flink任务性能优化
如何提高 Flink 任务性能
一、Operator Chain
为了更高效地分布式执行,Flink 会尽可能地将 operator 的 subtask 链接(chain)在一起形成 task,每个 task 在一个线程中执行。将 operators 链接成 task 是非常有效的优化:它能减少线程之间的切换,减少消息的序列化/反序列化,减少数据在缓冲区的交换,减少了延迟的同时提高整体的吞吐量。
Flink 会在生成 JobGraph 阶段,将代码中可以优化的算子优化成一个算子链(Operator Chains)以放到一个 task(一个线程)中执行,以减少线程之间的切换和缓冲的开销,提高整体的吞吐量和延迟。下面以官网中的例子进行说明。
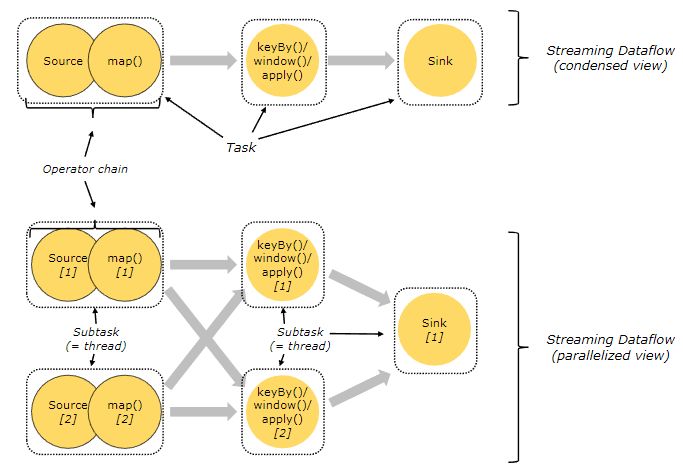
上图中,source、map、[keyBy|window|apply]、sink 算子的并行度分别是 2、2、2、1,经过 Flink 优化后,source 和 map 算子组成一个算子链,作为一个 task 运行在一个线程上,其简图如图中 condensed view 所示,并行图如 parallelized view 所示。算子之间是否可以组成一个Operator Chains,看是否满足以下条件:
l 上下游算子的并行度一致;
l 下游节点的入度为1;
l 上下游节点都在同一个slot group 中;
l 下游节点的chain策略为ALWAYS;
l 上游节点的chain策略为ALWAYS或HEAD;
l 两个节点间数据分区方式是forward;
l 用户没有禁用chain。
二、Slot Sharing
Slot Sharing 是指,来自同一个 Job 且拥有相同 slotSharingGroup(默认:default)名称的不同 Task 的 SubTask 之间可以共享一个 Slot,这使得一个 Slot 有机会持有 Job 的一整条 Pipeline,这也是上文提到的在默认 slotSharing 的条件下 Job 启动所需的 Slot 数和 Job 中 Operator 的最大 parallelism 相等的原因。通过 Slot Sharing 机制可以更进一步提高 Job 运行性能,在 Slot 数不变的情况下增加了 Operator 可设置的最大的并行度,让类似 window 这种消耗资源的 Task 以最大的并行度分布在不同 TM 上,同时像 map、filter 这种较简单的操作也不会独占 Slot 资源,降低资源浪费的可能性。
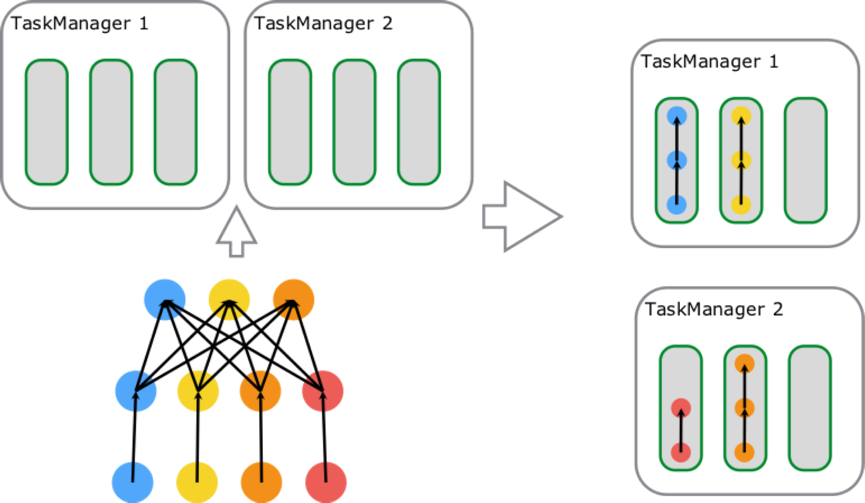
图中包含 source-map[6 parallelism]、keyBy/window/apply[6 parallelism]、sink[1 parallelism] 三种 Task,总计占用了 6 个 Slot;由左向右开始第一个 slot 内部运行着 3 个 SubTask[3 Thread],持有 Job 的一条完整 pipeline;剩下 5 个 Slot 内分别运行着 2 个 SubTask[2 Thread],数据最终通过网络传递给 Sink 完成数据处理。
