网络爬虫:使用Scrapy框架编写一个抓取书籍信息的爬虫服务
Python
数据抓取框架,速度快,强大,而且使用简单。
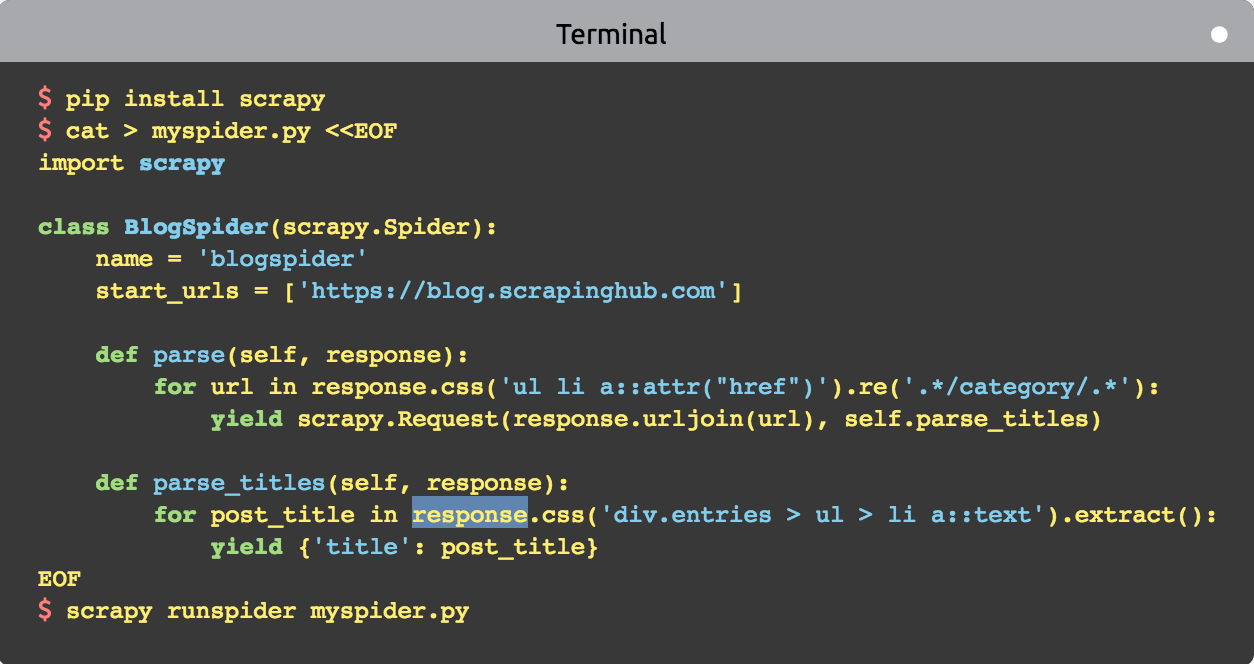
- 当执行scrapy runspider xxx.py命令的时候, Scrapy在项目里查找Spider(蜘蛛
网络爬虫:使用Scrapy框架编写一个抓取书籍信息的爬虫服务的更多相关文章
- 网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(3): 抓取amazon.com价格
通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码.(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息 ...
- 网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码
这一篇首先从allitebooks.com里抓取书籍列表的书籍信息和每本书对应的ISBN码. 一.分析需求和网站结构 allitebooks.com这个网站的结构很简单,分页+书籍列表+书籍详情页. ...
- 网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(1): 基础知识Beautiful Soup
开始学习网络数据挖掘方面的知识,首先从Beautiful Soup入手(Beautiful Soup是一个Python库,功能是从HTML和XML中解析数据),打算以三篇博文纪录学习Beautiful ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- 30分钟编写一个抓取 Unsplash 图片的 Python爬虫
我一直想用 Python and Selenium 创建一个网页爬虫,但从来没有实现它. 几天前, 我决定尝试一下,这听起来可能是挺复杂的, 然而编写代码从 Unsplash 抓取一些美丽的图片 ...
- 使用scrapy框架来进行抓取的原因
在python爬虫中:使用requests + selenium就可以解决将近90%的爬虫需求,那么scrapy就是解决剩下10%的吗? 这个显然不是这样的,scrapy框架是为了让我们的爬虫更强大. ...
- 零基础写python爬虫之使用Scrapy框架编写爬虫
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻 ...
- 网络爬虫值scrapy框架基础
简介 Scrapy是一个高级的Python爬虫框架,它不仅包含了爬虫的特性,还可以方便的将爬虫数据保存到csv.json等文件中. 首先我们安装Scrapy. 其可以应用在数据挖掘,信息处理或存储历史 ...
- Python网络爬虫之Scrapy框架(CrawlSpider)
目录 Python网络爬虫之Scrapy框架(CrawlSpider) CrawlSpider使用 爬取糗事百科糗图板块的所有页码数据 Python网络爬虫之Scrapy框架(CrawlSpider) ...
随机推荐
- C#与C++的发展历程第三 - C#5.0异步编程巅峰
系列文章目录 1. C#与C++的发展历程第一 - 由C#3.0起 2. C#与C++的发展历程第二 - C#4.0再接再厉 3. C#与C++的发展历程第三 - C#5.0异步编程的巅峰 C#5.0 ...
- 使用mybatis-generator在自动生成Model类和Mapper文件
使用mybatis-generator插件可以很轻松的实现mybatis的逆向工程,即,能通过表结构自动生成对应的java类及mapper文件,可以大大提高工作效率,并且它提供了很多自定义的设置可以应 ...
- AJAX实现登录界面
使用php跳转界面和AJAX都可实现登录界面的跳转的登录失败对的提醒.但是,php跳转的方式 需要额外加载其他界面,用户体验差.AJAX可实现当前页面只刷新需要的数据,不对当前网页进行 重新加载或者是 ...
- 用FSM一键制作逐帧动画雪碧图 Vue2 + webpack
因为工作需要要将五六十张逐帧图拼成雪碧图,网上想找到一件制作工具半天没有找到,就自己用canvas写了一个. 写成之后就再没有什么机会使用了,因此希望有人使用的时候如果遇到bug了能及时反馈给我. 最 ...
- jQuery幻灯片插件autoPic
原文地址:Jquery自定义幻灯片插件 插件效果图: 演示地址:autoPic项目地址:autoPic 欢迎批评指正!
- C#通过NPOI操作Excel
参考页面: http://www.yuanjiaocheng.net/webapi/create-crud-api-1-post.html http://www.yuanjiaocheng.net/w ...
- React Native Android gradle下载慢问题解决
很多人会遇到 初次运行 react-native run android的时候 gradle下载极慢,甚至会失败的问题 如下图 实际上这个问题好解决的 首先 把对应版本的gradle下载到本地任意一个 ...
- iOS app内存分析套路
iOS app内存分析套路 Xcode下查看app内存使用情况有2中方法: Navigator导航栏中的Debug navigator中的Memory Instruments 一.Debug navi ...
- Java企业实训 - 01 - Java前奏
前言: 虽然个人专攻.NET方向,不过由于个人是干教育行业的,方方面面的东西,不能说都必须精通,但肯定多少都会涉及到. 一个菜鸟学员,从啥都不会,经过一步步学习,最后到企业上手掌管一个模块甚至一个项目 ...
- Oracle:一个用户操作多个表空间中表的问题(转)
原文地址:http://blog.csdn.net/shmiloy001/article/details/6287317 首先,授权给指定用户. 一个用户的默认表空间只能有一个,但是你可以试下用下面的 ...
- 网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(3): 抓取amazon.com价格