kubernetes flannel pod CrashLoopBackoff解决
背景
某环境客户部署了一个kubernetes集群,发现flannel的pod一直重启,始终处于CrashLoopBackOff状态。

排查
对于始终CrashLoopBackOff的pod,一般是应用本身的问题,需要查看具体pod的日志,通过
kubectl logs -f --tail -n kube-system flannel-xxx显示,“pod cidr not assigned”,然后flannel退出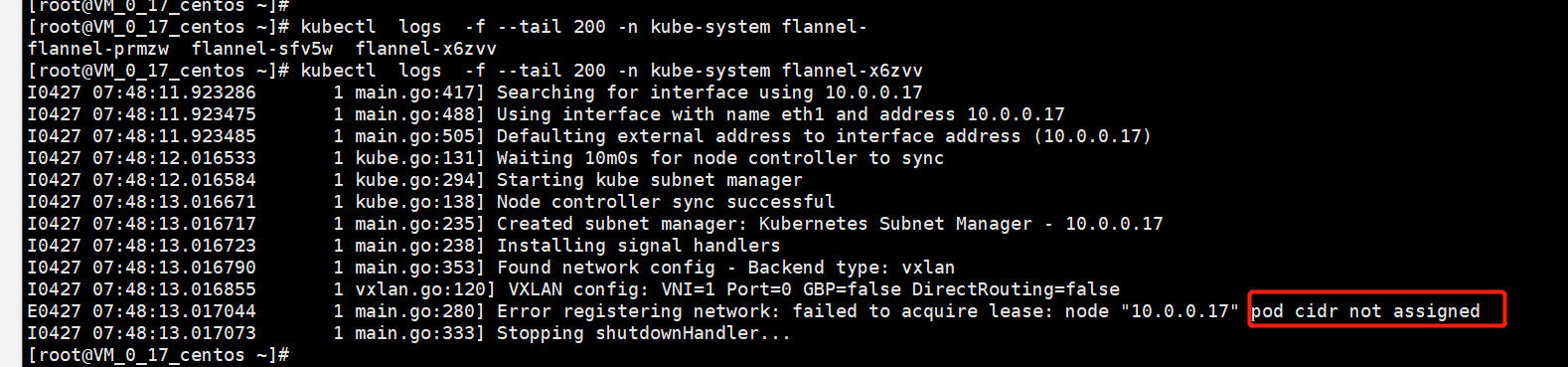
检查日志显示的节点10.0.0.17的cidr,发现确实为空,而正常的环境却是正常的。


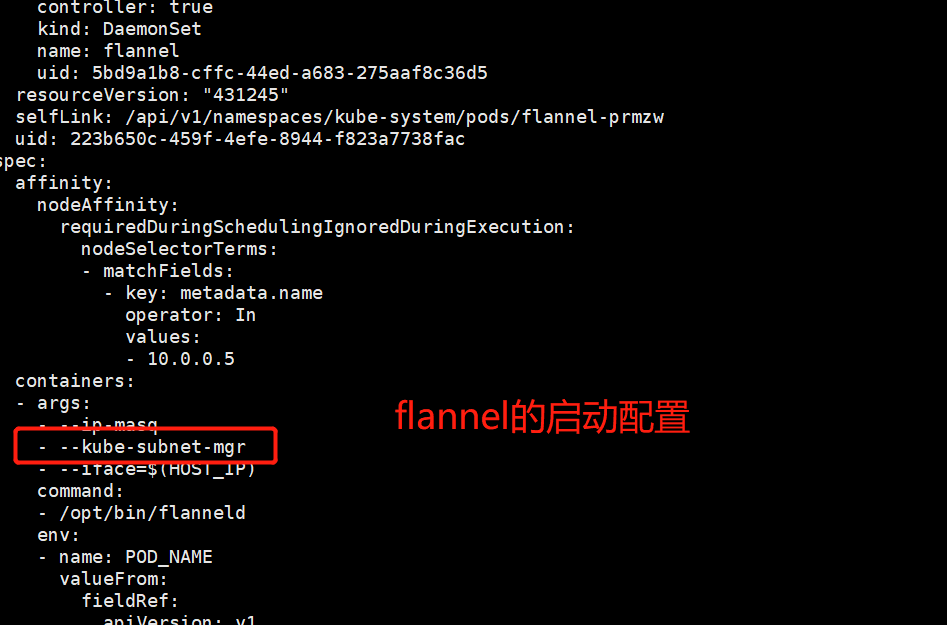
- 检查flannel的启动参数,发现为
--kube-subnet-mgr,–kube-subnet-mgr代表其使用kube类型的subnet-manager。该类型有别于使用etcd的local-subnet-mgr类型,使用kube类型后,flannel上各Node的IP子网分配均基于K8S Node的spec.podCIDR属性—"contact the Kubernetes API for subnet assignment instead of etcd.",而在第2步,我们已经发现节点的podcidr为空。
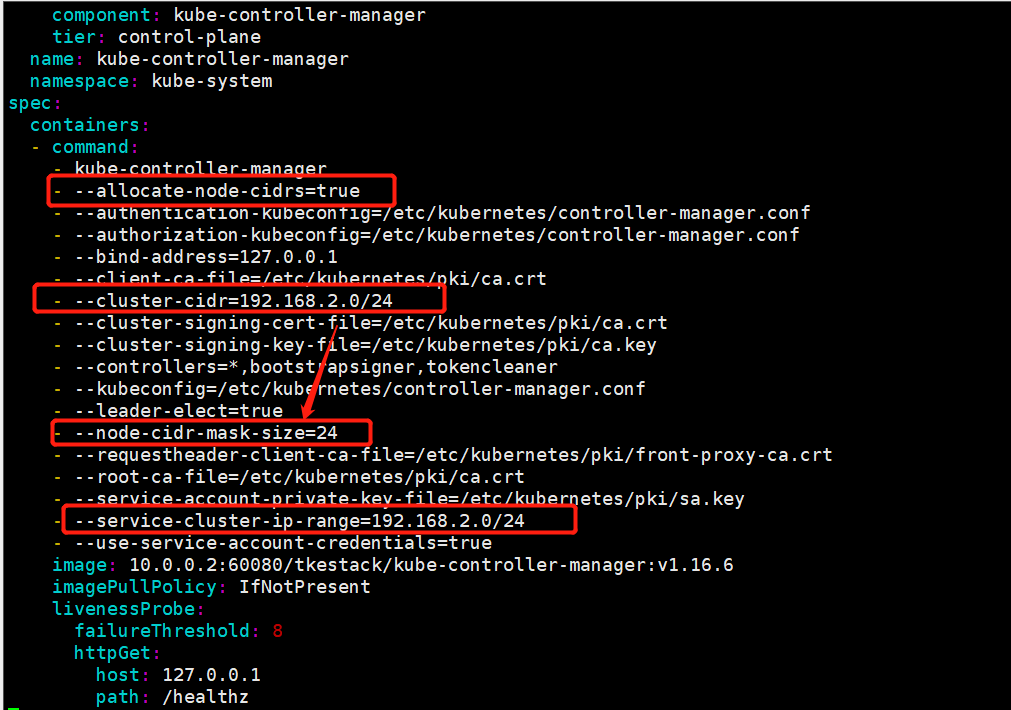
- node节点分配podCIDR,需要kube-controller-manager开启
