恕我直言你可能真的不会java第11篇-Stream API终端操作
一、Java Stream管道数据处理操作
在本号之前写过的文章中,曾经给大家介绍过 Java Stream管道流是用于简化集合类元素处理的java API。在使用的过程中分为三个阶段。在开始本文之前,我觉得仍然需要给一些新朋友介绍一下这三个阶段,如图:
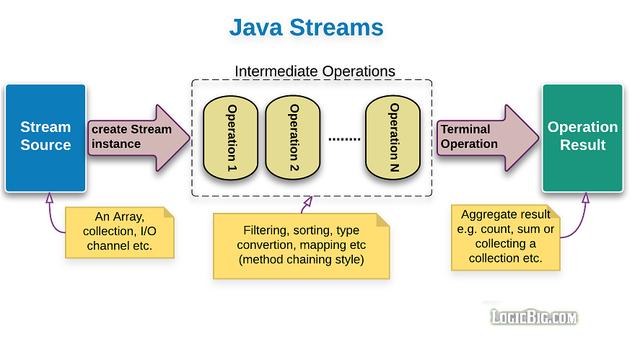
- 第一阶段(图中蓝色):将集合、数组、或行文本文件转换为java Stream管道流
- 第二阶段(图中虚线部分):管道流式数据处理操作,处理管道中的每一个元素。上一个管道中的输出元素作为下一个管道的输入元素。
- 第三阶段(图中绿色):管道流结果处理操作,也就是本文的将介绍的核心内容。
在开始学习之前,仍然有必要回顾一下我们之前给大家讲过的一个例子:
List<String> nameStrs = Arrays.asList("Monkey", "Lion", "Giraffe","Lemur");
List<String> list = nameStrs.stream()
.filter(s -> s.startsWith("L"))
.map(String::toUpperCase)
.sorted()
.collect(toList());
System.out.println(list);
- 首先使用stream()方法将字符串List转换为管道流Stream
- 然后进行管道数据处理操作,先用fliter函数过滤所有大写L开头的字符串,然后将管道中的字符串转换为大写字母toUpperCase,然后调用sorted方法排序。这些API的用法在本号之前的文章有介绍过。其中还使用到了lambda表达式和函数引用。
- 最后使用collect函数进行结果处理,将java Stream管道流转换为List。最终list的输出结果是:
[LEMUR, LION]
如果你不使用java Stream管道流的话,想一想你需要多少行代码完成上面的功能呢?回到正题,这篇文章就是要给大家介绍第三阶段:对管道流处理结果都可以做哪些操作呢?下面开始吧!
二、ForEach和ForEachOrdered
如果我们只是希望将Stream管道流的处理结果打印出来,而不是进行类型转换,我们就可以使用forEach()方法或forEachOrdered()方法。
Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.parallel()
.forEach(System.out::println);
Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.parallel()
.forEachOrdered(System.out::println);
- parallel()函数表示对管道中的元素进行并行处理,而不是串行处理,这样处理速度更快。但是这样就有可能导致管道流中后面的元素先处理,前面的元素后处理,也就是元素的顺序无法保证
- forEachOrdered从名字上看就可以理解,虽然在数据处理顺序上可能无法保障,但是forEachOrdered方法可以在元素输出的顺序上保证与元素进入管道流的顺序一致。也就是下面的样子(forEach方法则无法保证这个顺序):
Monkey
Lion
Giraffe
Lemur
Lion
三、元素的收集collect
java Stream 最常见的用法就是:一将集合类转换成管道流,二对管道流数据处理,三将管道流处理结果在转换成集合类。那么collect()方法就为我们提供了这样的功能:将管道流处理结果在转换成集合类。
3.1.收集为Set
通过Collectors.toSet()方法收集Stream的处理结果,将所有元素收集到Set集合中。
Set<String> collectToSet = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur", "Lion"
)
.collect(Collectors.toSet());
//最终collectToSet 中的元素是:[Monkey, Lion, Giraffe, Lemur],注意Set会去重。
3.2.收集到List
同样,可以将元素收集到List使用toList()收集器中。
List<String> collectToList = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur", "Lion"
).collect(Collectors.toList());
// 最终collectToList中的元素是: [Monkey, Lion, Giraffe, Lemur, Lion]
3.3.通用的收集方式
上面为大家介绍的元素收集方式,都是专用的。比如使用Collectors.toSet()收集为Set类型集合;使用Collectors.toList()收集为List类型集合。那么,有没有一种比较通用的数据元素收集方式,将数据收集为任意的Collection接口子类型。
所以,这里就像大家介绍一种通用的元素收集方式,你可以将数据元素收集到任意的Collection类型:即向所需Collection类型提供构造函数的方式。
LinkedList<String> collectToCollection = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur", "Lion"
).collect(Collectors.toCollection(LinkedList::new));
//最终collectToCollection中的元素是: [Monkey, Lion, Giraffe, Lemur, Lion]
