【转载】Spark SQL 1.3.0 DataFrame介绍、使用
http://www.aboutyun.com/forum.php?mod=viewthread&tid=12358&page=1
1.DataFrame是什么?
2.如何创建DataFrame?
3.如何将普通RDD转变为DataFrame?
4.如何使用DataFrame?
5.在1.3.0中,提供了哪些完整的数据写入支持API?

DataFrame

- # 从Hive中的users表构造DataFrame
- users = sqlContext.table("users")
- # 加载S3上的JSON文件
- logs = sqlContext.load("s3n://path/to/data.json", "json")
- # 加载HDFS上的Parquet文件
- clicks = sqlContext.load("hdfs://path/to/data.parquet", "parquet")
- # 通过JDBC访问MySQL
- comments = sqlContext.jdbc("jdbc:mysql://localhost/comments", "user")
- # 将普通RDD转变为DataFrame
- rdd = sparkContext.textFile("article.txt") \
- .flatMap(lambda line: line.split()) \
- .map(lambda word: (word, 1)) \
- .reduceByKey(lambda a, b: a + b) \
- wordCounts = sqlContext.createDataFrame(rdd, ["word", "count"])
- # 将本地数据容器转变为DataFrame
- data = [("Alice", 21), ("Bob", 24)]
- people = sqlContext.createDataFrame(data, ["name", "age"])
- # 将Pandas DataFrame转变为Spark DataFrame(Python API特有功能)
- sparkDF = sqlContext.createDataFrame(pandasDF)
- # 创建一个只包含"年轻"用户的DataFrame
- young = users.filter(users.age < 21)
- # 也可以使用Pandas风格的语法
- young = users[users.age < 21]
- # 将所有人的年龄加1
- young.select(young.name, young.age + 1)
- # 统计年轻用户中各性别人数
- young.groupBy("gender").count()
- # 将所有年轻用户与另一个名为logs的DataFrame联接起来
- young.join(logs, logs.userId == users.userId, "left_outer")
- young.registerTempTable("young")
- sqlContext.sql("SELECT count(*) FROM young")
- # 追加至HDFS上的Parquet文件
- young.save(path="hdfs://path/to/data.parquet",
- source="parquet",
- mode="append")
- # 覆写S3上的JSON文件
- young.save(path="s3n://path/to/data.json",
- source="json",
- mode="append")
- # 保存为SQL表
- young.saveAsTable(tableName="young", source="parquet" mode="overwrite")
- # 转换为Pandas DataFrame(Python API特有功能)
- pandasDF = young.toPandas()
- # 以表格形式打印输出
- young.show()
幕后英雄:Spark SQL查询优化器与代码生成
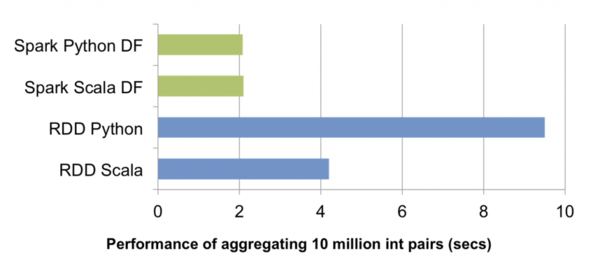
外部数据源API增强

