python爬取千库网
url:https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-1/
有水印
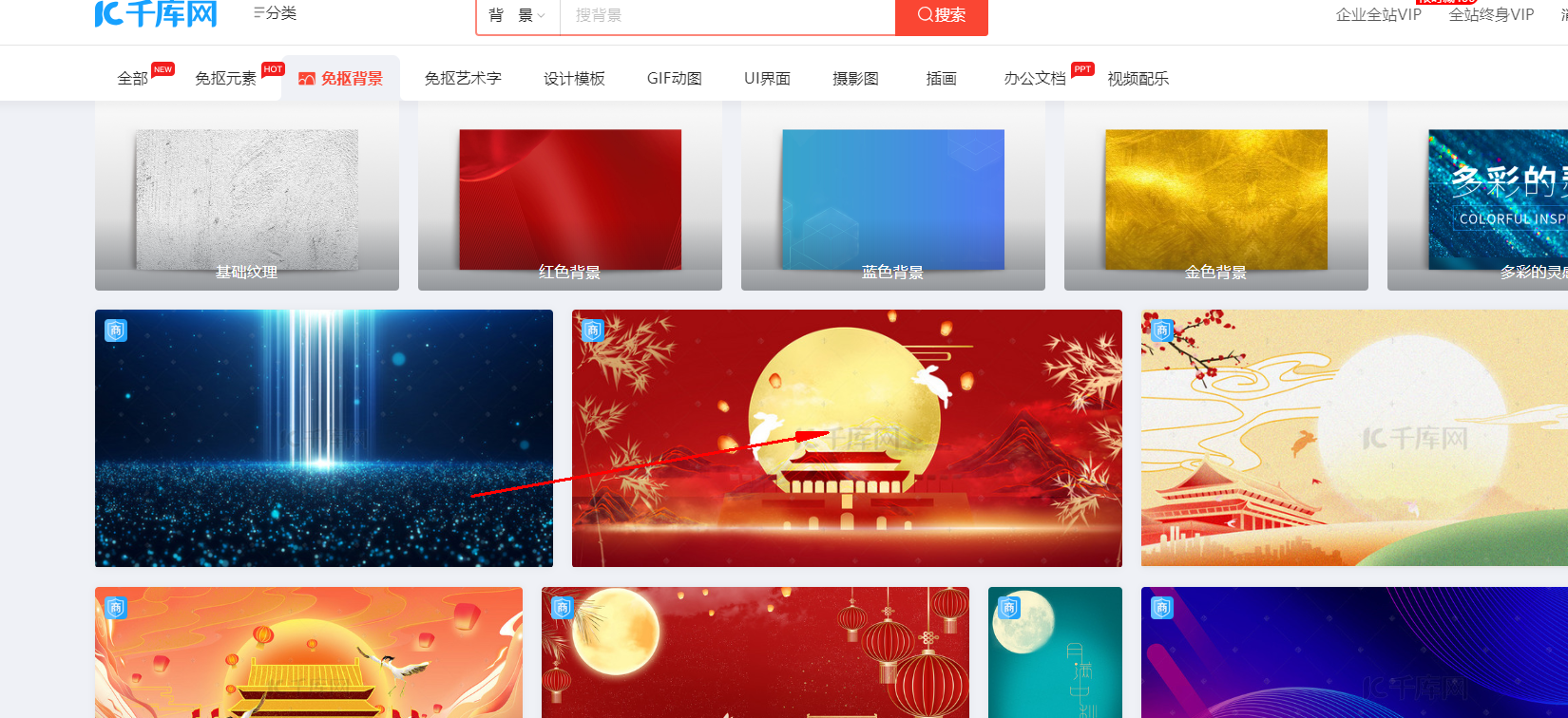
但是点进去就没了
这里先来测试是否有反爬虫
import requests
from bs4 import BeautifulSoup
import os
html = requests.get('https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-1/')
print(html.text)
输出是404,添加个ua头就可以了
可以看到每个图片都在一个div class里面,比如fl marony-item bglist_5993476,是3个class但是最后一个编号不同就不取
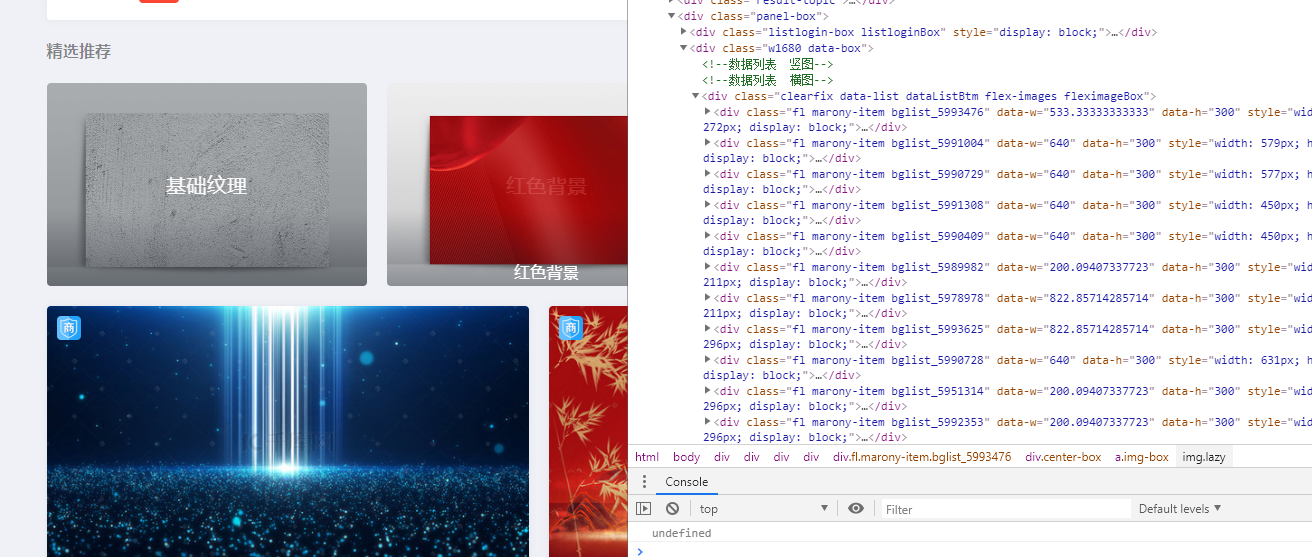
我们就可以获取里面的url
import requests
from bs4 import BeautifulSoup
import os
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
html = requests.get('https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-1/',headers=headers)
soup = BeautifulSoup(html.text,'lxml')
Urlimags = soup.select('div.fl.marony-item div a')
for Urlimag in Urlimags:
print(Urlimag['href'])
输出结果为
//i588ku.com/ycbeijing/5993476.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5991004.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5990729.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5991308.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5990409.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5989982.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5978978.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5993625.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5990728.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5951314.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5992353.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5993626.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5992302.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5820069.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5804406.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5960482.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5881533.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5986104.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5956726.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5986063.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5978787.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5954475.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5959200.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5973667.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5850381.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5898111.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5924657.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5975496.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5928655.html
