【工程应用一】 多目标多角度的快速模板匹配算法(基于NCC,效果无限接近Halcon中........)
愿意写代码的人一般都不太愿意去写文章,因为代码方面的艺术和文字中的美学往往很难兼得,两者都兼得的人通常都已经被西方极乐世界所收罗,我也是只喜欢写代码,让那些字母组成美妙的歌曲,然后自我沉浸在其中自得其乐。而今天,在清明之际,在踏青时节,我还是忍不住停下来歇歇脚,稍微共享一下最近一直研究的一个非常基础的算法和应用 - 多目标多角度的模板匹配。
模板匹配,这是一个几十年来一直为业界所重点研究和处理的算法,存在于各种不同的机器视觉库中,如果哪一个没有提供这个功能,那么他将无法获取大家的认可,也就失去了最基本的活力。可以说模板匹配基于机器视觉就相当于数组在编程语言中一样,基础但是不可或缺。
在2004年时,我的毕业设计中一个很重要的部分也是模板匹配,当时用模板匹配找到每个量杯中黄色的油的位置,现在看来用那个算法也是醉了,不过能顺利毕业还考得就是他。
在我的早期博客中,有一篇文章已经谈到了这个算法,详见:标准的基于欧式距离的模板匹配算法优源码化和实现(附源代码), 但是这个是个非常慢的过程,而且是单目标无旋转的实现,在实际应用中,这个基本没有啥实际的价值。
在工业应用场合,有着非常广泛使用场景的是多目标多角度的模板匹配(基本无缩放或轻微缩放),这方面实现的比较好的有halcon、海康、康耐视等,国内也有一些小单位有做研究,而且效果不错。在网络上其实也有比较多的文章谈到了多目标模板匹配,基本上都是基于Opencv实现,良心的说也谈到了一些核心技术,但是还是皮毛,基本都是一带而过,而且实现的效率也基本是没有什么实用价值的,可能是怕说多了别人学会了吧。
虽然在我的实现中,也参考了不少网络上的文章,但是大部分的细节还是靠的自己的思考和朋友的一些指导,为了尊重他人,我也不打算特别深入讲解我的实现,但是还是把一些具有一定深度的问题提出来,也算是回报网络吧。
1、概述
这里先提工业界最为常用,也是最为基本的模板匹配方式,基于NCC的灰度模板匹配。
NCC,全称为Normalized Cross correlation,即归一化互相关系数, 在模板匹配中使用的非常非常广泛,也是众多模板匹配方法中非常耀眼的存在, 这个匹配的理论核心基础公式如下:
 (1)
(1)
该方法也存在于Opencv的matchTemplate中,较之其他的CV提供的匹配方法,该算法对于光照、噪音等等的影响,稳定性更佳,也是halcon等商用软件内嵌的基于像素的模板匹配标准方法。
他的理论匹配度范围是[-1,1],为-1时表示2副图像的极性完全相反(原图和反色后的图),为1则表示两幅图完全一样。一般我们在计算NCC的时候都是取的绝对值,因此,通常NCC的取值为[0,1],值越大,表示两幅图像越相似。
实际编程实现时,千万不要直接用这个公式,如果你使用,那你离砸电脑已经不远了,请一定要相信我。
实际中,我们都用下面的式子来实现编码(不要问我里面的符号的意思,两个图来自不同的资料,里面的字母也不一样,但是要研究的这个的人都应该能看懂):
 (2)
(2)
这个式子看上去更为复杂,但是实质上和公式(2)和公式(1)就是同一个东西。公式(2)我们可以把他拆解为7个部分。我们一1道来。
①、这个留到最后在说。
②、T代表的是模板,那么②对于固定的模板来说就是一个定值,在匹配前可以直接计算好,无需担忧耗时问题。
③、I 表示的搜索图像中的和模板一样大的一个子块,很明显这个累加有多重方法可以快速的实现,比如比较原始的积分图技术,或者我的BoxBlur里的那种更为快速的实现,这一项也是和参数无关的。
④、第四项处理方式同 ②项,无需多言。
⑤、第五项完全同第二项,同时四和五项作为一个整体也可以提前计算好,不参与匹配过程的计算。
⑥、第六项处理方式同第三项,也无需多言。
⑦、第七项完全同第三项,直接使用。