数据写入支持
- CREATE [TEMPORARY] TABLE [IF NOT EXISTS]
- <table-name> [(col-name data-type [, ...)]
- USING <source> [OPTIONS ...]
- [AS <select-query>]
统一的load/save API
- rdd.saveAsParquetFile(...)
- rdd.saveAsTextFile(...)
- rdd.toJSON.saveAsTextFile(...)
- rdd.saveAsTable(...)
- ....
Parquet数据源增强
- // 创建两个简单的DataFrame,将之存入两个独立的分区目录
- val df1 = (1 to 5).map(i => (i, i * 2)).toDF("single", "double")
- df1.save("data/test_table/key=1", "parquet", SaveMode.Append)
- val df2 = (6 to 10).map(i => (i, i * 2)).toDF("single", "double")
- df2.save("data/test_table/key=2", "parquet", SaveMode.Append)
- // 在另一个DataFrame中引入一个新的列,并存入另一个分区目录
- val df3 = (11 to 15).map(i => (i, i * 3)).toDF("single", "triple")
- df3.save("data/test_table/key=3", "parquet", SaveMode.Append)
- // 一次性读入整个分区表的数据
- val df4 = sqlContext.load("data/test_table", "parquet")
- // 按分区进行查询,并展示结果
- val df5 = df4.filter($"key" >= 2) df5.show()
- 6 12 null 2
- 7 14 null 2
- 8 16 null 2
- 9 18 null 2
- 10 20 null 2
- 11 null 33 3
- 12 null 36 3
- 13 null 39 3
- 14 null 42 3
- 15 null 45 3
小结
【转载】Spark SQL 1.3.0 DataFrame介绍、使用的更多相关文章
- 平易近人、兼容并蓄——Spark SQL 1.3.0概览
自2013年3月面世以来,Spark SQL已经成为除Spark Core以外最大的Spark组件.除了接过Shark的接力棒,继续为Spark用户提供高性能的SQL on Hadoop解决方案之外, ...
- Spark SQL,如何将 DataFrame 转为 json 格式
今天主要介绍一下如何将 Spark dataframe 的数据转成 json 数据.用到的是 scala 提供的 json 处理的 api. 用过 Spark SQL 应该知道,Spark dataf ...
- Spark SQL概念学习系列之DataFrame与RDD的区别
不多说,直接上干货! DataFrame的推出,让Spark具备了处理大规模结构化数据的能力,不仅比原有的RDD转化方式更加简单易用,而且获得了更高的计算性能.Spark能够轻松实现从MySQL到Da ...
- Spark SQL 之 RDD、DataFrame 和 Dataset 如何选择
引言 Apache Spark 2.2 以及以上版本提供的三种 API - RDD.DataFrame 和 Dataset,它们都可以实现很多相同的数据处理,它们之间的性能差异如何,在什么情况下该选用 ...
- Spark SQL初始化和创建DataFrame的几种方式
一.前述 1.SparkSQL介绍 Hive是Shark的前身,Shark是SparkSQL的前身,SparkSQL产生的根本原因是其完全脱离了Hive的限制. SparkSQL支持查询原 ...
- spark SQL、RDD、Dataframe总结
- Spark学习之路(八)—— Spark SQL 之 DataFrame和Dataset
一.Spark SQL简介 Spark SQL是Spark中的一个子模块,主要用于操作结构化数据.它具有以下特点: 能够将SQL查询与Spark程序无缝混合,允许您使用SQL或DataFrame AP ...
- Spark 系列(八)—— Spark SQL 之 DataFrame 和 Dataset
一.Spark SQL简介 Spark SQL 是 Spark 中的一个子模块,主要用于操作结构化数据.它具有以下特点: 能够将 SQL 查询与 Spark 程序无缝混合,允许您使用 SQL 或 Da ...
- Spark SQL怎么创建编程创建DataFrame
创建DataFrame在Spark SQL中,开发者可以非常便捷地将各种内.外部的单机.分布式数据转换为DataFrame.以下Python示例代码充分体现了Spark SQL 1.3.0中DataF ...
随机推荐
- Linux下移植pjsip,使用QT开发
1.移植pjsip env:fedora14 arm-linuc-gcc:gcc version 4.5.1 (ctng-1.8.1-FA) #./configure \ CC=arm-linux-g ...
- 《精通ASP.NET MVC5》第2章 第一个MVC应用程序
控制器 public class NewHomeController : Controller { // GET: /NewHome/ public ...
- 关于三目运算符与if语句的效率与洛谷P2704题解
题目描述 司令部的将军们打算在N*M的网格地图上部署他们的炮兵部队.一个N*M的地图由N行M列组成,地图的每一格可能是山地(用“H” 表示),也可能是平原(用“P”表示),如下图.在每一格平原地形上最 ...
- 被mysql中的wait_timeout坑了
今天被mysql里的wait_timeout坑了 网上能搜到很多关于mysql中的wait_timeout相关的文章,但是大多数只是说明了他的作用,而且都说这个参数要配合那个inter ...
- 电脑右键新建文本文档(txt)消失的解决办法
其实只需要一个注册表就可以了 下载地址http://pan.baidu.com/s/1hr7r0fM 拿走不谢! 注册表的内容是这样的,你也可以新建一个文件把后缀名改成.reg然后把下面的内容copy ...
- 数据返回[数据库基础]——图解JOIN
废话就不多说了,开始... 一.提要 JOIN对于接触过数据库的人,这个词都不生疏,而且很多人很清楚各种JOIN,还有很多人对这个懂得也不是很透辟,此次就说说JOIN操纵. 图片是很容易被接受和懂得, ...
- Codeforces Beta Round #51 C. Pie or die 博弈论找规律 有趣的题~
C. Pie or die Time Limit: 20 Sec Memory Limit: 256 MB 题目连接 http://codeforces.com/contest/55/problem/ ...
- LVS + keepalived + nginx + tomcat 实现主从热备 + 负载均衡
前言 首先声明下,由于这两天找资料,看了不少博客 ,但是出于不细心,参考者的博客地址没有记录下来,所有文中要是出现了与大家博客相同的地方,那么请大家在评论区说明并附上博客地址,我好引用进来:这里表示抱 ...
- C#_自动化测试 (四) 自动卸载软件
在平常的测试工作中,经常要安装软件,卸载软件, 即繁琐又累. 安装和卸载完全可以做成自动化. 安装软件我们可以通过自动化框架,自动点击Next,来自动安装. 卸载软件我们可以通过msiexec命 ...
- 实验-hadoop开发环境部署
hadoop-0.20.2自带了eclipse插件,比如1.0.0和2.2.0就没有 1.windows下 1)把插件hadoop-0.20.2-eclipse-plugin.jar复制到eclips ...