NLP的比赛和数据集
整理了NLP领域的比赛、数据集、模型
| 比赛 | 网站 | 主办方(作者) |
|---|---|---|
| decaNLP | http://decanlp.com/ | Salesforce |
| CLUE | https://github.com/CLUEbenchmark/CLUE | 中文任务基准 |
| GLUE | https://gluebenchmark.com/tasks | |
| BioBERT | https://github.com/dmis-lab/biobert | 生物医学领域的NLP任务 |
| ERNIE | https://github.com/PaddlePaddle/ERNIE | 百度飞桨 |
| ALBERT |
decaNLP
自然语言十项全能多任务挑战
Natural Language Decathlon (decaNLP) 是一个新的基准,要求单独的系统能够完成10项独立的自然语言任务。
- 问答 Stanford Question Answering Dataset (SQuAD 1.1)
- 机器翻译 International Workshop on Spoken Language Translation (IWSLT),
- 自动摘要 CNN/DailyMail (CNN/DM) corpus.
- 自然语言推理 Multi-Genre Natural Language Inference Corpus (MNLI).
- 情感分析 Stanford Sentiment Treebank (SST),
- 语义标签标注 QA-SRL 1.0.
- 关系抽取 QA-ZRE,
- 面向全域的对话 Wizard of Oz (WOZ)
- 语义解析 WikiSQL 【Seq2SQL,https://github.com/salesforce/WikiSQL】
- 常识推理 Modified Winograd Schema Challenge, MWSC)
评测-GLUE
CoLA、 SST-2、 MRPC、 STS-B、 QQP、 MNLI-m、 QNLI、 RTE
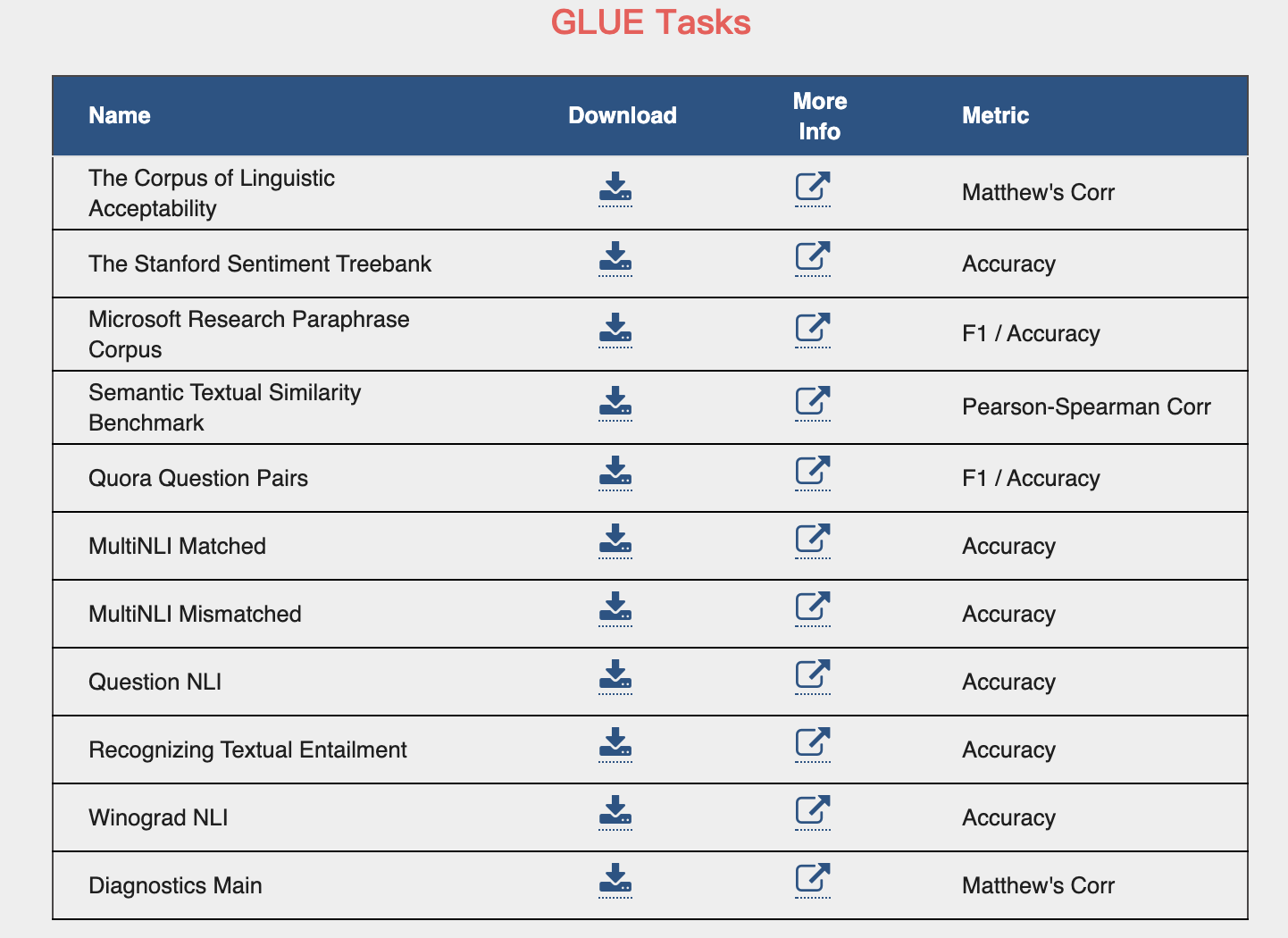
评测-CLUE
中文任务基准评测CLUE
