Apache Hudi + AWS S3 + Athena实战
Apache Hudi在阿里巴巴集团、EMIS Health,LinkNovate,Tathastu.AI,腾讯,Uber内使用,并且由Amazon AWS EMR和Google云平台支持,最近Amazon Athena支持了在Amazon S3上查询Apache Hudi数据集的能力,本博客将测试Athena查询S3上Hudi格式数据集。
1. 准备-Spark环境,S3 Bucket
需要使用Spark写入Hudi数据,登陆Amazon EMR并启动spark-shell:
$ export SCALA_VERSION=2.12
$ export SPARK_VERSION=2.4.4
$ spark-shell \
--packages org.apache.hudi:hudi-spark-bundle_${SCALA_VERSION}:0.5.3,org.apache.spark:spark-avro_${SCALA_VERSION}:${SPARK_VERSION}\
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
...
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.4
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 1.8.0_242)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
接着使用如下scala代码设置表名,基础路径以及数据生成器来生成数据。这里设置basepath为s3://hudi_athena_test/hudi_trips,以便后面进行查询
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val tableName = "hudi_trips"
val basePath = "s3://hudi_athena_test/hudi_trips"
val dataGen = new DataGenerator
2. 插入数据
生成新的行程数据,导入DataFrame,并将其写入Hudi表
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Overwrite).
save(basePath)
3. 创建Athena数据库/表
Hudi内置表分区支持,所以在创建表后需要添加分区,安装athenareader工具,其提供Athena多个查询和其他有用的特性。
go get -u github.com/uber/athenadriver/athenareader
接着创建hudi_athena_test.sql文件,内容如下
DROP DATABASE IF EXISTS hudi_athena_test CASCADE;
create database hudi_athena_test;
CREATE EXTERNAL TABLE `trips`(
`begin_lat` double,
`begin_lon` double,
`driver` string,
`end_lat` double,
`end_lon` double,
`fare` double,
`rider` string,
`ts` double,
`uuid` string
) PARTITIONED BY (`partitionpath` string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT 'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION 's3://hudi_athena_test/hudi_trips'
ALTER TABLE trips ADD
PARTITION (partitionpath = 'americas/united_states/san_francisco') LOCATION 's3://hudi_athena_test/hudi_trips/americas/united_states/san_francisco'
PARTITION (partitionpath = 'americas/brazil/sao_paulo') LOCATION 's3://hudi_athena_test/hudi_trips/americas/brazil/sao_paulo'
PARTITION (partitionpath = 'asia/india/chennai') LOCATION 's3://hudi_athena_test/hudi_trips/asia/india/chennai'
使用如下命令运行SQL语句
$ athenareader -q hudi_athena_test.sql
4. 使用Athena查询Hudi
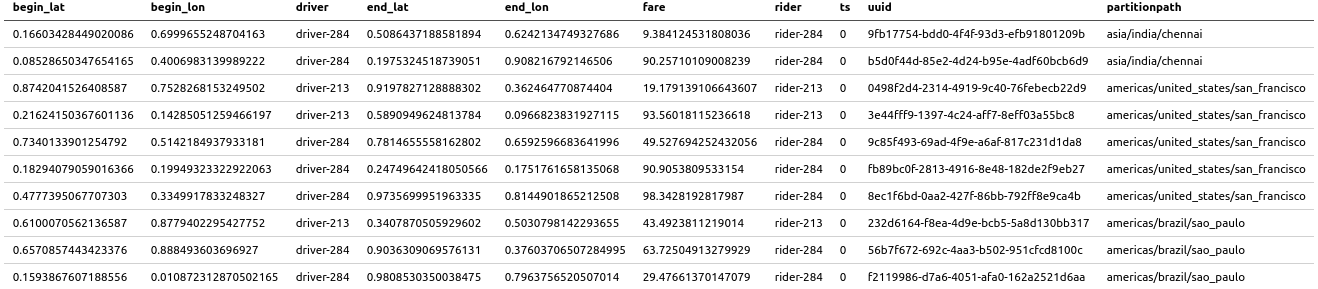
如果没有错误,那么说明库和表在Athena中都已创建好,因此可以在Athena中查询Hudi数据集,使用athenareader查询结果如下
athenareader -q "select * from trips" -o markdown
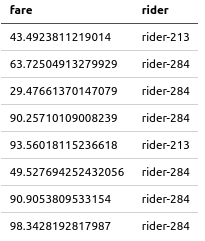
也可以带条件进行查询
athenareader -q "select fare,rider from trips where fare>20" -o markdown
5. 更新Hudi表再次查询
Hudi支持S3中的数据,回到spark-shell并使用如下命令更新部分数据
val updates = convertToStringList(dataGen.generateUpdates(10))
val df = spark.read.json(spark.sparkContext.parallelize(updates, 2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath)
运行完成后,使用athenareader再次查询
athenareader -q "select * from trips" -o markdown
可以看到数据已经更新了

6. 限制
Athena不支持查询快照或增量查询,Hive/SparkSQL支持,为进行验证,通过spark-shell创建一个快照
spark.