三、Flink 异步 IO
流式计算中,常常需要与外部系统进行交互,而往往一次连接中你那个获取连接等待通信的耗时会占比较高。下图是两种方式对比示例:
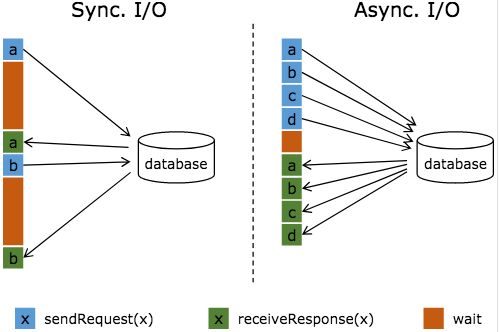
图中棕色的长条表示等待时间,可以发现网络等待时间极大地阻碍了吞吐和延迟。为了解决同步访问的问题,异步模式可以并发地处理多个请求和回复。也就是说,你可以连续地向数据库发送用户 a、b、c 等的请求,与此同时,哪个请求的回复先返回了就处理哪个回复,从而连续的请求之间不需要阻塞等待,如上图右边所示。这也正是 Async I/O 的实现原理。
四、Checkpoint 优化
Flink 实现了一套强大的 checkpoint 机制,使它在获取高吞吐量性能的同时,也能保证 Exactly Once 级别的快速恢复。
首先提升各节点 checkpoint 的性能考虑的就是存储引擎的执行效率。Flink官方支持的三种 checkpoint state 存储方案中,Memory 仅用于调试级别,无法做故障后的数据恢复。其次还有 Hdfs 与 Rocksdb,当所做 Checkpoint 的数据大小较大时,可以考虑采用 Rocksdb 来作为 checkpoint 的存储以提升效率。
其次的思路是资源设置,我们都知道 checkpoint 机制是在每个 task 上都会进行,那么当总的状态数据大小不变的情况下,如何分配减少单个 task 所分的 checkpoint 数据变成了提升 checkpoint 执行效率的关键。
最后,增量快照。非增量快照下,每次 checkpoint 都包含了作业所有状态数据。而大部分场景下,前后 checkpoint 里,数据发生变更的部分相对很少,所以设置增量 checkpoint,仅会对上次 checkpoint 和本次 checkpoint 之间状态的差异进行存储计算,减少了 checkpoint 的耗时。
总结
Operator Chain 是将多个 Operator 链接在一起放置在一个 Task 中,只针对 Operator。Slot Sharing 是在一个 Slot 中执行多个 Task,针对的是 Operator Chain 之后的 Task。这两种优化都充分利用了计算资源,减少了不必要的开销,提升了 Job 的运行性能。异步IO能解决需要高效访问其他系统的问题,提升任务执行的性能。Checkpoint优化是集群配置上的优化,提升集群本身的处理能力。
参考:
https://www.infoq.cn/article/ZmL7TCcEchvANY-9jG1H
https://blog.icocoro.me/2019/06/10/1906-apache-flink-asyncio/
flink任务性能优化的更多相关文章
- 第一章-Flink介绍-《Fink原理、实战与性能优化》读书笔记
Flink介绍-<Fink原理.实战与性能优化>读书笔记 1.1 Apache Flink是什么? 在当代数据量激增的时代,各种业务场景都有大量的业务数据产生,对于这些不断产生的数据应该如 ...
