python爬虫笔记之re.compile.findall()
re.compile.findall原理是理解了,但输出不大理解(主要是加了正则表达式的括号分组)
一开始不懂括号的分组及捕捉,看了网上这个例子(如下),然而好像还是说不清楚这个括号的规律(还是说我没找到或是我理解能力太差),还是看不出括号的规律,于是更多的尝试(第二张大图),并最后总结规律。
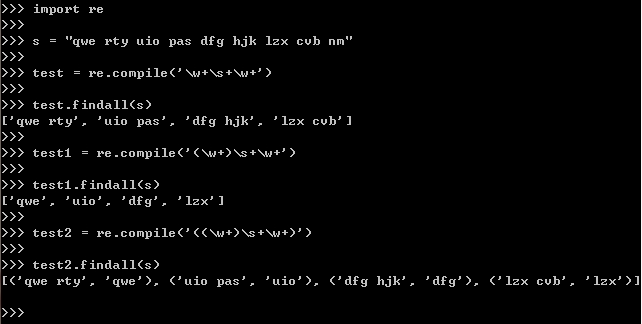



下图是为了尝试出括号分组的规律,下面是总结
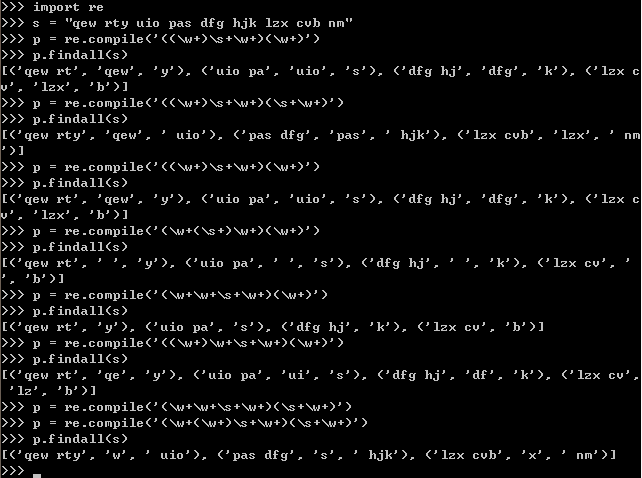
就从最后一次匹配说起吧
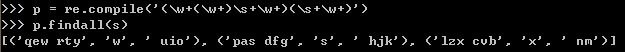
分析:首先是匹配的顺序,分析某个括号时,暂时去掉其它括号,易读
第一步,先对整个‘ ’内的规则作出匹配,整体匹配,先去括号(易读),即先从s中匹配出第一个【\w+\w+\s+\w+\s+\w+】(去括号的样子),但由于没有括号将这个整体扩上,所以没有捕捉(即不用输出),第一个匹配到的大字符串是“qew rty uio”
【可以这样一个个对应】
\w+ \w+ \s+ \w+ \s+ \w+
| | | | | |
qe w rty uio
对应图
第二步,匹配到的字符串再进行匹配捕捉,即输出,现在从左往右,一个个左括号捕捉起,第一个左括号【(\w+\w+\s+\w+)】(暂时去掉了嵌套在中间的左括号,易读),则匹配到上面字符串中(“qew rty uio”)的"qew rty"(可对照上面的对应图),由于是括号内,所以捕捉(即输出)
第三步,第二个括号,\w+(\w+)\s+\w+(暂时去掉其它括号) 匹配上一括号中的字符串(“qew rty”),即是匹配到‘w’(可对照上面的对应图),由于是括号内,所以捕捉(即输出)
第四步,第三个括号,\w+\w+\s+\w+(\s+\w+)(暂时去掉其他括号)匹配并输出第一步中的字符串,即是“uio”
总结:
1、首先全部去括号的匹配,画出对应图,这样很清晰,然后看括号内的即捕捉输出,然后在匹配的文本(s)再寻找下一个匹配的大字符串,一直找下去……
2、去括号是为了清晰的分析,主要注意从第一个左括号开始分析起
3、如果是嵌套括号,如(((a)b)(c)d),若要捕捉a括号的字符,则先需要匹配最外面的括号,然后在慢慢往里面匹配,即是先匹配出d括号的内容,再在d括号里面匹配出b括号的内容,再在b括号中匹配出a括号的内容,然后所有括号里的,输出,按左边第一个括号所匹配的字符串排列:(d,b,a,c)
如有错误,麻烦及时指正,谢谢!
python爬虫笔记之re.compile.findall()的更多相关文章
- [Python爬虫笔记][随意找个博客入门(一)]
[Python爬虫笔记][随意找个博客入门(一)] 标签(空格分隔): Python 爬虫 2016年暑假 来源博客:挣脱不足与蒙昧 1.简单的爬取特定url的html代码 import urllib ...