注意:代码中使用了LinkedList::new,实际是调用LinkedList的构造函数,将元素收集到Linked List。当然你还可以使用诸如LinkedHashSet::new和PriorityQueue::new将数据元素收集为其他的集合类型,这样就比较通用了。
3.4.收集到Array
通过toArray(String[]::new)方法收集Stream的处理结果,将所有元素收集到字符串数组中。
String[] toArray = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur", "Lion"
) .toArray(String[]::new);
//最终toArray字符串数组中的元素是: [Monkey, Lion, Giraffe, Lemur, Lion]
3.5.收集到Map
使用Collectors.toMap()方法将数据元素收集到Map里面,但是出现一个问题:那就是管道中的元素是作为key,还是作为value。我们用到了一个Function.identity()方法,该方法很简单就是返回一个“ t -> t ”(输入就是输出的lambda表达式)。另外使用管道流处理函数distinct()来确保Map键值的唯一性。
Map<String, Integer> toMap = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur", "Lion"
)
.distinct()
.collect(Collectors.toMap(
Function.identity(), //元素输入就是输出,作为key
s -> (int) s.chars().distinct().count()// 输入元素的不同的字母个数,作为value
));
// 最终toMap的结果是: {Monkey=6, Lion=4, Lemur=5, Giraffe=6}
3.6.分组收集groupingBy
Collectors.groupingBy用来实现元素的分组收集,下面的代码演示如何根据首字母将不同的数据元素收集到不同的List,并封装为Map。
Map<Character, List<String>> groupingByList = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur", "Lion"
)
.collect(Collectors.groupingBy(
s -> s.charAt(0) , //根据元素首字母分组,相同的在一组
// counting() // 加上这一行代码可以实现分组统计
));
// 最终groupingByList内的元素: {G=[Giraffe], L=[Lion, Lemur, Lion], M=[Monkey]}
//如果加上counting() ,结果是: {G=1, L=3, M=1}
这是该过程的说明:groupingBy第一个参数作为分组条件,第二个参数是子收集器。

四、其他常用方法
boolean containsTwo = IntStream.of(1, 2, 3).anyMatch(i -> i == 2);
// 判断管道中是否包含2,结果是: true
long nrOfAnimals = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur"
).count();
// 管道中元素数据总计结果nrOfAnimals: 4
int sum = IntStream.of(1, 2, 3).sum();
// 管道中元素数据累加结果sum: 6
OptionalDouble average = IntStream.of(1, 2, 3).average();
//管道中元素数据平均值average: OptionalDouble[2.0]
int max = IntStream.of(1, 2, 3).max().orElse(0);
//管道中元素数据最大值max: 3
IntSummaryStatistics statistics = IntStream.of(1, 2, 3).summaryStatistics();
// 全面的统计结果statistics: IntSummaryStatistics{count=3, sum=6, min=1, average=2.000000, max=3}
欢迎关注我的博客,里面有很多精品合集
- 本文转载注明出处(必须带连接,不能只转文字):字母哥博客。
觉得对您有帮助的话,帮我点赞、分享!您的支持是我不竭的创作动力! 。另外,笔者最近一段时间输出了如下的精品内容,期待您的关注。
- 《手摸手教你学Spring Boot2.0》
- 《Spring Security-JWT-OAuth2一本通》
- 《实战前后端分离RBAC权限管理系统》
- 《实战SpringCloud微服务从青铜到王者》
- 《VUE深入浅出系列》
恕我直言你可能真的不会java第11篇-Stream API终端操作的更多相关文章
- 恕我直言你可能真的不会java第9篇-Stream元素的匹配与查找
在我们对数组或者集合类进行操作的时候,经常会遇到这样的需求,比如: 是否包含某一个"匹配规则"的元素 是否所有的元素都符合某一个"匹配规则" 是否所有元素都不符 ...
- 恕我直言你可能真的不会java第1篇:lambda表达式会用了么?
本文配套教学视频:B站观看地址 在本号之前写过的一些文章中,笔者使用了lambda表达式语法,一些读者反映说代码看不懂.本以为java 13都已经出了,java 8中最重要特性lambda表达式大家应 ...