前面的分析表明,第二至第七项要买可以作为常量提前计算好,要么就可以通过某种技术实现O(1)的快速计算,那么现在我们再回过头来在看第①项,他是模板图像和搜索图像同面积区域像素的一个卷积,这个是无法用某种优化技巧去实现和模板大小无关的快速实现的,注定了他就是NCC计算式中最为耗时的部分。
有人说卷积可以有FFT实现优化,没错,非常同意您的观点,但是,朋友,FFT虽然其第一个F代表了Fast,但是呢他在傅里叶的世界是快的,在我们模板匹配的空间内他受到了一种无形的压迫,在工业界还是无法接受的。
因此,我们注意到在本例中,这个卷积其实都是字节类型的计算,对于一个N*M大小的模板图,这个卷积需要N*M次乘法以及N*M-1次加法,由于是整数计算,本身运算速度还算比较快的,而且如果在PC上我曾经提及过有一种使用SIMD指令的提速方法,大概能有10倍的运力提高,核心是使用_mm_madd_epi16(对应PMADDWD这个指令)。
其原理如下:
_m128i _mm_madd_epi16(__m128i a, __m128i b)
Multiplies the 8 signed 16-bit integers from a by the 8 signed 16-bit integers from b Adds the signed 32-bit integer results pairwise and packs the 4 signed 32-bit integer results.

该指令可以一次性执行8个16位数据的乘法及4次加法,而我们只要提前把8为字节数据转换为16为数据就可以了, 通常这可以由_mm_unpacklo_epi8或者_mm_ cvtepu8_epi16实现。
2、进一步提升
有了上一步的分析,也许你就准备开始动工了,千里之行始于足下嘛,但是作为过来人,我奉劝你除非是为了看效果,否则,你还是等一等吧,下面的更精彩。
如果我们按照公式(2)就开始霸王硬上弓,大部分情况下你需要耐心的盯着你的屏幕鼠标在那里转圈转圈转个10来秒吧,然后就可以见证奇迹了,也许作为初学者,你会心动,而那些需要靠这个吃饭的,可能就是心痛了.........
为了得到更快的搜索速度,一个最容易想到的策略就是图像金字塔,图像金字塔每增加一层,图像的点数和模板的点数救减少4倍(理论数据,实际由于非2的宽度和高度,不一定正好是4倍),那么不考虑Cache等其他的因素,理论上每增加一层金字塔救可以提速16倍,因此,如果我们构建了一个4层的金字塔,那么在第4层金字塔上的一次完整匹配,其计算的次数和原始的数据相比,就能减少4096倍。
我们先以无旋转单目标为例进行简单的说明,当我们在金字塔最高层进行一次完整的匹配后,我们可以找一个全局的极值点,这就是在顶层匹配时的最佳匹配位置,此时,我们可以将顶层匹配的结果映射到金字塔的下一层中,简单的说就是将找到的匹配点坐标的X/Y值乘以2,那么为了保证在下一层中的精度,此时的搜索区域需要适当的增大,比如选择匹配点周围5*5或者7*7的一个区域,然后在这感兴趣的区域中再进行一个局部的匹配计算,此时只需要计算25或者49次小匹配的计算,当计算完毕后,再次提取出这个小区域的极值,作为本层的最终种子点,重复这个过程,直到金字塔的最底层(即原始搜索图像)为止。
稍微分析下,假定上述我们的搜索的局部范围为5*5大小,金字塔取为4层,那么整体的计算量是原始直接计算的多少呢,这样评价:
 式中M和N分别表示图像的宽度和高度。
式中M和N分别表示图像的宽度和高度。
一般来说M和N都是至少以百为单位的,因此上述计算式的结果相当小,速度可以得到极大的提升。
这里针仅对一个问题进行展开,即金字塔构建时采用何种下采样算法,讨论如下:
①、最近邻,这个结果太粗糙,不利于算法稳定性,可以直接Pass掉。
②、双线性插值,这个兼顾速度和效果,是个可以考虑的选项。
③、三次立方插值,这个东西在图像放大时是个不错的选项,而金字塔得建立是缩小过程。
④、兰索斯插值,这个类似于三次立方插值。
