内存回收机制[转]
转自:http://www.ibm.com/developerworks/cn/opensource/os-cn-android-mmry-rcycl/ Android APP 的运行环境 Andro ...
- Intel微处理器学习笔记(四) 内存分页
内存分页机制(memory paging mechanism)是从386开始的.线性地址通过分页机制透明转换为物理地址. 从这里知道:1. 如果不分页,则线性地址等于物理地址:2. 如果分页,则线性地 ...
随机推荐
- Go语言从入门到高薪之路(一)-- 初识与安装
为什么要学习Go语言? Go语言又称Golang,它是21世纪的编程语言,学好了就能拿高薪,拿了高薪就能实力装逼,有了实力就能泡妹子...(我就问你吊不吊,想不想学?) Go语言有什么特点和优势? G ...
- Redis操作及集群搭建以及高可用配置
NoSQL - Redis 缓存技术 Redis功能介绍 数据类型丰富 支持持久化 多种内存分配及回收策略 支持弱事务 支持高可用 支持分布式分片集群 企业缓存产品介绍 Memcached: 优点:高 ...
- Python超级码力在线编程大赛初赛题解
P1 三角魔法 描述小栖必须在一个三角形中才能施展魔法,现在他知道自己的坐标和三个点的坐标,他想知道他能否施展魔法 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后, ...
- jieba分词-强大的Python 中文分词库
1. jieba的江湖地位 NLP(自然语言)领域现在可谓是群雄纷争,各种开源组件层出不穷,其中一支不可忽视的力量便是jieba分词,号称要做最好的 Python 中文分词组件. 很多人学习pytho ...
- 小程序商城系统CRMEB Pro v1.1全新重构,新增DIY功能
CRMEB ProV1.1全新升级发布,真正实现了后台可自由拖拽组合实现首页布局的DIY功能,这一功能的实现,将告别过去千篇一律的同质化界面布局,真正实现个性化.高自由的随心组合.本次发布的版本中我们 ...
- Pytest的装饰器——parametrize中ids里包含中文,用例标题显示异常如何解决?
在使用pytest做测试的过程中,经常会用到pytest.mark.parametrize来对批量生成测试用例,比如 @pytest.mark.parametrize( ['a', 'b', 'exp ...
- 0827考试 T1
Description 有一棵树,每个点有一个权值,找到一个权值最大的"乙烷"模型. "乙烷"模型是指: 其中黑点表示可以有0个或多个点. Samp ...
- amd、cmd、CommonJS以及ES6模块化
AMD.CMD.CommonJs.ES6的对比 他们都是用于在模块化定义中使用的,AMD.CMD.CommonJs是ES5中提供的模块化编程的方案,import/export是ES6中定义新增的 什么 ...
- qdu-凑数题(01背包)
Description 小Q手里有n(n<=1000) 个硬币,每枚硬币有一定的金额(200=>x>=1)他想知道,用这些硬币(每枚硬币只能用一次,但可能会有等面值的用两次) 能组成 ...
- 伪距定位算法(matlab版)
在各种伪距定位算法中,最小二乘法是一种比较简单而广泛的方法,该算法可以分为以下几步: 1.准备数据与设置初始值 这里准备数据,主要是对于各颗可见卫星,收集到它们在同一时刻的伪距测量值,计算测量值的各项 ...