read.
format("hudi").
load(basePath + "/*/*/*/*").
createOrReplaceTempView("hudi_trips_snapshot")
使用如下代码查询
val commits = spark.sql("select distinct(_hoodie_commit_time) as commitTime from hudi_trips_snapshot order by commitTime").map(k => k.getString(0)).take(50)
val beginTime = commits(commits.length - 2)
使用Athena查询将会失败,因为没有物化
$ athenareader -q "select distinct(_hoodie_commit_time) as commitTime from hudi_trips_snapshot order by commitTime"
SYNTAX_ERROR: line 1:57: Table awsdatacatalog.hudi_athena_test.hudi_trips_snapshot does not exist
根据官方文档,Athena支持查询Hudi数据集的Read-Optimized视图,同时,我们可以通过Athena来创建视图并进行查询,使用Athena在Hudi表上创建一个视图
$ athenareader -q "create view fare_greater_than_40 as select * from trips where fare>40" -a
查询视图
$ athenareader -q "select fare,rider from fare_greater_than_40"
FARE RIDER
43.4923811219014 rider-213
63.72504913279929 rider-284
90.25710109008239 rider-284
93.56018115236618 rider-213
49.527694252432056 rider-284
90.9053809533154 rider-284
98.3428192817987 rider-284
Apache Hudi + AWS S3 + Athena实战的更多相关文章
- 使用Apache Hudi + Amazon S3 + Amazon EMR + AWS DMS构建数据湖
1. 引入 数据湖使组织能够在更短的时间内利用多个源的数据,而不同角色用户可以以不同的方式协作和分析数据,从而实现更好.更快的决策.Amazon Simple Storage Service(amaz ...
- 使用Amazon EMR和Apache Hudi在S3上插入,更新,删除数据
将数据存储在Amazon S3中可带来很多好处,包括规模.可靠性.成本效率等方面.最重要的是,你可以利用Amazon EMR中的Apache Spark,Hive和Presto之类的开源工具来处理和分 ...
- 官宣!AWS Athena正式可查询Apache Hudi数据集
1. 引入 Apache Hudi是一个开源的增量数据处理框架,提供了行级insert.update.upsert.delete的细粒度处理能力(Upsert表示如果数据集中存在记录就更新:否则插入) ...
- 基于 Apache Hudi + Presto + AWS S3 构建开放Lakehouse
认识Lakehouse 数据仓库被认为是对结构化数据执行分析的标准,但它不能处理非结构化数据. 包括诸如文本.图像.音频.视频和其他格式的信息. 此外机器学习和人工智能在业务的各个方面变得越来越普遍, ...
- 实战 | 将Apache Hudi数据集写入阿里云OSS
1. 引入 云上对象存储的廉价让不少公司将其作为主要的存储方案,而Hudi作为数据湖解决方案,支持对象存储也是必不可少.之前AWS EMR已经内置集成Hudi,也意味着可以在S3上无缝使用Hudi.当 ...