allocate-node-cidrs为true,它和cluster-cidr参数共同使用的时候,controller-manager会为所有的Node资源分配容器IP段, 并将结果写入到PodCIDR字段.检查环境kube-controller-manager的配置文件,发现问题所在。如下图,环境设置了cluster-cidr为192.168.2.0/24,同时设置了node-cidr-mask-size为24,node-cidr-mask-size参数,用来表示kubernetes管理集群中节点的cidr掩码长度,默认是24位,需要从cluster-cidr里面分配地址段,而设置的cluster-cidr显然无法满足这个掩码要求,导致kube-controller-manager为节点分配地址失败。
后记
综上,可以修改node-cidr-mask-size参数为24以上的数解决node没法分配podcidr问题,但是同时发现环境部署使用的kubernetes自动化工具分配集群的service-cluster-ip-range也是从cluster-cidr里面取一段,分配不满足竟然使用了和cluster-cidr一样的地址,造成网段冲突。最终,让客户重新规划了网段,修改cluster-cidr掩码从24位改为16位,后续flannel均启动正常。
kubernetes flannel pod CrashLoopBackoff解决的更多相关文章
- kubernetes删除pod一直处于terminating状态的解决方法
kubernetes删除pod一直处理 Terminating状态 # kubectl get po -n mon NAME READY STATUS RESTARTS AGE alertmanage ...