//i588ku.com/comnew/vip/
//i588ku.com/ycbeijing/5963925.html
//i588ku.com/comnew/vip/
这个/vip是广告,过滤一下
for Urlimag in Urlimags:
if 'vip' in Urlimag['href']:
continue
print('http:'+Urlimag['href'])
然后用os写入本地
import requests
from bs4 import BeautifulSoup
import os
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
html = requests.get('https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-1/',headers=headers)
soup = BeautifulSoup(html.text,'lxml')
Urlimags = soup.select('div.fl.marony-item div a')
for Urlimag in Urlimags:
if 'vip' in Urlimag['href']:
continue
# print('http:'+Urlimag['href'])
imgurl = requests.get('http:'+Urlimag['href'],headers=headers)
imgsoup = BeautifulSoup(imgurl.text,'lxml')
imgdatas = imgsoup.select_one('.img-box img')
title = imgdatas['alt']
print('无水印:','https:'+imgdatas['src'])
if not os.path.exists('千图网图片'):
os.mkdir('千图网图片')
with open('千图网图片/{}.jpg'.format(title),'wb')as f:
f.write(requests.get('https:'+imgdatas['src'],headers=headers).content)
然后我们要下载多页,先看看url规则
第一页:https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-1/
第二页:https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-2/
import requests
from bs4 import BeautifulSoup
import os
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
for i in range(1,11):
print('正在下载第{}页'.format(i))
html = requests.get('https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-{}/'.format(i),headers=headers)
soup = BeautifulSoup(html.text,'lxml')
Urlimags = soup.select('div.fl.marony-item div a')
for Urlimag in Urlimags:
if 'vip' in Urlimag['href']:
continue
# print('http:'+Urlimag['href'])
imgurl = requests.get('http:'+Urlimag['href'],headers=headers)
imgsoup = BeautifulSoup(imgurl.text,'lxml')
imgdatas = imgsoup.select_one('.img-box img')
title = imgdatas['alt']
print('无水印:','https:'+imgdatas['src'])
if not os.path.exists('千图网图片'):
os.mkdir('千图网图片')
with open('千图网图片/{}.jpg'.format(title),'wb')as f:
f.write(requests.get('https:'+imgdatas['src'],headers=headers).content)
python爬取千库网的更多相关文章
- Python爬取中国天气网
Python爬取中国天气网 基于requests库制作的爬虫. 使用方法:打开终端输入 “python3 weather.py 北京(或你所在的城市)" 程序正常运行需要在同文件夹下加入一个 ...