- Flink State Rescale性能优化
背景 今天我们来聊一聊flink中状态rescale的性能优化.我们知道flink是一个支持带状态计算的引擎,其中的状态分为了operator state和 keyed state两类.简而言之ope ...
- Hadoop YARN:调度性能优化实践(转)
https://tech.meituan.com/2019/08/01/hadoop-yarn-scheduling-performance-optimization-practice.html 文章 ...
- SparkSQL的一些用法建议和Spark的性能优化
1.写在前面 Spark是专为大规模数据处理而设计的快速通用的计算引擎,在计算能力上优于MapReduce,被誉为第二代大数据计算框架引擎.Spark采用的是内存计算方式.Spark的四大核心是Spa ...
- 01.SQLServer性能优化之----强大的文件组----分盘存储
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 文章内容皆自己的理解,如有不足之处欢迎指正~谢谢 前天有学弟问逆天:“逆天,有没有一种方 ...
- 03.SQLServer性能优化之---存储优化系列
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 概 述:http://www.cnblogs.com/dunitian/p/60413 ...
- Web性能优化:What? Why? How?
为什么要提升web性能? Web性能黄金准则:只有10%~20%的最终用户响应时间花在了下载html文档上,其余的80%~90%时间花在了下载页面组件上. web性能对于用户体验有及其重要的影响,根据 ...
- Web性能优化:图片优化
程序员都是懒孩子,想直接看自动优化的点:传送门 我自己的Blog:http://cabbit.me/web-image-optimization/ HTTP Archieve有个统计,图片内容已经占到 ...
- C#中那些[举手之劳]的性能优化
隔了很久没写东西了,主要是最近比较忙,更主要的是最近比较懒...... 其实这篇很早就想写了 工作和生活中经常可以看到一些程序猿,写代码的时候只关注代码的逻辑性,而不考虑运行效率 其实这对大多数程序猿 ...
随机推荐
- jmeter实现文件下载
通过浏览器下载文件时,会提示选择保存路径,但是利用测试工具jmeter请求时,在页面看到请求次数是增加了,而本地没有具体下载下来的文件. 需要在具体的文件下载请求下面,添加后置处理器-bean she ...
- Windows驱动开发-Device结构体
每个驱动程序会创建一个或多个设备对象,每个设备对象都会有一个指针指向下一个设备对象 Device结构体源码 typedef struct DECLSPEC_ALIGN(MEMORY_ALLOCATIO ...
- Linux文件系统层次结构标准FHS
文件系统层次结构标准(英语:Filesystem Hierarchy Standard,FHS)定义了Linux操作系统中的主要目录及目录内容.FHS由Linux基金会维护. 当前版本为3.0版,于2 ...
- prometheus 统计MySQL 自增主键的剩余可用百分比
mysqld_exporter自带的这个功能,下面是我使用的启动参数: nohup ./mysqld_exporter --config.my-cnf="./my.cnf" --w ...
- Python爬虫连载5-Proxy、Cookie解析
一.ProxyHandler处理(代理服务器) 1.使用代理IP,是爬虫的常用手段 2.获取代理服务器的地址: www.xicidaili.com www.goubanjia.com 3.代理用来隐藏 ...
- iterm2常用快捷键
标签 新建标签: command + t 关闭标签: command + w 切换标签: command + 数字 command + 左右方向键 切换全屏: command + enter 查找: ...
- 一 CRM 注册功能实现
前端:登陆页面按钮跳转到注册页面 dao: 配置连接池 配置session工厂,Hibernate核心配置,映射 配置UserDao,注入session工厂 UserDao:继承HibernateD ...
- 获取QQ群中的所有群友QQ
package com.jm.mail.tools; import java.io.BufferedReader; import java.io.IOException; import java.io ...
- zabbix proxy配置实战案例
zabbix proxy配置实战案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.zabbix proxy概述 上一篇博客我们分享了zabbix agent有两种工作模式,即 ...
- java#类的实例化顺序
关于类的实例化,不用弄的那么细致,这里只说单一类,没有其他父类(排除Obejct)的情况.要实例化一个类,需要加载class文件到jvm并且验证通过了是安全的字节码文件. 初始化大致上是按照如下步骤: ...