⑤、采用严格的高斯金字塔采样矩阵,一个5*5的矩阵,如下所示:

对于缩小,其实③④⑤都不是很好,③内部是一个4*4的取样,④是一个8*8的取样,我举一个简单的例子。





原图(注意红色框部分的效果) 最近邻 双线性 三次立方 兰索斯
大家可用大一点的屏幕去观察,可以看到红色方框内在原图部分为非常光滑的,而四个插值中,最近邻有所模糊,三次立方和兰索斯在风车叶片边缘出现了锯齿,只有双线性完美的保存了叶片的边缘光滑性。
那么经过我的实测,一种更好的方式是直接使用2*2均值下采样,也就是使用2*2区域内的所有像素的平均值,2*2均值滤波器有一个非常好的特性,他没有频率响应问题,而较大的滤波器均存在该问题。同时,使用该滤波器还有一个优异的特性,即他可以以非常高效的方式实现。
当图像的宽度和高度都为2的整数倍时,如果选用双线性插值建立下一层金字塔,此时的双线性就退化为了2*2均值滤波器。
这里留一个问题大家共同探讨吧:
问题1: 使用2*2均值滤波器时,对于非偶数的宽度和高度,比如W0 = 101,下一层金字塔的宽度W1到底是取50,还是取51呢,如果取51,那么第51个像素如何获取结果(2*2取样会越界)呢?
3、多目标
现实中通常需要在一副原图中寻找多个匹配的目标,此时,我们的难度就有所上升了,金字塔我们依旧还可以使用,但是如何区分多目标呢。
在单目标时,我们对最高层金字塔进行了全图匹配后,只需要取最大的匹配值作为候选点,这也是理所当然的,当问题来到多目标时,一个自然的想法就是对匹配值进行排序,然后取前N个最大值作为候选点。但是,这种直接的想法确实非常的不科学的,因为通常在某个最大值附近,由于邻域的相似性,还存在很多和最大值非常接近的得分点,而他们实际上都是对应同一个目标。
在百度搜索多目标模板匹配,大部分情况你会找到如下的一段代码:
Point getNextMinLoc(Mat &result, Point minLoc, int maxValue, int templatW, int templatH)
{
int startX = minLoc.x - templatW / 3;
int startY = minLoc.y - templatH / 3;
int endX = minLoc.x + templatW / 3;
int endY = minLoc.y + templatH / 3;
if (startX < 0 || startY < 0)
{
startX = 0;
startY = 0;
}
if (endX > result.cols - 1 || endY > result.rows - 1)
{
endX = result.cols - 1;
endY = result.rows - 1;
}
int y, x;
for (y = startY; y < endY; y++)
{
for (x = startX; x < endX; x++)
{
float *data = result.ptr<float>(y); data[x] = maxValue;
}
}
double new_minValue, new_maxValue;
Point new_minLoc, new_maxLoc;
minMaxLoc(result, &new_minValue, &new_maxValue, &new_minLoc, &new_maxLoc);
return new_minLoc;
}
这是一段比较好的参考代码,但是仅仅是比较好,还不能解决很多问题,但是我们可以从中学习到一些东西。
代码中输入参数中有一个参数是前一次的最小值的坐标,然后在这个坐标附近一定的矩形范围内(上述代码是模板图像的1/3尺寸),将得分值修改为某个很大的值,接着再进行全范围的最大和最小值定位,此时,肯定就定位到了离输入最小值有一定距离的另外一个最小值,而输入最小值附近的那些次小值就不会干扰结果。
