Django 学习 之ORM聚合查询分组查询与F查询与Q查询
一.聚合查询和分组查询
1.聚合查询aggregate
关于数据表的数据请见上一篇:Django 学习 之ORM多表操作(点我)
aggregate(*args, **kwargs),只对一个组进行聚合
# (1)计算所有图书的平均价格
from django.db.models import Avg, Sum, Count, Max, Min
avg_price = models.Book.objects.all().aggregate(Avg("price"))
print(avg_price)
avg_price = models.Book.objects.all().aggregate(avgprice=Avg("price"))
print(avg_price)
# (2)# 计算所有图书的平均价格、最贵价格和最便宜价格
all_price = models.Book.objects.aggregate(Avg("price"), Max("price"), Min("price"))
print(all_price)
aggregate()是QuerySet 的一个终止子句(也就是返回的不再是一个QuerySet集合的时候),意思是说,它返回一个包含一些键值对的字典。键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。如果你想要为聚合值指定一个名称,可以向聚合子句提供它。
分组查询 :annotate():为QuerySet中每一个对象都生成一个独立的汇总值。
是对分组完之后的结果进行的聚合。
2.分组查询annotate
在分组查询之前需要添加相关数据才能进行接下来的查询操作
需要有那么一组数据:
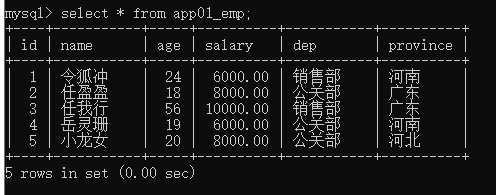
表结构:
class Emp(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
salary = models.DecimalField(max_digits=8, decimal_places=2)
dep = models.CharField(max_length=32)
province = models.CharField(max_length=32)
注意:添加了表结构则,迁移命令和更新命令需要重新运行
python manage.py makemigrations # 把models.py的变更记录记录下来
python manage.py migrate # 把变更记录的操作同步到数据库中
使用mysql添加表数据:
INSERT INTO app01_emp (`id`, `name`, `age`, `salary`, `dep`, `province`) VALUES ('1', '令狐冲', '24', '6000.00', '销售部', '河南');
INSERT INTO app01_emp (`id`, `name`, `age`, `salary`, `dep`, `province`) VALUES ('2', '任盈盈', '18', '8000.00', '公关部', '广东');
INSERT INTO app01_emp (`id`, `name`, `age`, `salary`, `dep`, `province`) VALUES ('3', '任我行', '56', '10000.00', '销售部', '广东');
INSERT INTO app01_emp (`id`, `name`, `age`, `salary`, `dep`, `province`) VALUES ('4', '岳灵珊', '19', '6000.00', '公关部', '河南');
INSERT INTO app01_emp (`id`, `name`, `age`, `salary`, `dep`, `province`) VALUES ('5', '小龙女', '20', '8000.00', '公关部', '河北');
(1)简单的单表分组查询操作
# 查询每一个部门名称以及对应的员工数
# sql语句:select dep,count(*) from app01_emp group by dep;
# ORM:
num = models.Emp.objects.values("dep").annotate(Count("pk"))
print(num)
# 查询每一个部门名称以及对应的员工的平均工资
# sql语句: select dep,avg(salary) from app01_emp group by dep;
# orm:
dep_avg_price = models.Emp.objects.values("dep").annotate(Avg("salary"))
print(dep_avg_price)
(2)多表分组查询操作
多表查询需要添加数据
表结构为:
class Emps(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
salary = models.DecimalField(max_digits=8, decimal_places=2)
dep = models.ForeignKey("Dep", on_delete=models.CASCADE)
province = models.CharField(max_length=32)
class Dep(models.Model):
title = models.CharField(max_length=32)
准备数据:
(1)Dep表:
INSERT INTO app01_dep (`id`, `title`) VALUES ('1', '销售部');
INSERT INTO app01_dep (`id`, `title`) VALUES ('2', '公关部');
(2)Emps表:
INSERT INTO app01_emps (`id`, `name`, `age`, `salary`, `province`, `dep_id`) VALUES ('2', '令狐冲', '24', '8000.00', '河南', '1');
INSERT INTO app01_emps (`id`, `name`, `age`, `salary`, `province`, `dep_id`) VALUES ('3', '任盈盈', '18', '9000.00', '广东', '2');
INSERT INTO app01_emps (`id`, `name`, `age`, `salary`, `province`, `dep_id`) VALUES ('4', '任我行', '57', '10000.00', '广东', '1');
INSERT INTO app01_emps (`id`, `name`, `age`, `salary`, `province`, `dep_id`) VALUES ('5', '岳灵珊', '19', '6000.00', '河南', '2');
INSERT INTO app01_emps (`id`, `name`, `age`, `salary`, `province`, `dep_id`) VALUES ('6', '小龙女', '20', '8000.00', '河北', '2');
注意:以下查询使用Emps表,而不是Emp表
# 查询每一个部门名称以及对应的员工数
# sql语句:select dep_id,count(dep_id) from app01_emps inner join
# app01_dep on app01_emps.dep_id = app01_dep.id group by dep_id;
# ORM:
dep_num = models.Emps.objects.values("dep__id").annotate(Count("dep_id"))
print(dep_num)
# 查询每一个部门名称以及对应的员工的平均工资
# sql语句: select app01_dep.title,avg(salary) from app01_emps
# inner join app01_dep on app01_emps.dep_id = app01_dep.id group by dep_id;
# ORM:
dep_avgsly = models.Emps.objects.values("dep__title").annotate(Avg("salary"))