- Python爬虫笔记一(来自MOOC) Requests库入门
Python爬虫笔记一(来自MOOC) 提示:本文是我在中国大学MOOC里面自学以及敲的一部分代码,纯一个记录文,如果刚好有人也是看的这个课,方便搬运在自己电脑上运行. 课程为:北京理工大学-嵩天-P ...
- python爬虫笔记Day01
python爬虫笔记第一天 Requests库的安装 先在cmd中pip install requests 再打开Python IDM写入import requests 完成requests在.py文 ...
- Python爬虫笔记技术篇
目录 前言 requests出现中文乱码 使用代理 BeautifulSoup的使用 Selenium的使用 基础使用 Selenium获取网页动态数据赋值给BeautifulSoup Seleniu ...
- Python爬虫笔记安装篇
目录 爬虫三步 请求库 Requests:阻塞式请求库 Requests是什么 Requests安装 selenium:浏览器自动化测试 selenium安装 PhantomJS:隐藏浏览器窗口 Ph ...
- Python爬虫笔记(一):爬虫基本入门
最近在做一个项目,这个项目需要使用网络爬虫从特定网站上爬取数据,于是乎,我打算写一个爬虫系列的文章,与大家分享如何编写一个爬虫.这是这个项目的第一篇文章,这次就简单介绍一下Python爬虫,后面根据项 ...
- Python爬虫笔记【一】模拟用户访问之设置请求头 (1)
学习的课本为<python网络数据采集>,大部分代码来此此书. 网络爬虫爬取数据首先就是要有爬取的权限,没有爬取的权限再好的代码也不能运行.所以首先要伪装自己的爬虫,让爬虫不像爬虫而是像人 ...
- python爬虫笔记之re.match匹配,与search、findall区别
为什么re.match匹配不到?re.match匹配规则怎样?(捕一下seo) re.match(pattern, string[, flags]) pattern为匹配规则,即输入正则表达式. st ...
- Python爬虫笔记(一)
个人笔记,仅适合个人使用(大部分摘抄自python修行路) 1.爬虫Response的内容 便是所要获取的页面内容,类型可能是HTML,Json(json数据处理链接)字符串,二进制数据(图片或者视频 ...
随机推荐
- ORACLE 11.2.0.4 安装在 rhel6 上
. 修改host文件,添加本机的host记录 [root@RACDG ~]# vi /etc/hosts 127.0.0.1 localhost localhost.localdomain local ...
- Unity 3d新手上路
作为一位unity新手,初学遇到了不少坑,而且不知道怎么找,发觉网上关于unity的文档好少,还是我暂时没找到. 现在说说void OnTriggerEnter(Collider e),这个函数是我加 ...
- 一次C#和C++的实际应用性能比较(C++允许我们使用任何手段来提高效率,只要愿意做出足够的努力)
05年时,在微软的Rico Mariani做了一次实际应用的C#和C++的性能比较.事情起源于微软著名的元老Raymond Chen(在下敬仰的超级牛人)用C++写了一个英汉词典程序,来描述讲解优化C ...
- winpcap在VS2012 Qt5 X64下的配置
最近在学网络编程,想在windows下用Qt做个网络抓包工具,就要用到WinPcap,而我的电脑的系统是Win7 64位,qt版本是Qt 5.3.1 for Windows 64-bit (VS 20 ...
- Spring Boot配置篇(基于Spring Boot 2.0系列)
1:概述 SpringBoot支持外部化配置,配置文件格式如下所示: properties files yaml files environment variables command-line ar ...
- kubernetes之使用http rest api访问集群
系列目录 在Kubernetes集群中,API Server是集群管理API的入口,由运行在Master节点上的一个名为kube-apiserver的进程提供的服务. 用户进入API可以通过kubec ...
- Vue.js 面试题整理
Vue项目结构介绍 build 文件夹:用于存放 webpack 相关配置和脚本. config 文件夹:主要存放配置文件,比如配置开发环境的端口号.开启热加载或开启gzip压缩等. dist 文件夹 ...
- Markdown教程<3> 数学公式(1)
# Markdown教程<3> 数学公式(1) 1.如何在markdown中使用公式 公式分为行内公式与行间公式,其中: 行内公式使用$ 数学公式 $ 行间公式使用$$ 数学公式 $$ 2 ...
- 深入解析Hyperledger Fabric启动的全过程
在这篇文章中,使用fabric-samples/first-network中的文件进行fabric网络(solo类型的网络)启动全过程的解析.如有错误欢迎批评指正. 至于Fabric网络的搭建这里不再 ...
- 移动端使用rem.js,解决rem.js 行内元素占位问题
父级元素: letter-spacing: -0.5em;font-size: 0; 子级元素: letter-spacing: normal; display: inline-block; vert ...