python爬取斗图网中的 “最新套图”和“最新表情”
 1.分析斗图网
1.分析斗图网
斗图网地址:http://www.doutula.com
网站的顶部有这两个部分:

先分析“最新套图”

发现地址栏变成了这个链接,我们在点击第二页

可见,每一页的地址栏只有后面的page不同,代表页数;这样请求的地址就可以写了。
2.寻找表情包
然后就要找需要爬取的表情包链接了。我用的是chrome浏览器,F12进入开发者模式。
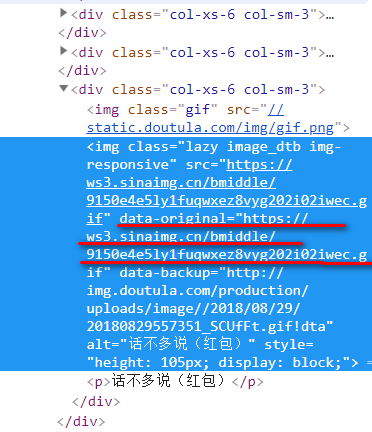
找到图片对应的img元素,发现每个Img元素的class都是相同的。data-original属性对应的地址,就是我们要下载的图片。alt属性就是图片的名字。
对于”最新表情“的页面,同样也是如此。
3.编写代码
元素都找到了,可以上代码了:
#coding=utf-8
import requests
from lxml import etree
from urllib import request
from time import sleep
import socket
import re socket.setdefaulttimeout(20) headers = {}
headers["User-Agent"] = "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0"
headers["Host"] = "www.doutula.com"
headers["Accept"] = "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8"
headers["Accept-Language"] = "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2"
headers["Accept-Encoding"] = "gzip, deflate"
headers["Connection"] = "close"
headers["Upgrade-Insecure-Requests"] = "" def get_url(page):
# 最新套图580页
url = "http://www.doutula.com/article/list/?page=" + str(page)
# 最新表情1855页
# url = "http://www.doutula.com/photo/list/?page=" + str(page)
response = requests.get(url, headers=headers)
html = response.text
selector = etree.HTML(html)
# print(html)
# 最新套图xpath
img_url = selector.xpath('//img[@class="lazy image_dtb img-responsive"]/@data-original')
img_name = selector.xpath('//img[@class="lazy image_dtb img-responsive"]/@alt')
# 最新表情xpath
# img_url = selector.xpath('//img[@style="width: 100%; height: 100%;"]/@data-original')
# img_name = selector.xpath('//img[@style="width: 100%; height: 100%;"]/@alt')
img_name = name_filter(img_name)
for img in img_url:
id = img_url.index(img)
get_img(id, img, img_name)
response.close() def get_img(id, img, img_name):
"""
request.urlretrieve: 保存链接地址的文件
"""
global j
try:
if img[-3:] == 'dta':
if img[-7:-4] == 'gif':
request.urlretrieve(img, 'E:\\pictures\\%s.gif' % img_name[id])
elif img[-7:-4] == 'png':
request.urlretrieve(img, 'E:\\pictures\\%s.png' % img_name[id])
else:
request.urlretrieve(img, 'E:\\pictures\\%s.jpg' % img_name[id])
elif img[-3:] == 'gif':
request.urlretrieve(img, 'E:\\pictures\\%s.gif' % img_name[id])
elif img[-3:] == 'png':
request.urlretrieve(img, 'E:\\pictures\\%s.png' % img_name[id])
else:
request.urlretrieve(img, 'E:\\pictures\\%s.jpg' % img_name[id])
print("下载第%d张表情包" % j + img)
except Exception as ex: # urlopen error time out
print(str(ex))
j += 1 def name_filter(img_name):
"""
过滤文件名中的特殊字符
"""
newlist = []
for im in img_name:
im = re.sub(r'\?', '', str(im)) # / \
newlist.append(im)
return newlist if __name__ == '__main__': j = 1
for page in range(1, 581):
print("第%s页" % page)
while True:
try:
get_url(page)
break
except Exception as e:
print(str(e))
sleep(5)
sleep(10)
4.运行结果
爬了两天,可能代码中的sleep时间有点长,服务器那边也老是断开连接。

