Hadoop之HDFS文件系统
概念
HDFS,它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的设计适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据分析,并不适合用来做网盘应用。
组成
1)HDFS集群包括,NameNode和DataNode以及Secondary Namenode。
2)NameNode负责管理整个文件系统的元数据,以及每一个路径(文件)所对应的数据块信息。
3)DataNode 负责管理用户的文件数据块,每一个数据块都可以在多个datanode上存储多个副本。
4)Secondary NameNode用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
HDFS 文件块大小
HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M
HDFS的块比磁盘的块大,其目的是为了最小化寻址开销。如果块设置得足够大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。因而,传输一个由多个块组成的文件的时间取决于磁盘传输速率。
如果寻址时间约为10ms,而传输速率为100MB/s,为了使寻址时间仅占传输时间的1%,我们要将块大小设置约为100MB。默认的块大小实际为64MB,但是很多情况下HDFS使用128MB的块设置。
块的大小:10ms*100*100M/s = 100M
HFDS命令行操作
常用命令实操
(1)-help:输出这个命令参数
bin/hdfs dfs -help rm
(2)-ls: 显示目录信息
hadoop fs -ls /
(3)-mkdir:在hdfs上创建目录
hadoop fs -mkdir -p /aaa/bbb/cc/dd
(4)-moveFromLocal从本地剪切粘贴到hdfs
hadoop fs - moveFromLocal /home/hadoop/a.txt /aaa/bbb/cc/dd
(5)-moveToLocal:从hdfs剪切粘贴到本地(不存在)
hadoop fs - moveToLocal /aaa/bbb/cc/dd /home/hadoop/a.txt
(6)--appendToFile :追加一个文件到已经存在的文件末尾
hadoop fs -appendToFile ./hello.txt /hello.txt
(7)-cat :显示文件内容
(8)-tail:显示一个文件的末尾
hadoop fs -tail /weblog/access_log.1
(9)-text:以字符形式打印一个文件的内容
hadoop fs -text /weblog/access_log.1
(10)-chgrp 、-chmod、-chown:linux文件系统中的用法一样,修改文件所属权限
hadoop fs -chmod 666 /hello.txt
hadoop fs -chown someuser:somegrp /hello.txt
(11)-copyFromLocal:从本地文件系统中拷贝文件到hdfs路径去
hadoop fs -copyFromLocal ./jdk.tar.gz /aaa/
(12)-copyToLocal:从hdfs拷贝到本地
hadoop fs -copyToLocal /aaa/jdk.tar.gz
(13)-cp :从hdfs的一个路径拷贝到hdfs的另一个路径
hadoop fs -cp /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
(14)-mv:在hdfs目录中移动文件
hadoop fs -mv /aaa/jdk.tar.gz /
(15)-get:等同于copyToLocal,就是从hdfs下载文件到本地
hadoop fs -get /aaa/jdk.tar.gz
(16)-getmerge :合并下载多个文件,比如hdfs的目录 /aaa/下有多个文件:log.1, log.2,log.3,...