- 恕我直言你可能真的不会java第2篇:Java Stream API?
一.什么是Java Stream API? Java Stream函数式编程接口最初是在Java 8中引入的,并且与lambda一起成为Java开发的里程碑式的功能特性,它极大的方便了开放人员处理集合 ...
- 恕我直言你可能真的不会java第12篇-如何使用Stream API对Map类型元素排序
在这篇文章中,您将学习如何使用Java对Map进行排序.前几日有位朋友面试遇到了这个问题,看似很简单的问题,但是如果不仔细研究一下也是很容易让人懵圈的面试题.所以我决定写这样一篇文章.在Java中,有 ...
- 恕我直言你可能真的不会java第6篇:Stream性能差?不要人云亦云
一.粉丝的反馈 问:stream比for循环慢5倍,用这个是为了啥? 答:互联网是一个新闻泛滥的时代,三人成虎,以假乱真的事情时候发生.作为一个技术开发者,要自己去动手去做,不要人云亦云. 的确,这位 ...
- 恕我直言你可能真的不会java第4篇:Stream管道流Map操作
一.回顾Stream管道流map的基础用法 最简单的需求:将集合中的每一个字符串,全部转换成大写! List<String> alpha = Arrays.asList("Mon ...
- 恕我直言你可能真的不会java第7篇:像使用SQL一样排序集合
在开始之前,我先卖个关子提一个问题:我们现在有一个Employee员工类. @Data @AllArgsConstructor public class Employee { private Inte ...
- 恕我直言你可能真的不会java第8篇-函数式接口
一.函数式接口是什么? 所谓的函数式接口,实际上就是接口里面只能有一个抽象方法的接口.我们上一节用到的Comparator接口就是一个典型的函数式接口,它只有一个抽象方法compare. 只有一个抽象 ...
- 恕我直言你可能真的不会java第3篇:Stream的Filter与谓词逻辑
一.基础代码准备 建立一个实体类,该实体类有五个属性.下面的代码使用了lombok的注解Data.AllArgsConstructor,这样我们就不用写get.set方法和全参构造函数了.lombok ...
随机推荐
- Java实现 LeetCode 347 前 K 个高频元素
347. 前 K 个高频元素 给定一个非空的整数数组,返回其中出现频率前 k 高的元素. 示例 1: 输入: nums = [1,1,1,2,2,3], k = 2 输出: [1,2] 示例 2: 输 ...
- Java实现 蓝桥杯VIP 算法提高 解二元一次方程组
算法提高 解二元一次方程组 时间限制:1.0s 内存限制:256.0MB 问题描述 给定一个二元一次方程组,形如: a * x + b * y = c; d * x + e * y = f; x,y代 ...
- Java实现 洛谷 P1028 数的计算
import java.util.Scanner; import java.util.Arrays; public class Main { private static Scanner cin; p ...
- python IDE pycharm的安装与使用
Python开发最牛逼的IDE——pycharm (其实其它的工具,例如eclipse也可以写,只不过比较麻烦,需要安装很多的插件,所以说pycharm是最牛逼的) pycharm,下载专业版的,不要 ...
- JS中的各类运算符
2020-04-15 JS中的各类运算符 // 假设有如下代码,那么a(10)的返回结果是?( ) function a(a) { a^=(1<<4)-1; return a; } // ...
- 修改MSSQL的端口地址_TcpPort_数据库安装工具_连载_2
修改MSSQL的端口地址_TcpPort,可在程序中调用,从而修改TcpPort Use master Go ------------------------------ --1)在注册表中查询 Pi ...
- TensorFlow从0到1之XLA加速线性代数编译器(9)
加速线性代数器(Accelerated linear algebra,XLA)是线性代数领域的专用编译器.根据 https://www.tensorflow.org/performance/xla/, ...
- 030.Kubernetes核心组件-Scheduler
一 Scheduler原理 1.1 原理解析 Kubernetes Scheduler是负责Pod调度的重要功能模块,Kubernetes Scheduler在整个系统中承担了"承上启下&q ...
- The following packages will be SUPERCEDED by a higher-priority channel是什么意思?
参考资料: https://stackoverflow.com/questions/42015732/the-following-packages-will-be-superceded-by-a-hi ...
- cb38a_c++_STL_算法_transform
cb38a_c++_STL_算法_transformtransform()算法有两种形式:transform(b1,e1,b2,op);//b1(源区间)的数据通过op函数处理,存放在b2(目标区间) ...