- python爬取天气后报网
前言 大二下学期的大数据技术导论课上由于需要获取数据进行分析,我决定学习python爬虫来获取数据.由于对于数据需求量相对较大,我最终选择爬取 天气后报网,该网站可以查询到全国各地多年的数据,而且相对 ...
- (python爬取小故事网并写入mysql)
前言: 这是一篇来自整理EVERNOTE的笔记所产生的小博客,实现功能主要为用广度优先算法爬取小故事网,爬满100个链接并写入mysql,虽然CS作为双学位已经修习了三年多了,但不仅理论知识一般,动手 ...
- Python爬取中国票房网所有电影片名和演员名字,爬取齐鲁网大陆所有电视剧名称
爬取CBO中国票房网所有电影片名和演员名字 # -*- coding: utf-8 -*- # 爬取CBO中国票房网所有电影片名 import json import requests import ...
- python爬取斗图网中的 “最新套图”和“最新表情”
1.分析斗图网 斗图网地址:http://www.doutula.com 网站的顶部有这两个部分: 先分析“最新套图” 发现地址栏变成了这个链接,我们在点击第二页 可见,每一页的地址栏只有后面的pag ...
- 适合初学者的Python爬取链家网教程
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: TinaLY PS:如有需要Python学习资料的小伙伴可以加点击下 ...
- Python 爬取煎蛋网妹子图片
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Date : 2017-08-24 10:17:28 # @Author : EnderZhou (z ...
- python爬取中国知网部分论文信息
爬取指定主题的论文,并以相关度排序. #!/usr/bin/python3 # -*- coding: utf-8 -*- import requests import linecache impor ...
- Python爬取17吉他网吉他谱
最近学习吉他,一张一张保存吉他谱太麻烦,写个小程序下载吉他谱. 安装 BeautifulSoup,BeautifulSoup是一个解析HTML的库.pip install BeautifulSoup4 ...
随机推荐
- MySQL数据库时间字段按年月日显示并多字段去重查询
应用服务长久运行,难免要导出一些统计报表. 现在有一个日志表,记录了各种日志,需要导出十月份的登录日志,要求时间按日期显示,且每天用户登陆要去重. 先看日志表的字段构成: logType等于2的是登陆 ...
- HDU 6609 离散化+权值线段树
题意 有一个长度为\(n\)的数组W; 对于每一个\(i\)(\(1<=i<=n\)),你可以选择中任意一些元素W[k] (\(1<=k<i\)),将他们的值改变为0,使得\( ...
- 牛客网PAT练习场-数字分类
签到题 地址:https://www.nowcoder.com/pat/6/problem/4078 #include<iostream> #include<cstdio> u ...
- 【转】C# 利用反射根据类名创建类的实例对象
原文地址:https://www.cnblogs.com/feiyuhuo/p/5793606.html “反射”其实就是利用程序集的元数据信息. 反射可以有很多方法,编写程序时请先导入 System ...
- 从零开始的SpringBoot项目 ( 三 ) 项目打包( war包篇 )
pom.xml 修改打包类型 jar 改为 war 添加 tomcat 依赖 找到最右边的 Maven Projects,点击进去,选择需要打包的项目,并点击 install,就开始打包了,打包前先点 ...
- 如何通过seo技术提高网站对用户的友好度
http://www.wocaoseo.com/thread-129-1-1.html 今天的天气又是29度,眼看着满大街的人都穿着短袖和衬衣了,自己也再不能穿个厚厚的外套出去了,要不会被别人笑 ...
- 30年技术积累,技术流RTC如何成为视频直播领域的黑马?
摘要:视频业务链的背后,本质是一张视频处理和分发网络.5G+云+AI时代下,实时音视频必然会步入到一个全新的发展期. 2020年这场肆虐全球的新冠疫情让很多企业重新审视自己对数字化的认识,正如 “大潮 ...
- IDEA导入Eclipse的快捷键KeyMap
说在前面的话 现在由于IDEA编辑器越来越火,因此很多程序员都从eclipse转入IDEA,转入后确实发现很强大的编辑器,但是一直为快捷键而忧愁,因为eclipse毕竟跟随了自己好多年了,突然更换编辑 ...
- JS中强制类型转换
JavaScript提供了3种强制类型转换的方法 一.Boolean()方法 该方法将指定的参数转换成布尔型.Boolean(object).参数object可以是字符串对象.数值对象.DOM对象等. ...
- .net core学习笔记,组件篇:服务的注册与发现(Consul)初篇
1.什么是服务注册中心? 在学习服务注册与发现时,我们要先搞明白到底什么是服务注册与发现. 在这里我举一个生活中非常普遍的例子——网购来简单说明,网购在我们日常生活中已经是非常普遍了,其实网购中的(商 ...