注意上面代码是最小值,因为他用的检测指标是CV_TM_SQDIFF_NORMED,而非NCC,对于NCC,则需要归为最大值。
这里的templatW / 3和templatW / 3有点重叠范围的意思了,但是还完全不够。
在最顶层金字塔中找到了多个目标的粗糙位置后,就可以和前所述的一样的方式一步一步的向下一层金字塔进行细化,直到处理到顶层金字塔为止。
4、多目标+多角度
当问题来到这里时,整个的难度就是阶跃式的提高了一个档次。
如果目标存在旋转,为了能找到发生旋转的物体,我们可以创建多个方向的旋转对象,也就是说,将搜索空间离散化,此时,有两个可选的方式:一个是旋转搜索图像,然后用模板在旋转后的图像中搜索,二是旋转模板,用旋转后的模板在搜索图像中定位。我们说,第一种方式基本不可取,原因有三。
(1)、搜索图像一般来说都是较大的图,对其进行旋转耗时比较可观。、
(2)、实际情况需要多个角度的旋转,对原图旋转内存方面也会有过多的消耗
(3)、工业应用时,一般模板比较固定,而搜索图像总是时刻变化的。
当选择第二种方法时,对于较小的模板图像,是可以在执行搜索前把相关旋转信息提前准备好,在搜索时刻直接使用,而无需做无谓的耗时。
此时,在金字塔的最顶层,需要做的计算工作也有所增加,我们需要对每个角度的模板都做一个全图的匹配,得到匹配的结果,然后对每个可能点,选择匹配度最大的那个角度作为顶层的候选点。
类似的,在向下一层金字塔映射时,不仅仅需要映射匹配点的X和Y坐标,还需要映射角度信息,同理,为了保证角度方面的精度,也需要适当的扩大角度的搜索区间。
5、更多的问题
实际上,为了实现多目标和多角度的匹配,还存在很多很多的细节问题,需要取研究,这些方面的细节有些已经有了部分结论,但是大部分在网络上鲜有探讨和方向,这里列出一些问题和大家共同探讨一番。
问题2:金字塔多少层比价合适?
前面提到了金字塔层数越多,所需的计算量就越少,但是同时带来一个问题,就是计算的精度会越来越差,这是因为,随着金字塔层数的增加,因为二次采样图像会不断的得到平滑,在图像分辨率变得太低时一些基本的特征已经完全丢失,各种本来不想关的信息已经完全融合在一起了。因此,一个合适的金字塔层数就尤为重要。一些成熟的商业软件一般可提供用户自行输入金字塔层数,或者自动确定。对于大部分用户而言,他们不懂得更多的技术细节,自动设置显得尤为重要。
我们以工业界最为出色Halcon软件为例,经过多次测试,他的金字塔层数的自动设置是非常智能化的,基本上自动可以保证速度最优同时效果稳定,通常,我们认为金字塔的层数只和模板图像的尺寸有关,但是,一些仔细的测试表明,两幅同样大小的模板图,halcon也有可能但不一定返回不同的值,估计这其中还用到了图像的一些相似性或者结构方面的一些信息作出的综合判断,不过,一个最基本的规律,还是可以分享下,那就是如果金字塔某层的短边像素小于或者等于8了,你们这肯定是此模板金字塔层数的极限了。
问题3:角度离散化的间距如何设置最为合理?
类似于金字塔,角度离散化的间距越大,需要计算的旋转方面的信息就越少,速度则可以更快,但是同样,精度就越差。
一般来说,如果模板越大,离散化的间距则需要越小,这是因为较大的模板能够区别更小角度的变化。通常,对于大小100像素的模板,离散的角度步幅可设置为1度。同样,如何自动的设置参数也应该是一个成熟软件的标志,一个可行的建议是离散的步长需要保证旋转时两个相邻模板之间的长或宽的最小差异值不小于1个像素。
问题4:模板的旋转如何处理?
通常可以用双线性插值或者三次立方插值,来获取旋转后的数据,不建议用最近邻算法,但是不同的旋转算法,最后得到的匹配结果会有所不同,同时这也就说呢,其实带角度的模板匹配,理论上很难获取精确解,因为你毕竟不知道原始的旋转算法是何种,比如我从一个未旋转图像中扣一个矩形出来作为模板, 然后把图像旋转各10度,用halcon对模板进行匹配,得到的结果哪怕选择亚像素也不会是精确的10度。
问题5:旋转后无效数据的部分怎么办?
