网络爬虫:使用Scrapy框架编写一个抓取书籍信息的爬虫服务
Python
数据抓取框架,速度快,强大,而且使用简单。
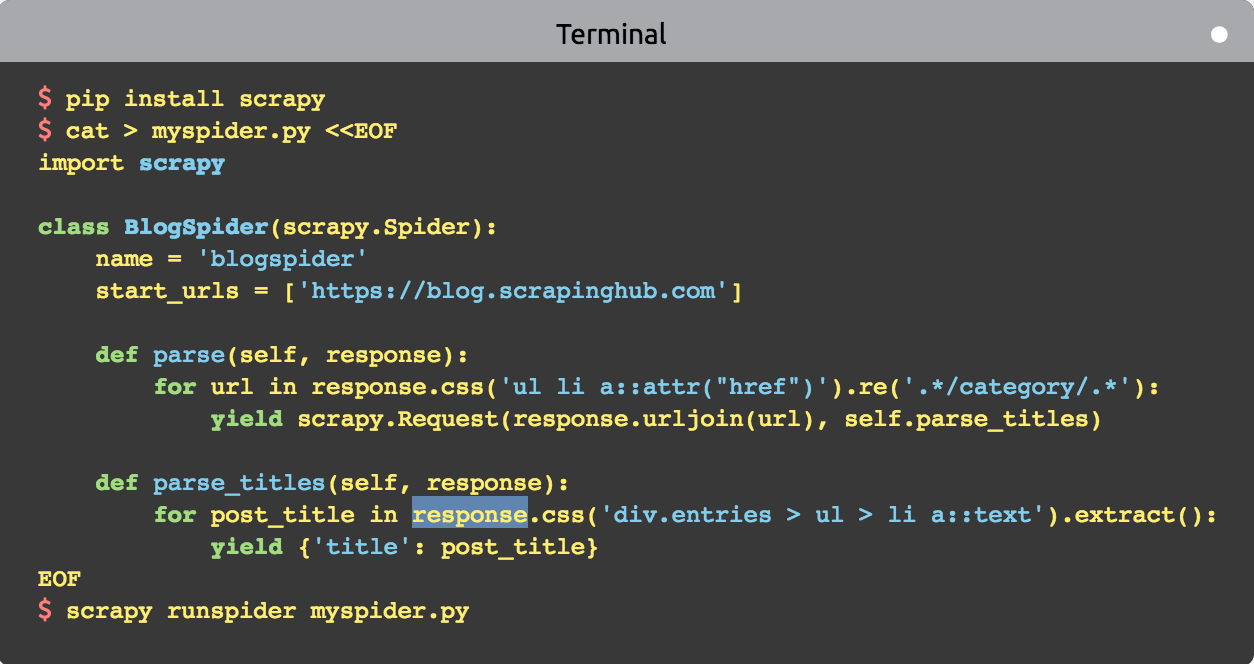
- 当执行scrapy runspider xxx.py命令的时候, Scrapy在项目里查找Spider(蜘蛛
网络爬虫:使用Scrapy框架编写一个抓取书籍信息的爬虫服务的更多相关文章
- 网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(3): 抓取amazon.com价格
通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码.(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息 ...
- 网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码
这一篇首先从allitebooks.com里抓取书籍列表的书籍信息和每本书对应的ISBN码. 一.分析需求和网站结构 allitebooks.com这个网站的结构很简单,分页+书籍列表+书籍详情页. ...
- 网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(1): 基础知识Beautiful Soup
开始学习网络数据挖掘方面的知识,首先从Beautiful Soup入手(Beautiful Soup是一个Python库,功能是从HTML和XML中解析数据),打算以三篇博文纪录学习Beautiful ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- 30分钟编写一个抓取 Unsplash 图片的 Python爬虫
我一直想用 Python and Selenium 创建一个网页爬虫,但从来没有实现它. 几天前, 我决定尝试一下,这听起来可能是挺复杂的, 然而编写代码从 Unsplash 抓取一些美丽的图片 ...
- 使用scrapy框架来进行抓取的原因
在python爬虫中:使用requests + selenium就可以解决将近90%的爬虫需求,那么scrapy就是解决剩下10%的吗? 这个显然不是这样的,scrapy框架是为了让我们的爬虫更强大. ...
- 零基础写python爬虫之使用Scrapy框架编写爬虫
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻 ...
- 网络爬虫值scrapy框架基础
简介 Scrapy是一个高级的Python爬虫框架,它不仅包含了爬虫的特性,还可以方便的将爬虫数据保存到csv.json等文件中. 首先我们安装Scrapy. 其可以应用在数据挖掘,信息处理或存储历史 ...
- Python网络爬虫之Scrapy框架(CrawlSpider)
目录 Python网络爬虫之Scrapy框架(CrawlSpider) CrawlSpider使用 爬取糗事百科糗图板块的所有页码数据 Python网络爬虫之Scrapy框架(CrawlSpider) ...
随机推荐
- Beanstalkd一个高性能分布式内存队列系统
高性能离不开异步,异步离不开队列,内部是Producer-Consumer模型的原理. 设计中的核心概念: job:一个需要异步处理的任务,是beanstalkd中得基本单元,需要放在一个tube中: ...
- 深入理解CSS六种颜色模式
前面的话 赏心悦目的颜色搭配让人感到舒服,修改元素颜色的功能让人趋之若鹜.但颜色规划不当,会让网站用户无所适从.颜色从<font color="">发展至今,保留了很多 ...
- C++ 11 多线程--线程管理
说到多线程编程,那么就不得不提并行和并发,多线程是实现并发(并行)的一种手段.并行是指两个或多个独立的操作同时进行.注意这里是同时进行,区别于并发,在一个时间段内执行多个操作.在单核时代,多个线程是并 ...
- java设计模式之--单例模式
前言:最近看完<java多线程编程核心技术>一书后,对第六章的单例模式和多线程这章颇有兴趣,我知道我看完书还是记不住多少的,写篇博客记录自己所学的只是还是很有必要的,学习贵在坚持. 单例模 ...
- .NET平台和C#编程的总结
第一章 简单认识.NET框架 (1)首先我们得知道 .NET框架具有两个主要组件:公共语言进行时CLR(Common Language Runtime)和框架类库FCL(Framework ...
- 升级npm
查看npm的所有版本 运行命令: npm view npm versions 命令运行后,会输出到目前为止npm的所有版本. [ '1.1.25', '1.1.70', '1.1.71', '1.2. ...
- thinkphp-无限分类下根据任意部门获取顶级部门ID
根据所得到的部门编号获取顶级部门ID: 参数 - department_id 表格组织架构: tab_departments department_id parent_id name 1 1 顶级 2 ...
- hadoop 笔记(zookeeper)
1.安装 需要提前安装java环境,本文下载zookeeper-3.3.6.tar.gz包. 1.1 tar -zxvf zookeeper-3.3.6.tar.gz 1.2 修改conf中的zoo_ ...
- zerojs! 造出最好的 CMS 轮子
zerojs是一个基于nodejs.angularjs.git的CMS.在它之上可以继续开发出博客.论坛.wiki等类似的内容管理型系统. 拥抱开发者和社区 层次清晰,高度解耦.前后端即使分开也都是完 ...
- 周六搞事情,微信小程序开发文档已放出!
程序员们,你们有事干了! 个人感觉不管是什么形式的UI技术,都无法决定一个产品的生死,核心还是服务和模式的创新. 某些方面和ApiCloud好像,但发展前景远远胜过ApiCloud. 微信小程序可以为 ...
- 网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(3): 抓取amazon.com价格