AFQMC:蚂蚁语义相似度(Acc);
TNEWS:文本分类(Acc);
IFLYTEK:长文本分类(Acc);
CMNLI: 自然语言推理中文版;
COPA: 因果推断;
WSC: Winograd模式挑战中文版;
CSL: 中国科学文献数据集;
模型-BioBERT
https://github.com/dmis-lab/biobert
- NER
命名实体识别 - RE
关系抽取 - QA
问答
模型-ERNIE
https://github.com/PaddlePaddle/ERNIE/blob/develop/README.zh.md
- 自然语言推断 XNLI
- 阅读理解 DuReader、CMRC2018、DRCD
- 命名实体识别 MSRA-NER(SIGHAN2006)
- 情感分析 ChnSentiCorp
- 问答任务 NLPCC2016-DBQA
- 语义相似度 LCQMC、BQ Corpus
模型-ALBERT
模型-TinyBERT
NLP的比赛和数据集的更多相关文章
- NLP+VS︱深度学习数据集标注工具、方法摘录,欢迎补充~~
~~因为不太会使用opencv.matlab工具,所以在找一些比较简单的工具. . . 一.NLP标注工具BRAT BRAT是一个基于web的文本标注工具,主要用于对文本的结构化标注,用BRAT生成的 ...
- 如何在nlp问题中定义自己的数据集
我之前大致写了一篇在pytorch中如何自己定义数据集合,在这里如何自定义数据集 不过这个例子使用的是image,也就是图像.如果我们用到的是文本呢,处理的是NLP问题呢? 在解决这个问题的时候,我在 ...
- 自然语言处理(NLP)入门学习资源清单
Melanie Tosik目前就职于旅游搜索公司WayBlazer,她的工作内容是通过自然语言请求来生产个性化旅游推荐路线.回顾她的学习历程,她为期望入门自然语言处理的初学者列出了一份学习资源清单. ...
- 微软名人数据集 ms_celeb_1m 处理(MsCelebV1-Faces-Aligned.tsv)python脚本
本文主要介绍了如何对MsCelebV1-Faces-Aligned.tsv文件进行提取 原创by南山南北秋悲 欢迎引用!请注明原地址 http://www.cnblogs.com/hwd9654/p/ ...