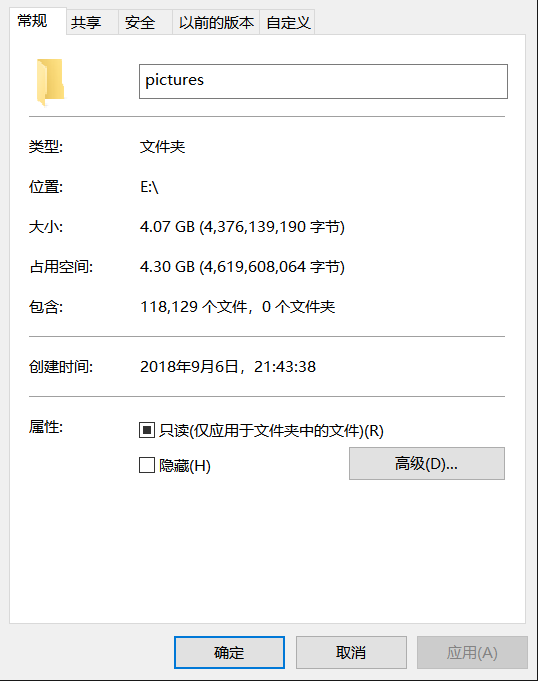
数据有些偏差,可能下载的过程网络的问题导致的。
5.总结
编码过程中,对于异常处理的思考,还需要多提高;有许多会出现问题的地方,都没有考虑到。
python爬取斗图网中的 “最新套图”和“最新表情”的更多相关文章
- Python爬取中国天气网
Python爬取中国天气网 基于requests库制作的爬虫. 使用方法:打开终端输入 “python3 weather.py 北京(或你所在的城市)" 程序正常运行需要在同文件夹下加入一个 ...
- python爬取天气后报网
前言 大二下学期的大数据技术导论课上由于需要获取数据进行分析,我决定学习python爬虫来获取数据.由于对于数据需求量相对较大,我最终选择爬取 天气后报网,该网站可以查询到全国各地多年的数据,而且相对 ...
- (python爬取小故事网并写入mysql)
前言: 这是一篇来自整理EVERNOTE的笔记所产生的小博客,实现功能主要为用广度优先算法爬取小故事网,爬满100个链接并写入mysql,虽然CS作为双学位已经修习了三年多了,但不仅理论知识一般,动手 ...
- python爬取千库网
url:https://i588ku.com/beijing/0-0-default-0-8-0-0-0-0-1/ 有水印 但是点进去就没了 这里先来测试是否有反爬虫 import requests ...
- Python爬取 斗图表情,让你成为斗图大佬
话不多说,上结果(只爬了10页内容) 上代码:(可直接运行) 用到Xpath #encoding:utf-8 # __author__ = 'donghao' # __time__ = 2018/ ...
- 适合初学者的Python爬取链家网教程
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: TinaLY PS:如有需要Python学习资料的小伙伴可以加点击下 ...
- Python爬取中国票房网所有电影片名和演员名字,爬取齐鲁网大陆所有电视剧名称
爬取CBO中国票房网所有电影片名和演员名字 # -*- coding: utf-8 -*- # 爬取CBO中国票房网所有电影片名 import json import requests import ...
- Python 爬取煎蛋网妹子图片
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Date : 2017-08-24 10:17:28 # @Author : EnderZhou (z ...
- Python爬取中国知网文献、参考文献、引证文献
前两天老师派了个活,让下载知网上根据高级搜索得到的来源文献的参考文献及引证文献数据,网上找了一些相关博客,感觉都不太合适,因此特此记录,希望对需要的人有帮助. 切入正题,先说这次需求,高级搜索,根据中 ...
随机推荐
- 【转】Linux下RabbitMQ服务器搭建(单实例)
阅读目录 系统环境 安装步骤 注意事项 参考资料 回到顶部 系统环境 操作系统:CentOS6.9 erlang:OTP 19.3 rabbitmq:rabbitmq-server 3.6.12 回到 ...
- pgAdmin4 重置布局
pgAdmin4 是网页版客户端,而且在其网页上可以通过拖拽改变布局.当布局混乱时可以通过 菜单File--Reset Layout功能来重置. 如果这篇随笔只是为了说以上这句话就没必要了,而且你根据 ...
- Notes 20180311 : String第三讲_深入了解String
很多前辈我可能对于我的这节文章很困惑,觉得String这个东西还有什么需要特别了解的吗?其实不然,String是一个使用十分频繁的工具类,不可避免地我们也会遇到一些陷阱,深入了解String对于我们避 ...
- centos7 安装拼音输入法
依次选择Applications->System Tools->setting->Regiin&Language,添加Chinese(Intelligent Pinyin) ...
- 网络的可靠性nyoj170
网络的可靠性 时间限制:3000 ms | 内存限制:65535 KB 难度:3 描述 A公司是全球依靠的互联网解决方案提供商,也是2010年世博会的高级赞助商.它将提供先进的网络协作技术,展 ...
- sublime Text3安装 markdownediting 报错 解决记录
看了一下官方文档,也是醉了,都怪自己的无知. 在安装时候不要打开.md的文件,因为你里面有可能有一些语法错误,所以会导致报错. 解决方法关闭其他文件,在重新安装! 官方解释: 参考文档:Trouble ...
- java业务逻辑,利用hibernate获取所连接的数据库信息
1.本人程序架构是springMVC+hibernate,这次的需求是要针对不同的数据库,做不同的处理. 2.获取所连接的数据库是什么,oracle? mysql? sql server? 基础 ...
- html5手机浏览器启动微信客户端支付实例
html5手机浏览器启动微信客户端支付实例,外部浏览器html5微信支付技术,如何在手机浏览器微信支付,在微信客户端外的移动端网页使用微信支付 首先在微信支付官网https://pay.weixin. ...
- laravel5.5源码笔记(二、服务提供者provider)
laravel里所谓的provider服务提供者,其实是对某一类功能进行整合,与做一些使用前的初始化引导工作.laravel里的服务提供者也分为,系统核心服务提供者.与一般系统服务提供者.例如上一篇博 ...
- 从零开始搭建vue移动端项目到上线的步骤
初始化项目 1.在安装了node.js的前提下,使用以下命令 npm install --g vue-cli 2.在将要构建项目的目录下 vue init webpack myproject(项目目录 ...