RANSAC简史(一)——RANSAC之初
在开始正式的介绍之前,先做一个简单的定义,以免产生歧义:
1、本文中的“数据点”是指:
1)对于直线拟合、平面拟合等问题,即为相应的二维/三维坐标点;
2)对于从匹配点中估计基本矩阵、单应矩阵等问题,即为一对匹配点坐标级联组成的向量。
一、RANSAC之前
RANSAC在1981年被Martin A. Fischler and Robert C. Bolles两人提出,以解决给定点集的模型估计问题。在现实应用中,我们经常遇到的情况是:给定的点集中存在错误的点。传统的模型估计方法,大都采用所有的点进行模型最小二乘的拟合,这种方法往往容易受野点影响而得到错误结果(相当于陷入局部最优)。该最小二乘法的一种变种是,首先用所有点估计模型,而后剔除误差较大的点,而后再次估计模型,以此迭代。然而,由于野点的影响,往往会导致最开始估计的模型不准确,从而导致正确的点被剔除掉,最终导致模型估计的失败。下面是一个例子:
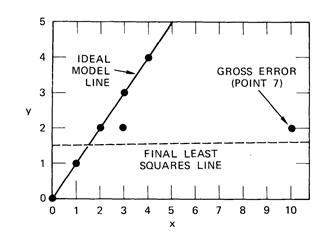
由于点7的影响,导致正确的点被剔除,最终拟合的直线为虚线,而不是正确的实线。
二、RANSAC之1.0版本
RANSAC方法为第一个方法,采用最少能决定模型的点进行模型估计的方法,最原始的方法被描述为:

整个算法被分为三步:
1) 从所有的数据中采样n个点,以能确定出模型;
2) 利用采样点计算模型;
3) 利用模型来确定其他点是否是内点;如果内点率达到指定值,算法终止,并用所有内点优化模型;否则,继续上述过程,直到达到指定的迭代次数,此时将最高内点率对应的模型作为最终模型。
上述思路简洁明了,其核心思想就是:待求解的模型,应该是能同时使最多数据点都符合模型。从这一思想从发,其实可以有另一条不同的思路,后续我会进一步介绍。
三、RANSAC 1.0版本剖析
下面让我们回顾下该方法,看该方法在具体应用中,还需要解决哪些问题:
算法第一步,从数据中采样n个点,这里要求n为能确定模型的最小的数据量,那么该选取怎样的采样准则?从所有数据中采样,还是仅仅从部分数据(总数据的一个子集)中进行采样?每个数据被采集的可能性是否相同?采取随机采样,还是按一定顺序进行采样?是否需要避免同一组数据被重复采样,如果需要,该如何避免?这里先给出通常的做法,更加细致的分析也留到后续。通常情况下,我们在所有数据中进行随机采样,且所有数据每次被采样的可能性是一样的,而且我们通常不考虑两次采样得到的样本是重复的。
算法第二步,利用采样数据计算模型。我们知道,在第一步中,我们要求采样点尽可能少,同时我们也知道,当数据点存在噪声(通常考虑为高斯噪声)时,样本点的数目越多,求解的模型越准确。这就意味着我们此刻求解的模型不够准确,那么这个不够准确的模型,是否能够用来判断其他点是否是内点?其次,如果我们待求解的问题,无法用一个模型,或者无法用一个仅包含若干个参数的模型进行表达,此时是否还能使用“最大一致性”的思路?针对第一个问题,我们通常认为虽然模型存在误差,但是在后续内点判断中,我们设定一定的误差阈值,因此能够用该模型来近似最终模型。同时,一些RANSAC的改进,采用“局部优化”技术来一定层度解决这一问题,关于该方法的讨论,同样会在后续,进行详细的剖析。针对第二个问题,有一些无模型的“最大一致性估计”方法,同样也留待后续介绍。
算法第三步,首先,利用求解的模型确定其他点是否为内点。一个重要的问题是,如何判断其他点是否为内点?通过其他点与模型的符合程度?那么如何设置这样一个阈值?有时一个数据是否为内点(例如两个数据点相冲突,不可能同时为内点。这种情况会发生在:根据两张图特征点匹配,求解其基础矩阵时,如果A图中的两个点,匹配到B图中的同一个点),还与其他数据相关,那么此时如何考虑数据间的关联?