- Apache Hudi C位!云计算一哥AWS EMR 2020年度回顾
1. 概述 成千上万的客户在Amazon EMR上使用Apache Spark,Apache Hive,Apache HBase,Apache Flink,Apache Hudi和Presto运行大规 ...
- 在AWS Glue中使用Apache Hudi
1. Glue与Hudi简介 AWS Glue AWS Glue是Amazon Web Services(AWS)云平台推出的一款无服务器(Serverless)的大数据分析服务.对于不了解该产品的读 ...
- 真香!PySpark整合Apache Hudi实战
1. 准备 Hudi支持Spark-2.x版本,你可以点击如下链接安装Spark,并使用pyspark启动 # pyspark export PYSPARK_PYTHON=$(which python ...
- 实战| 配置DataDog监控Apache Hudi应用指标
1. 可用性 在Hudi最新master分支,由Hudi活跃贡献者Raymond Xu贡献了DataDog监控Hudi应用指标,该功能将在0.6.0 版本发布,也感谢Raymond的投稿. 2. 简介 ...
随机推荐
- 博弈论 | 详解搞定组合博弈问题的SG函数
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天这篇是算法与数据结构专题的第27篇文章,我们继续深入博弈论问题.今天我们要介绍博弈论当中非常重要的一个定理和函数,通过它我们可以解决许多 ...
- java不需要递归列表转树形结构
有时候我们需要将列表结构的数据转成树形结构的数据 废话不多说直接上代码 基础类 `@Data public class TreeNode { private Long id; private Long ...
- javascript : 找到一个树型数据的一个节点及其所有父节点
如题. (function () { let tree = { "id": 0, "label": "all", "childre ...
- xmake从入门到精通12:通过自定义脚本实现更灵活地配置
xmake是一个基于Lua的轻量级现代化c/c++的项目构建工具,主要特点是:语法简单易上手,提供更加可读的项目维护,实现跨平台行为一致的构建体验. 本文主要详细讲解下,如何通过添加自定义的脚本,在脚 ...
- 小白在使用ISE编写verilog代码综合时犯得错误及我自己的解决办法
一:错误原因,顶层信号声明类别错误 错误前 更改后 二:综合时警告 更改前: 错误原因:调用子模块时 输出端口只能用wire类型变量进行映射 这是verilog语法规定的 tx_done在uart_t ...
- js异步执行原理
我们都知道js是一个单线程的语言,所以没办法同时执行俩个进程.所以我们就会用到异步. 异步的形式有哪些那,es5的回调函数.es6的promis等 异步的运行原理我们可以先看下面这段代码 应该很多人都 ...
- 面试题三十:包含min函数的栈
定义一个栈的数据结构,请实现一个每次都能找到栈中的最小元素,要求时间复杂度O(1).意思就是说每次进栈出栈后,min函数总能在时间1的前提下找到.方法一:由于每次循序遍历栈的话时间复杂度为n,所以要想 ...
- MySQL操作数据库
2.操作数据库 操作数据库>操作数据库中的表>操作表中的数据 Mysql关键字不区分大小写 2.1操作数据库 2.1.1创建数据库 create database if not EXIS ...
- 花了一个月的时间在一个oj网站只刷了这些题,从此入门了绝大多数算法
如果你想入门算法,那么我这篇文章也许可以帮到你. oj网站有这么多,当然还有其他的.我当初是在hdu上面刷的,不要问我为什么,问就是当时我也是一个新手,懵懵懂懂就刷起来了.点这里可以进入这个网站htt ...
- .Net微服务实战之CI/CD
系列文章 .Net微服务实战之技术选型篇 .Net微服务实战之技术架构分层篇 .Net微服务实战之DevOps篇 .Net微服务实战之负载均衡(上) 相关源码:https://github.com/S ...