print(dep_avgsly)
3.查询练习
出版社与书的数据为:
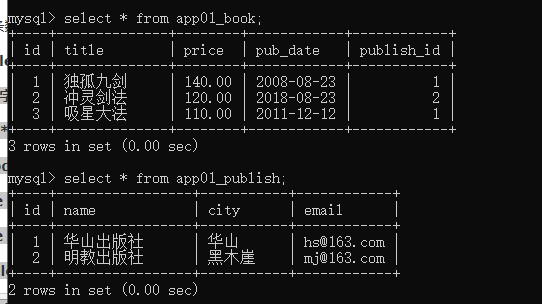
# 练习1:统计每一个出版社名字及最便宜的书的价格
# sql语句: select min(price) from app01_book inner join
# app01_publish on app01_book.publish_id = app01_publish.id group by publish_id;
# ORM:
name_minprice = models.Book.objects.values("publish__name").annotate(Min("price"))
print(name_minprice)
# 练习2:统计每一本书的作者个数
# sql语句: select app01_book.id,count(*) from app01_book inner join
# app01_book_authors on app01_book.id = app01_book_authors.book_id group by app01_book.id;
# ORM:
author_num = models.Book.objects.annotate(num=Count('authors__id')).values("title", "num")
print(author_num)
# 练习3:统计每一本以“冲”开头的书籍的作者个数
# sql语句:select app01_book.id,count(*) from app01_book inner join
# app01_book_authors on app01_book.id = app01_book_authors.book_id inner join
# app01_author on app01_book_authors.author_id = app01_author.id
# where app01_book.title LIKE '冲%' group by app01_book.id ;
# ORM:
author_num = models.Book.objects.filter(title__startswith="冲").annotate(num=Count('authors__id')).values("title", "num")
print(author_num)
# 练习4:统计不止一个作者的图书名称
# sql语句:select app01_book.title from app01_book inner join
# app01_book_authors on app01_book.id = app01_book_authors.book_id inner join
# app01_author on app01_book_authors.author_id = app01_author.id
# group by app01_book.id having count(app01_book.title)>1 ;
# ORM:
author_name = models.Book.objects.annotate(num=Count('authors__name')).filter(num__gt=1).values("title")
print(author_name)
# 练习5:根据一本图书作者数量的多少对查询集QuerySet进行排序
# sql语句:select app01_book.id,count(*) as num from app01_book inner join
# app01_book_authors on app01_book.id = app01_book_authors.book_id inner join
# app01_author on app01_book_authors.author_id = app01_author.id
# group by app01_book.id order by num ;
# ORM:
ornum = models.Book.objects.annotate(num=Count('authors__id')).order_by("num").values("title", "num")
print(ornum)
# 练习6:查询各个作者出的书的总价格
# sql语句: select app01_author.name,sum(app01_book.price) from app01_book inner join
# app01_book_authors on app01_book.id = app01_book_authors.book_id inner join
# app01_author on app01_book_authors.author_id = app01_author.id group by app01_author.name ;
# ORM:
sum_price = models.Author.objects.annotate(num=Sum('book__price')).values("name", "num")
print(sum_price)
return HttpResponse("查询成功")
二.F查询与Q查询
1.F查询
在上面所有的例子中,我们构造的过滤器都只是将字段值与某个常量做比较。如果我们要对两个字段的值做比较,那该怎么做呢?
Django 提供 F() 来做这样的比较。F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值。
# 查询工资大于年龄的人
from django.db.models import F, Q
per = models.Emp.objects.filter(salary__gt=F('age'))
print(per)
# 查询工资小于30倍年龄值的人
per = models.Emp.objects.filter(salary__lt=F("age") * 300)
print(per)
修改操作也可以使用F函数,比如将每一本书的价格提高100元
models.Book.objects.update(price=F('price') + 100)
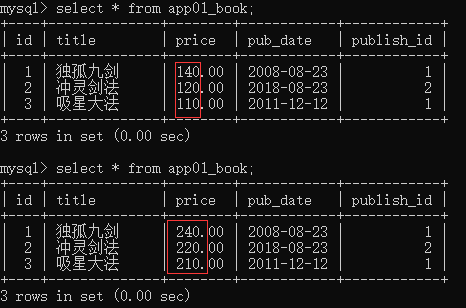
Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作。
2.Q查询
filter() 等方法中的关键字参数查询都是一起进行“AND” 的。 如果你需要执行更复杂的查询(例如OR 语句),你可以使用Q 对象。
from django.db.models import Q
Q 对象可以使用 & 、 | 和 ~(与 或 非)操作符组合起来。当一个操作符在两个Q 对象上使用时,它产生一个新的Q 对象
。
# 查询价格大于300或者名称以九开头的书籍
# sql语句:select title from app01_book where price > 200 or title like "独";
# ORM:
book_title = models.Book.objects.filter(Q(price__gt=200) | Q(title__startswith="独"))
print(book_title)
# 查询价格大于220或者不是2011年12月份的书籍
book_obj = models.Book.objects.filter(Q(price__gt=220) | ~Q(Q(pub_date__year=2011)&Q(pub_date__month=12)))
print(book_obj)
注意:
查询函数可以混合使用Q 对象和关键字参数。所有提供给查询函数的参数(关键字参数或Q 对象)都将"AND”在一起。但是,如果出现Q 对象,它必须位于所有关键字参数的前面。
Django 学习 之ORM聚合查询分组查询与F查询与Q查询的更多相关文章
- Django学习之ORM操作
一.一般操作 二.必知必会13条 返回QuerySet对象的方法有 特殊的QuerySet 返回具体对象的 返回布尔值的方法有 返回数字的方法 三.单表查询之神奇的双下划线 四.ForeignKey操 ...