在对模板进行旋转时,除非是几个特殊的角度,比如0、90、270、360度,不会产生额外的信息,其他的角度,都会有一些未知的区域存在,如下图所示:



原 图 旋转一定的角度 (双线性插值) 边缘处局部放大
中间为旋转后的模板,红色部分为新出现的未知区域,如果说我们这个图作为一个整体,去和原图像进行匹配,也就是说让红色部分参与了匹配,这很明显会得到一个得分较低的错误结果。
一种也许可行的方式是,我们把这些红色的区域剔除在匹配有效的数据之外,这时,又会面临另外一个新的问题,在图像的边缘部分如何处理。在上面边缘处局部的方法图中,我们可以看到,由于插值的特性,边缘处未能在原始图像中采集到足够的采样点,因此,选择了红色背景色作为融合的基色,此时的结果像素就不完全是属于原始图像了,怎么办?个人的一个建议是既然这部分像素也被污染了,那就不应该参与后续的匹配。
此时,在编程方面就需要继续克服下一个困难了,前面概述方面讲的一些优化方式又不能直接使用了, 真是他妈的痛苦,所以,借用某一本书里的经典劝退名言吧:聪明的机器视觉用户都依赖标准软件包来提供这些功能而不会试着自己实现这些算法。
问题6:各层金字塔的角度离散值如何分配?
通常,在金子塔的最底层(和原图一样大小那一层),可按照前述的自动角度幅值来一步一步的旋转图像,然后随着金字塔的层数增加,根据模板在每层金字塔中都会缩小2倍的这个事实,在相应金字塔上模板的角度步幅也可以增加2倍,因此,如果在金字塔最底层上使用的角度步幅喂1度,那么在第四层上可以使用8度作为角度步幅。
这样做带来的好处有很多,因为,通常,我们需要在最顶层做多角度的全图的匹配,这个计算的相对来说比较大,如果角度步幅在该层得以以指数级别减少,则计算量也会有量级的降低。
问题7:各层金字塔的最低得分值如何确定?
前面一直没提这个得分的问题,在单目标中一般是不存在这个问题的,当有多个目标时,因为可能不是完整的匹配,因此一般需要客户确定一个最小的得分值,当然这个得分是指的在最底层时的值。当有了金字塔后,因为下采样的一些因素,为了有更高的容错率,一般是建议每增加一层金字塔,最小的得分值需要适当的降低。比如,用户设置的最小得分为0.8,后续各层的得分可以为:
0.8 0.8*0.9 0.8*0.9*0.9 0.8*0.9*0.9 * 0.9
当然,其他的调整方式也未尝不可以,但是,总体的区域需保证最小得分越来越低。
问题8:MaxOverlap是什么鬼,内部是如何操作的?
在Halcon中,还有非常重要的参数-MaxOverlap,一个介于0和1之间的参数,前面也一直没有谈到过。其实,在真正的应用中,存在着一些目标之间有一定程度重叠的情况,这个时候,如果按照前面的那些处理方式,一般就只能获取到重叠对象的某一个,而丢掉了其他的信息。当有了MaxOverlap参数时,我们就可以根据这些对象的重叠重复,来决定是否剔除掉某一个不需要的目标。
但是,这也是一个比较难以琢磨的对象,Halcon帮助文档中的说法是取的对消的最小外接矩形中的重叠比例。说实在的,编程时,这个规则应该还不够。比如,如果有4个对象,他们都有所重叠,请问这个时候,这个MaxOverlap是指的所有的重叠量合并在一起呢,还是最大的重叠,抑或是按照得分顺序第一个和之重叠的呢。目前,我也是对这个比较摇摆。
同时,另外一个比较难以确定问题是,这个重叠是在金字塔的最顶层就进行判断还是如何呢,如果在金字塔的最顶层不进行判断,那么金字塔顶层中得分大于MinScore的则有很多个点,如果把这些点都直接向上一层进行映射,那个计算量也是相当客观的。
问题9:亚像素坐标和角度是一起执行的吗,还是分开的?