- 自然语言处理(NLP)
苹果语音助手Siri的工作流程: 听 懂 思考 组织语言 回答 这其中每一步骤涉及的流程为: 语音识别 自然语言处理 - 语义分析 逻辑分析 - 结合业务场景与上下文 自然语言处理 - 分析结果生成自 ...
- 卷积神经网络(CNN)在句子建模上的应用
之前的博文已经介绍了CNN的基本原理,本文将大概总结一下最近CNN在NLP中的句子建模(或者句子表示)方面的应用情况,主要阅读了以下的文献: Kim Y. Convolutional neural n ...
- 转:netflix推荐系统竞赛
原文链接:Netflix recommendations: beyond the 5 stars (Part 1), (Part 2) 原文作者:Xavier Amatriain and Justin ...
- 基于hadoop的图书推荐
根据在炼数成金上的学习,将部分代码总结一下在需要的时候可以多加温习.首先根据原理作简要分析.一般推荐系统使用的协同过滤推荐模型:分别是基于ItemCF的推荐模型或者是基于UserCF的推荐模型:首先分 ...
- ms_celeb_1m数据提取(MsCelebV1-Faces-Aligned.tsv)python脚本
本文主要介绍了如何对MsCelebV1-Faces-Aligned.tsv文件进行提取 原创by南山南北秋悲 欢迎引用!请注明原地址 http://www.cnblogs.com/hwd9654/p/ ...
随机推荐
- 极客从CPU选择开始-CPU详解
先来看看CPU天梯图(来自(快科技CPU性能天梯图)[https://www.mydrivers.com/zhuanti/tianti/cpu/index.html]) Intel VS AMD (P ...
- NET com组件注册
1.签名 右击项目->属性->[签名]标签, 选中[为程序集签名]–>[选择强名称密钥文件]–>[新建],输入你的密钥名称,去掉[使用密码保护密钥文件] 最重要的签名,并且注册 ...
- 一篇文章带你了解JavaScript中的变量,作用域和内存问题
1 在JavaScript中的变量分别区分为两种: 一种为基本类型值,一种为应用类型值. 基本类型值指的是简单的数据段 引用类型值为可能由多个值组成的对象 引用类型的值是保存在内存中的对象,JavaS ...
- Springmvc-crud-06(路径忘记加上“/”错误)
错误: 原因:自己马虎忘记加" / ",罚继续写代码┭┮﹏┭┮ 前端代码: <h1>添加功能</h1> <form action="te ...
- IE6下的png不透明问题
前几天刚做完一个小需求,但是在兼容ie方面用了比较久的时间,主要是切面那边用的背景图都是png格式的,而经过查找知道,ie6对png图片透明部分渲染效果是不透明的,我看到的是淡淡的绿色,简单的处理方式 ...
- VS Code的git配置
最近打算使用VS Code作为python的编辑器,这里记录一下VS Code中git的配置方法 因为vscode中git只是使用本地的git,所以本地必须先安装git才行. 1.git的安装 git ...
- codeforces-1271A - Suits
A. Suits A new delivery of clothing has arrived today to the clothing store. This delivery consist ...
- jq鼠标移入移除事件
mouseover与mouseenter 不论鼠标指针穿过被选元素或其子元素,都会触发 mouseover 事件.只有在鼠标指针穿过被选元素时,才会触发 mouseenter 事件. mouseout ...
- IDEA 下的 github 创建提交与修改
本章假定你已经安装了 git 客户端,本文仅仅使用与 Mac 环境下,未在 Window下实验,但 IDEA 在 Window 和 Mac 下软件的使用方法是一致的. 1 配置账号 IDEA 需要配置 ...
- Java 数据脱敏 工具类
一.项目导入Apache的commons的Jar包. Jar包Maven下载地址:https://mvnrepository.com/artifact/org.apache.commons/commo ...