- Django学习手册 - ORM 数据创建/表操作 汇总
ORM 查询的数据类型: QuerySet与惰性机制(可以看作是一个列表) 所谓惰性机制:表名.objects.all()或者.filter()等都只是返回了一个QuerySet(查询结果集对象),它 ...
- Django 学习 之ORM多表操作
一.创建模型 1.模型关系整理 创建一对一的关系:OneToOne("要绑定关系的表名") 创建一对多的关系:ForeignKey("要绑定关系的表名") 创建 ...
- django学习-15.ORM查询方法汇总
1.前言 django的ORM框架提供的查询数据库表数据的方法很多,不同的方法返回的结果也不太一样,不同方法都有各自对应的使用场景. 主要常用的查询方法个数是13个,按照特点分为这4类: 方法返回值是 ...
- Django学习之ORM练习题
一.表关系 创建表关系,并创建约束 班级表:class 学生表: student cid caption grade_id sid sname gender class_id 1 一年一班 1 1 乔 ...
- Django学习手册 - ORM 多对多表
定义表结构: class Host(models.Model): hostname = models.CharField(max_length=32) port = models.IntegerFie ...
- Django 学习 之ORM简介与单表操作
一.ORM简介 1.ORM概念 对象关系映射(Object Relational Mapping,简称ORM). 简单的说,ORM是通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到 ...
- Django学习手册 - ORM 外键
Django 外键创建 关键语法: models.ForeignKey("UserGroup",to_field="gid",default=1,on_dele ...
- Django学习手册 - ORM数据类型
DOM 字段/参数 配置格式: Module.字段(参数) 常用的字段归纳: 数字 models.AutoField() 自增列(int),必须设置为主键 models.IntegerField() ...
随机推荐
- Dataguard单机—>单机
本演示案例所用环境: primary Standby OS Hostname CHINA-DB1 CHINA-DB2 OS Version SUSE Linux Enterprise Server 1 ...
- 【visio】 设计
1."设计" 包含了 页面.布局和主题相关设置 2."页面设置" 包含:打印.绘制区域.打印区域.页面缩放.页属性以及替换文字. 替换文字 放在页面设置里,这个 ...
- python-turtle-画雪花-2种方法及效果的详解
1.方法一: 代码: #python3.8 #xuguojun #2020.1.30 #导出模块 import turtle as t import random as r #定义画雪 def dra ...
- 吴裕雄 python 人工智能——基于Mask_RCNN目标检测(2)
import os import sys import itertools import math import logging import json import re import random ...
- 科技股 - 5G、芯片、半导体 细分龙头
5G.芯片.半导体 细分龙头 来源:头条-南山话投资 1.射频芯片:卓胜微 2.存储芯片设计:兆易创新 3.GPU:景嘉微 4.模拟电路芯片:圣邦股份 5.半导体分立器件:扬杰科技 6.晶圆代工:中芯 ...
- 微信js sdk分享开发摘记java版
绑定域名和引入js的就不说了 废话不说直接上代码 public void share(HttpServletRequest request) throws Exception { StringBuff ...
- Java面向对象编程 -6.3
foreach迭代输出 对于数组而言,一般都会使用for循环进行输出,但是在使用传统for循环的时候往往采用下标的形式进行数组元素的访问. 但是在jdk1.5之后为了减轻下标对数组的影响(如果数组下标 ...
- cascadia-code 程序员友好字体
下载地址:https://github.com/microsoft/cascadia-code/releases/download/v1911.21/Cascadia.ttf 下载后右键点击下载的文件 ...
- 6.Python字符串
#header { display: none !important; } } #header-spacer { width: 100%; visibility: hidden; } @media p ...
- java 责任链模式的三种实现
责任链模式 责任链模式的定义:使多个对象都有机会处理请求,从而避免请求的发送者和接受者之间的耦合关系, 将这个对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理他为止.这里就不再过多的介绍什么 ...