解压gzip格式文件(包括网页)
先上源码
参数说名:
- source :gzip格式流内容。
- len: gzip流长度
- dest: 解压后字符流指针
- gzip: 压缩标志,非0时解压gzip格式,否则按照zip解压
说明:代码经过测试。解压后内容printf或者cout出来是乱码的,保存为文件是可以的,如果文件还是乱码,以utf-8打开就能正常显示(Windows默认Ansi编码,编码区别自己百度)。
#ifndef __GUNZIP_H__
#define __GUNZIP_H__
#include "zlib.h"
#include "stdlib.h"
#include "string.h"
#define CHUNK 64
int inflate_read(unsigned char *source, int len, unsigned char **dest, int gzip)
{
int ret;
unsigned have;
z_stream strm;
unsigned char out[CHUNK];
int totalsize = 0;
/* allocate inflate state */
strm.zalloc = Z_NULL;
strm.zfree = Z_NULL;
strm.opaque = Z_NULL;
strm.avail_in = 0;
strm.next_in = Z_NULL;
if(gzip)
ret = inflateInit2(&strm, 47);
else
ret = inflateInit(&strm);
if (ret != Z_OK)
return ret;
strm.avail_in = len;
strm.next_in = source;
/* run inflate() on input until output buffer not full */
do {
strm.avail_out = CHUNK;
strm.next_out = out;
ret = inflate(&strm, Z_NO_FLUSH);
//assert(ret != Z_STREAM_ERROR); /* state not clobbered */
switch (ret) {
case Z_NEED_DICT:
ret = Z_DATA_ERROR; /* and fall through */
case Z_DATA_ERROR:
case Z_MEM_ERROR:
inflateEnd(&strm);
return ret;
}
have = CHUNK - strm.avail_out;
totalsize += have;
*dest = (unsigned char*)realloc(*dest,totalsize);
memcpy(*dest + totalsize - have, out, have);
} while (strm.avail_out == 0);
/* clean up and return */
(void)inflateEnd(&strm);
return ret == Z_STREAM_END ? Z_OK : Z_DATA_ERROR;
}
#endif说明:上树源码并不验证文件内容完整性。
编译需要zlib库支持,连接选项’-lz’,如果提示错误安装zlib1g, zlib1g-dev.
解压网页
现在网站为了减小带宽占用,会对传输内容做压缩。nginx就默认开启gzip压缩。通过浏览器(火狐,chrome)f12可以查看当前页面传输格式。’Content-Encoding’ 头域指明文件的压缩算法;’Content-Length’指明传输文件的长度;’Transfer-Encoding’指明传输形式,如图中的‘chunked’表示块传输(具体自己百度)。其中’Content-Length’与’Transfer-Encoding’是一对矛盾的存在,而这只能有其一。块传输允许服务器再不知道要回应多少内容时候先传输一部分,在结束时候明显标记技术。
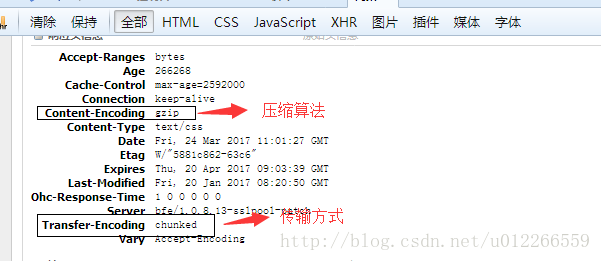
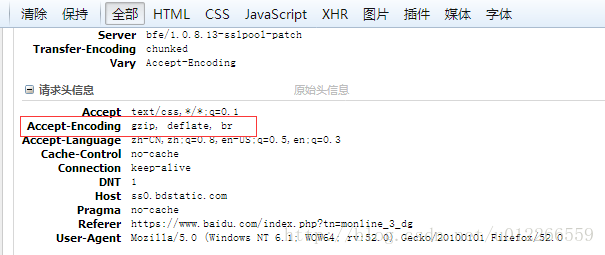
网站会根据客户端的请求决定是否对内容进行压缩,浏览器HTTP请求头有’Accept-Encoding’ 头域指定可以接受的内容形式。
步骤
- 解压缩网页需要判断压缩内容开始的位置,压缩内容开始是在http头部结束位置,HTTP协议规定HTTP头域每一个标签结束需要以’\r\n’结束,在头结束位置以’\r\n’与内容分割。也就是http头结束是’\r\n\r\n’,在这之后就是压缩内容。
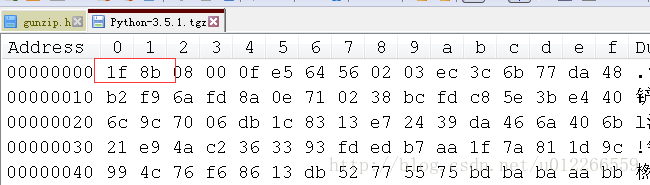
- gzip格式是以’0x1f 0x8b’开始的。
- 文件长度:如果未采取块传输,HTTP 响应的 ‘Content-Length’就是压缩内容的长度。如果采取块传输需要缓存每一部分,直到结束。因为压缩不是按块压缩的,而是分块传输的gzip实体。
最后建议:如果采用本代码进行解压网页,不是很建议,自己需要做的工作比较多,需要缓存,重组,解压。有另一种简单方式是利用’libcurl’,libcurl 支持自解压,只需要设置 CURLOPT_ENCODING 选项。
解压gzip格式文件(包括网页)的更多相关文章
- Linux 解压xz格式文件及安装xz
1.安装xz命令 # yum install epel-release -y # yum install xz -y 2.将xz文件解压为tar文件 # xz -d test.tar.xz 3.将ta ...