没有亚像素的模板匹配是没有灵魂的,特别是带有角度的匹配。因为,正如前面所述,我们对角度采用了离散化。那么这个时候计算的最终角度结果必然是离散化后的序列里的某个值,这样的精度有的时候是不够的。
通过亚像素技术,寻找局部区域里的最大值,课获得更高的位置精度和角度精度,则可以有效的获得精准的定位。
但是目前还是不清楚坐标+角度组成的4维的空间的亚像素计算公式是如何的。
问题10:速度优化?
以上谈的一些优化基本上是结构上的优化,或者说原理上的优化,在编码上还可以考虑时候用SIMD指令进行处理,尤其是全图匹配的计算过程。
6、公关成果
大概前前后后再一起有折腾了大概一年的时间吧,初步还是有了一定的成果,无论是在速度上,还是在准确度中,还是能解决一定的工程问题了。
共享一些测试图,和大家一起比较。



模板图 待搜索图 搜索结果



模板图 待搜索图 搜索结果
基于NCC的速度方面和很多参数有关,比如角度的搜索范围,金字塔层数,模板的大小(一般模板大,速度反而快些,特别小的模板则非常耗时,知道原因吗?),重叠的大小等等都有关。一些简单的测试数据如下:
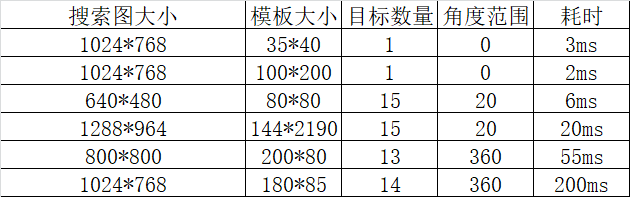
虽然历经千辛万苦,在磨砺了很久之后,也对这个初有小成,基本实现了这样的一些过程,但是和halcon相比,无论是从稳定性还是效率方面都还是有一定的差距的,所以标题中的无限接近 就是一句诳语而已。
本算法目前已经集成到国产视觉软件Malcon中,详情请看中国的Malcon跟德国的Halcon的相比的优缺点。
Malcon官方博客:https://www.cnblogs.com/Malcon
或者点击: https://blog.csdn.net/lindrs/article/details/114113280?spm=1001.2014.3001.5502
Malcon中还集成了很多其他常用的200多个算子,相信您一种能从其中找到你所需要的。
如果你希望有一个简单的可视化测试界面,可以从如下链接中获取,但是请注意这个Demo本身是有一些BUG的(不影响测试使用),请不要将其直接应用到工业环境中,以免造成不必要的损失。

可视化测试Demo: https://files.cnblogs.com/files/Imageshop/TemplateMatching.rar
7、更多疑惑
弄得越多,发现不了解的也越多,特别是在研究比对Halcon的过程中,还发现了一些暂时没有弄清楚的事情,比如:
①、在不勾选亚像素时,Halcon返回的坐标值很多情况下也是带小数点(特别是非0度时的结果),这个作何解释。
②、当模板的理论角度是0度时,即使按照AngleStart和AngleStep的值依次计算,取样的角度值不会准确的取为0,而且也未勾选亚像素,他也能正确的返回0值,难道他对0度做了特别的处理吗?
这些还需要慢慢的取探索。
如果您觉得本博文对您有所帮助,也可慷慨解囊。

【工程应用一】 多目标多角度的快速模板匹配算法(基于NCC,效果无限接近Halcon中........)的更多相关文章
- IAR更改代码字体&快速模板设置。——Arvin
1.是用软件提供的字体 如果只想简单的设置,可进行如下设置Tools->IDE Options->Editor->Colors and Fonts->Editor Font-& ...
- 【工程应用七】接着折腾模板匹配算法 (Optimization选项 + no_pregeneration模拟 + 3D亚像素插值)
在折腾中成长,在折腾中永生. 接着玩模板匹配,最近主要研究了3个课题. 1.创建模型的Optimization选项模拟(2022.5.16日) 这两天又遇到一个做模板匹配隐藏的高手,切磋起来后面就还是 ...