其次,“如果内点率达到指定值,则终止算法”,那么如何设置这样一个阈值?因为对于一组数据,通常情况下我们是无法知道其最大内点率。(但问题也不是绝对,我们也可以事先求解出最优模型对应的内点率。哈哈,是不是很crazy,这也留待后续的剖析。)因此,这一迭代的终止条件,现在的RANSAC算法中,已经很少见了。我们通常采用一定置信度下,达到能够保证至少一次所有的采样点都为内点的最少采样次数,作为终止条件。
最后,如何确定最少的采样次数。原文中提出了两种方案。假设在一次采样中,所有点都为内点的概率为p,那么“所有采样点都为内点首先发生在第k次采样”这一事件服从几何分布(参考射击时第k次才命中这一问题),于是:
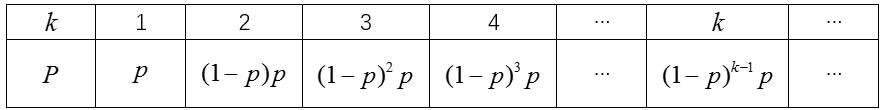
原文方案一:求解k的期望值和方差,采用期望值加上2到3倍方差,作为采样次数。这种方案,可以理解为求解分布的“上分位数”,以保证以一定“所有采样点都为内点”在进行k次采样后发生过。
原文方案二:如果要求第 次采样后,至少一次“所有采样点都为内点”的概率大于 那么:
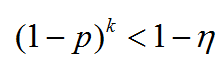
由此,
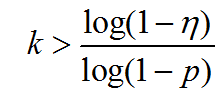
这里一次采样中所有点都为内点的概率为:
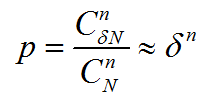
其中N为总数据量,n为最小采样数,为内点率。
在此,我们可以看出,为什么选取最少的样本点进行模型估计。因为,采样量每增加1,对应需要进行的采样次数就增加很多,尤其是在内点率很低的情况下,这种情况尤其严重。
写到这里,我们已经对RANSAC最初版本进行了详细的介绍,同时我们很具体剖析了其各个步骤可能面临的问题。针对这些问题,后续衍生出了很多RANSAC的变种,我们将在后续进行具体的介绍。
参考文献:
[1] Fischler M A . Readings in Computer Vision || Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography[J]. Readings in Computer Vision, 1987:726-740.
RANSAC简史(一)——RANSAC之初的更多相关文章
- RANSAC简史
前言 在进行泡泡机器人[图灵智库]栏目的翻译的过程中,我发现在2018-2019的顶会中,依然有很多文章(我看到的不少于6篇)对RANSAC进行各种改进,这令我感到很吃惊.毕竟该方法在1981年就被提 ...
- 随机抽样一致算法(Random sample consensus,RANSAC)
作者:桂. 时间:2017-04-25 21:05:07 链接:http://www.cnblogs.com/xingshansi/p/6763668.html 前言 仍然是昨天的问题,别人问到最小 ...
- Regression:Generalized Linear Models
作者:桂. 时间:2017-05-22 15:28:43 链接:http://www.cnblogs.com/xingshansi/p/6890048.html 前言 本文主要是线性回归模型,包括: ...
- SLAM for dummies中文翻译
1.简介 本文的主要目的是简单介绍移动机器人领域中广泛应用的技术SLAM(同步定位与地图绘制)的理论基础以及应用细节.虽然目前存在很多关于SLAM技术的方方面面的论文,但是对于一个新手来说,仍然需要花 ...