- Linux下批量解压.Z格式文件
下面的代码演示如何将当前目录下sj目录下的所有.Z格式文件解压到sj_result目录下. 代码示例: for file in `ls ./sj` do prefix=${file%.*} echo ...
- mac解压7z格式文件
brew直接安装解压工具 $ brew search 7z p7zip $ brew install p7zip ==> Downloading https://downloads.source ...
- 解压tar.gz文件报错gzip: stdin: not in gzip format解决方法
解压tar.gz文件报错gzip: stdin: not in gzip format解决方法 在解压tar.gz文件的时候报错 1 2 3 4 5 [Sun@localhost Downloads] ...
- 使用commons-compress解压GBK格式winzip文件到UTF8,以及错误使用ZipArchiveInputStream读出来数据全是空的解决办法
先上正确方法: 正确方式应该为,先创建一个ZipFile,然后对其entries做遍历,每一个entry其实就是一个文件或者文件夹,检测到文件夹的时候创建文件夹,其他情况创建文件,其中使用zipFil ...
- Linux中下载、解压、安装文件
一.将解压包发送到linux服务器上: 1.在windos上下载好压缩包文件后,通过winscp等SFTP客户端传送给linux 2.在linux中通过wget命令直接下载 #wget [选项] [下 ...
- Linux中下载、解压、安装文件(转)
原文地址:http://www.cnblogs.com/red-code/p/5539399.html 一.将解压包发送到linux服务器上: 1.在windos上下载好压缩包文件后,通过winscp ...
- 【VC++技术杂谈008】使用zlib解压zip压缩文件
最近因为项目的需要,要对zip压缩文件进行批量解压.在网上查阅了相关的资料后,最终使用zlib开源库实现了该功能.本文将对zlib开源库进行简单介绍,并给出一个使用zlib开源库对zip压缩文件进行解 ...
- [Linux] 解压tar.gz文件,解压部分文件
遇到数据库无法查找问题原因,只能找日志,查找日志的时候发现老的日志都被压缩了,只能尝试解压了 数据量比较大,只能在生产解压了,再进行查找 文件名为*.tar.gz,自己博客以前记录过解压方法: h ...
随机推荐
- DRF内置过滤组件与排序组件结合使用
DRF内置过滤组件Filtering DRF提供了内置过滤组件Filtering,可以结合url路径的改变获取想要的数据,当然用户不可能在url访问路径中自己设置过滤条件,肯定是后端开发人员将前端页面 ...
- MySQL查看数据存放位置
show global variables like "%datadir%";
- 利用 Github Actions 自动更新 docfx 文档
利用 Github Actions 自动更新 docfx 文档 Intro docfx 是微软出品一个 .NET API 文档框架,有一个理念是代码即文档,会根据项目代码自动生成 API 文档,即使没 ...
- 操作系统-I/O(2)设备的分配
作业执行前对设备提出申请时,指定某台具体的物理设备会让设备分配变得简单,但如果所指定设备出现故障,即便计算机系统中有同类设备也不能运行 设备独立性:用户通常不指定物理设备,而是指定逻辑设备,使得用户作 ...
- 键盘敲入 A 字母时,操作系统期间发生了什么
前言 键盘可以说是我们最常使用的输入硬件设备了,但身为程序员的你,你知道「键盘敲入A 字母时,操作系统期间发生了什么吗」? 那要想知道这个发生的过程,我们得先了解了解「操作系统是如何管理多种多样的的输 ...
- Javascript逻辑运算认识
1 - 运算符(操作符) 1.1 运算符的分类 运算符(operator)也被称为操作符,是用于实现赋值.比较和执行算数运算等功能的符号. JavaScript中常用的运算符有: 算数运算符 递增和递 ...
- python爬虫数据提取之bs4的使用方法
Beautiful Soup的使用 1.下载 pip install bs4 pip install lxml # 解析器 官方推荐 2.引用方法 from bs4 import BeautifulS ...
- vue + vant 上传图片之压缩图片
<van-uploader v-model="fileList" multiple :after-read="afterRead" :max-count= ...
- 【学习中】Unity插件之NGUI 完整视频教程
课程 章节 内容 签到 Unity插件之NGUI 完整视频教程 第一章 NGUI基础控件和基础功能学习 1.NGUI介绍和插件的导入 6月29日 2.创建UIRoot 6月29日 3.学习Label控 ...
- 在CG/HLSL中访问着色器的内容
着色器在Properties代码块中声明 材质球的各种特性.如果你想要在着色器程序中使用这些特性,你需要在CG/HLSL中声明一个变量,这个变量需要与你要使用的特性拥有同样的名字和对的上号的类型.比如 ...