- Kubernetes之Pod使用
一.什么是Podkubernetes中的一切都可以理解为是一种资源对象,pod,rc,service,都可以理解是 一种资源对象.pod的组成示意图如下,由一个叫”pause“的根容器,加上一个或多个 ...
- centos下kubernetes+flannel部署(旧)
更合理的部署方式参见<Centos下Kubernetes+Flannel部署(新)> 一.准备工作 1. 三台centos主机 k8s(即kubernetes,下同)master: 10. ...
- Kubernetes探索学习004--深入Kubernetes的Pod
深入研究学习Pod 首先需要认识到Pod才是Kubernetes项目中最小的编排单位原子单位,凡是涉及到调度,网络,存储层面的,基本上都是Pod级别的!官方是用这样的语言来描述的: A Pod is ...
- kubernetes之pod健康检查
目录 kubernetes之pod健康检查 1.概述和分类 2.LivenessProbe探针(存活性探测) 3.ReadinessProbe探针(就绪型探测) 4.探针的实现方式 4.1.ExecA ...
- Kubernetes基石-pod容器
引用三个问题来叙述Kubernetes的pod容器 1.为什么不直接在一个Docker容器中运行所有的应用进程. 2.为什么pod这种容器中要同时运行多个Docker容器(可以只有一个) 3.为什么k ...
- Kubernetes服务pod的健康检测liveness和readiness详解
Kubernetes服务pod的健康检测liveness和readiness详解 接下来给大家讲解下在K8S上,我们如果对我们的业务服务进行健康检测. Health Check.restartPoli ...
- kubernetes调度pod运行于master节点上
应用背景: 使用kubeadm部署的kubernetes集群,其master节点默认拒绝将pod调度运行于其上的,加点官方的术语就是:master默认被赋予了一个或者多个“污点(taints)”,“污 ...
- kubernetes concepts -- Pod Overview
This page provides an overview of Pod, the smallest deployable object in the Kubernetes object model ...
随机推荐
- 监控CPU与GPU的工具
1.sensor:可以显示包括cpu在内的所有传感器的当前读数 使用sensors可以检测到cpu的温度,风扇的风速度,电压等. 2.Glances使用Python写的跨平台的curses的检测工具. ...
- 2019-2020-1 20199328《Linux内核原理与分析》第三周作业
加载内核 这里可以看出有些东西隔一段时间就会打印出来 查看mymain.c 开头的一些语句不再描述 每10000次循环打印一次 这里还是针对的mymain.c文件,这里我们可以根据自己的计算机对频率进 ...
- ElasticSearch 镜像 & 安装 & 简易集群
目录 ES镜像 JDK镜像 安装 1. 安装JDK 2. 解压安装ES 3. 配置 4. 新建用户 5. 启动 踩坑 1. root启用报错 2. max file descriptors [4096 ...
- 事件总线功能库,Reface.EventBus 详细使用教程
Reface.AppStarter 中的事件总线功能是通过 Reface.EventBus 提供的. 参考文章 : Reface.AppStarter 框架初探 使用 Reface.EventBus ...
- Node.js快速创建一个访问html文件的服务器
var http = require('http'), // 引入需要的模块 fs = require('fs'), //引入文件读取模块 cp = require('child_process'), ...
- 导入sql错误
2019独角兽企业重金招聘Python工程师标准>>> 导入sql错误: This function has none of DETERMINISTIC, NO SQL, or RE ...
- 数学--数论--HDU1576 A / B(逆元)
问题描述 要求(A / B)%9973,但由于A很大,我们只被告知n(n = A%9973)(我们给定的A必能被B整除,且gcd(B,9973)= 1). 输入项 数据的第一行是一个T,表示有T组数据 ...
- HDOJ 4699 Editor 对顶栈模拟
Editor Time Limit: 3000/2000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others) Total Subm ...
- 去 HBase,Kylin on Parquet 性能表现如何?
Kylin on HBase 方案经过长时间的发展已经比较成熟,但也存在着局限性,因此,Kyligence 推出了 Kylin on Parquet 方案(了解详情戳此处).通过标准数据集测试,与仍采 ...
- System.Linq.Dynamic字符串转委托
以前一直想着有没有一个方法能够把字符串直接转化成函数的,刚好有需求就找了下,还真有. 微软地址:https://docs.microsoft.com/en-us/previous-versions/b ...