- 再谈AR中的图像识别算法
之前在<浅谈移动平台创新玩法>简单的猜测了easyar中使用的图像识别算法,基于图片指纹的哈希算法的图片检索 .后再阿里引商大神的指点下,意识到图片检测只适用于静态图片的识别,只能做AR脱 ...
- PCL采样一致性算法
在计算机视觉领域广泛的使用各种不同的采样一致性参数估计算法用于排除错误的样本,样本不同对应的应用不同,例如剔除错误的配准点对,分割出处在模型上的点集,PCL中以随机采样一致性算法(RANSAC)为核心 ...
- Generalized Linear Models
作者:桂. 时间:2017-05-22 15:28:43 链接:http://www.cnblogs.com/xingshansi/p/6890048.html 前言 主要记录python工具包:s ...
- Signal Processing and Pattern Recognition in Vision_15_RANSAC:Random Sample Consensus——1981
此部分是 计算机视觉中的信号处理与模式识别 与其说是讲述,不如说是一些经典文章的罗列以及自己的简单点评.与前一个版本不同的是,这次把所有的文章按类别归了类,并且增加了很多文献.分类的时候并没有按照传统 ...
- Python 进行目标检测
一.前言 从学单片机开始鼓捣C语言,到现在为了学CV鼓捣Python,期间在CSDN.简书.博客园和github这些地方得到了很多帮助,所以也想把自己做的一些小东西分享给大家,希望能帮助到别人.记录人 ...
随机推荐
- C#7.3 新增功能
连载目录 [已更新最新开发文章,点击查看详细] C# 7.3 版本有两个主要主题. 第一个主题提供使安全代码的性能与不安全代码的性能一样好的功能. 第二个主题提供对现有功能的增量改进. 此外,在 ...
- sql nvarchar类型和varchar类型存储中文字符长度
今天遇到了,随手记录一下. sql server 存储数据里面 NVARCHAR 记录中文的时候是 一个中文对应一个字符串长度,记录英文也是一个字母一个长度 标点符号也是一样. ...
- APP爬虫(2)把小姐姐的图片down下来
APP爬虫(1)想学新语言,又没有动力,怎么办? 书接上文.使用appium在帖子列表界面模拟上划动作,捕捉不到列表的规律.上划结束后,列表只能获取到屏幕呈现的部分,而且下标还是从0开始的. 根据酸奶 ...
- Linux版本划分——基于打包方式
基于Dpkg (Debian系) Debian GNU / Linux是一种强调使用自由软件的发行版.它支持多种硬件平台.Debian及其派生发行版使用deb软件包格式,并使用dpkg及其前端作为包管 ...
- IntegerCache的妙用和陷阱
转载自IntegerCache的妙用和陷阱 考虑下面的小程序,你认为会输出为什么结果? public class Test { public static void main(String[] ...
- 高级查询语句____ Mysql
MySQL高级查询 高级查询 关键字书写顺序 关键字执行顺序select:投影结果 1 5 from:定位到表 2 1 where:分组前第一道过滤 ...
- SpringBoot Admin 使用指南
什么是 SpringBoot Admin? Spring Boot Admin 是一个管理和监控你的 Spring Boot 应用程序的应用程序.这些应用程序通过 Spring Boot Admin ...
- 【iOS】"OS X"想要进行更改。键入管理员的名称和密码以允许执行此操作("OS X"想使用系统钥匙串)
今天真机调试的时候遇到了这个问题,如下图: 每次调试都要输入两次用户名和密码,好麻烦的说…… 关键时刻找到了这篇文章:"Mac OS X"想要进行更改.键入管理员的名称和密码以允许 ...
- dubbo文档笔记
配置覆盖关系 以 timeout 为例,显示了配置的查找顺序,其它 retries, loadbalance, actives 等类似: 方法级优先,接口级次之,全局配置再次之. 如果级别一样,则消费 ...
- 我的第一个py爬虫-小白(beatifulsoup)
一.基本上所有的python第一步都是安装.安装 我用到的第三方安装包(beatifulsoup4.re.requests).还要安装lxml 二.找个http开头的网址我找的是url="h ...