- OpenCV模板匹配算法详解
1 理论介绍 模板匹配是在一幅图像中寻找一个特定目标的方法之一,这种方法的原理非常简单,遍历图像中的每一个可能的位置,比较各处与模板是否“相似”,当相似度足够高时,就认为找到了我们的目标.OpenCV ...
- Photoshop将普通照片快速制作二次元漫画风格效果
今天为大家分享Photoshop将普通照片快速制作二次元漫画风格效果,教程很不错,对于喜欢漫画的朋友可以参考本文,希望能对大家有所帮助! 一提到日本动画电影,大家第一印象肯定是宫崎骏,但是日本除了宫崎 ...
- Kcptun 是一个非常简单和快速的,基于KCP 协议的UDP 隧道,它可以将TCP 流转换为KCP+UDP 流
本博客曾经发布了通过 Finalspeed 加速 Shadowsocks 的教程,大家普遍反映能达到一个非常不错的速度.Finalspeed 虽好,就是内存占用稍高,不适合服务器内存本来就小的用户:而 ...
- 快速搭建一个基于react的项目
最近在学习react,快速搭建一个基于react的项目 1.创建一个放项目文件夹,用编辑器打开 2.打开集成终端输入命令: npm install -g create-react-app 3. cre ...
- 【工程应用五】 opencv中linemod模板匹配算法诸多疑惑和自我解读。
研究这个前前后后也有快两三个月了,因为之前也一直在弄模板匹配方面的东西,所以偶尔还是有不少朋友咨询或者问你有没有研究过linemod这个算法啊,那个效率啥的还不错啊,有段时间一直不以为然,觉得我现在用 ...
- 对拍 bat命令快速模板
对拍.bat @echo off :loop maker.exe > in.in wq.exe < in.in > out.out std.exe < in.in >st ...
- 借助 SIMD 数据布局模板和数据预处理提高 SIMD 在动画中的使用效率
原文链接 简介 为发挥 SIMD1 的最大作用,除了对其进行矢量化处理2外,我们还需作出其他努力.可以尝试为循环添加 #pragma omp simd3,查看编译器是否成功进行矢量化,如果性能有所提升 ...
随机推荐
- how HTTPS works
How HTTPS works HTTPS comic tutorials How HTTPS works ...in a comic! https://howhttps.works/ A cat e ...
- CSS 设置多行文本省略号 ...
CSS 设置多行文本省略号 ... .box{ display: -webkit-box; overflow: hidden; text-overflow: ellipsis; word-wrap: ...
- HTML Custom Elements & valid name
HTML Custom Elements & valid name valid custom element name https://html.spec.whatwg.org/multipa ...
- how to disabled prefers-color-scheme in js & dark theme
how to disabled prefers-color-scheme in js dark theme https://developer.mozilla.org/en-US/docs/Web/C ...
- JDK源码阅读-FileOutputStream
本文转载自JDK源码阅读-FileOutputStream 导语 FileOutputStream用户打开文件并获取输出流. 打开文件 public FileOutputStream(File fil ...
- mysql主从备份说明(win系统)
1. 环境描述: 主机:192.168.2.201 从机:192.168.2.111 Mysql版本:5.7 2. 主机my.ini配置: log-bin=C:\mysqlback expire-lo ...
- Maven遇到的各种问题
1.遇到报错-Dmaven.multiModuleProjectDirectory system propery is not set.Check $M2_HOME environment varia ...
- 在vscode中用Git管理项目
1.新建仓库-->填写仓库名称-->一定要将对钩去掉-->公开-->创建 Git全局设置: git config --global --add user.name " ...
- Python和JavaScript在使用上有什么区别?
转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具.解决方案和服务,赋能开发者. 原文出处:https://www.freecodecamp.org/news/python-vs-javas ...
- Portainer中文汉化
一.概述 Portainer是Docker的图形化管理工具,提供状态显示面板.应用模板快速部署.容器镜像网络数据卷的基本操作(包括上传下载镜像,创建容器等操作).事件日志显示.容器控制台操作.Swar ...