hadoop fs -getmerge /aaa/log.* ./log.sum
(17)-put:等同于copyFromLocal
hadoop fs -put /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
(18)-rm:删除文件或文件夹
hadoop fs -rm -r /aaa/bbb/
(19)-rmdir:删除空目录
hadoop fs -rmdir /aaa/bbb/ccc
(20)-df :统计文件系统的可用空间信息
hadoop fs -df -h /
(21)-du统计文件夹的大小信息
hadoop fs -du -s -h /aaa/*
(22)-count:统计一个指定目录下的文件节点数量
hadoop fs -count /aaa/
(23)-setrep:设置hdfs中文件的副本数量(
这里设置的副本数只是记录在namenode的元数据中,是否真的会有这么多副本,还得看datanode的数量。因为目前只有3台设备,最多也就3个副本,只有节点数的增加到10台时,副本数才能达到10。
)
hadoop fs -setrep 3 /aaa/jdk.tar.gz
HDFS客户端操作(Eclipse)
1.jar包
2.环境变量HADOOP_HOME
3.引用jar
4.创建工程
|
public class HdfsClientDemo1 { public static void main(String[] args) throws Exception { // 1 获取文件系统 Configuration configuration = new Configuration(); // 配置在集群上运行 configuration.set("fs.defaultFS", "hdfs://hadoop102:9000"); FileSystem fileSystem = FileSystem.get(configuration); // 直接配置访问集群的路径和访问集群的用户名称 // FileSystem fileSystem = FileSystem.get(new URI("hdfs://hadoop102:9000"),configuration, "atguigu"); // 2 把本地文件上传到文件系统中 fileSystem.copyFromLocalFile(new Path("f:/hello.txt"), new Path("/hello1.copy.txt")); // 3 关闭资源 fileSystem.close(); System.out.println("over"); } } |
运行时需要配置用户名称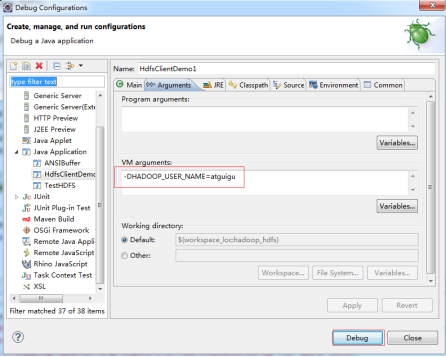
客户端去操作hdfs时,是有一个用户身份的。默认情况下,hdfs客户端api会从jvm中获取一个参数来作为自己的用户身份:-DHADOOP_USER_NAME=用户名称 。
|
@Test public void initHDFS() throws Exception{ // 1 创建配置信息对象 // new Configuration();的时候,它就会去加载jar包中的hdfs-default.xml // 然后再加载classpath下的hdfs-site.xml Configuration configuration = new Configuration(); // 2 设置参数 // 参数优先级: 1、客户端代码中设置的值 2、classpath下的用户自定义配置文件 3、然后是服务器的默认配置 // configuration.set("fs.defaultFS", "hdfs://hadoop102:9000"); configuration.set("dfs.replication", "3"); // 3 获取文件系统 FileSystem fs = FileSystem.get(configuration); // 4 打印文件系统 System.out.println(fs.toString()); } |
Hadoop之HDFS文件系统的更多相关文章
- 搭建maven开发环境测试Hadoop组件HDFS文件系统的一些命令
1.PC已经安装Eclipse Software,测试平台windows10及Centos6.8虚拟机 2.新建maven project 3.打开pom.xml,maven工程项目的pom文件加载以 ...
- Hadoop点滴-HDFS文件系统
1.HDFS中,目录作为元数据,保存在namenode中,而非datanode中 2.HDFS的文件权限模型与POSIX的权限模式非常相似,使用 r w x 3.HDFS的文件执行权限(X)可以 ...
- hadoop中HDFS文件系统 nameNode出现的问题 nameNode无法打开
1,修改core-site.xml文件,先改成localhost,将所有进程关闭stop-all.sh(或者是先关闭所有进程,然后再修改文件),然后重启,在修改core-site.xml文件成ip地址 ...
- Hadoop之HDFS文件系统(二)
HDFS客户端 通过IO流操作HDFS HDFS文件上传 @Test public void putFileToHDFS() throws Exception{ // 1 创建配置信息对象 Confi ...
- hadoop系列二:HDFS文件系统的命令及JAVA客户端API
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- Hadoop Shell命令(基于linux操作系统上传下载文件到hdfs文件系统基本命令学习)
Apache-->hadoop的官网文档命令学习:http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_shell.html FS Shell 调用文件系统( ...
- Hadoop基础-HDFS分布式文件系统的存储
Hadoop基础-HDFS分布式文件系统的存储 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS数据块 1>.磁盘中的数据块 每个磁盘都有默认的数据块大小,这个磁盘 ...
- Hadoop基础-HDFS递归列出文件系统-FileStatus与listFiles两种方法
Hadoop基础-HDFS递归列出文件系统-FileStatus与listFiles两种方法 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. fs.listFiles方法,返回Loc ...
- hadoop HDFS文件系统的特征
hadoop HDFS文件系统的特征 存储极大数目的信息(terabytes or petabytes),将数据保存到大量的节点当中.支持很大单个文件. 提供数据的高可靠性,单个或者多个节点不工作,对 ...
随机推荐
- 【Go】高效截取字符串的一些思考
原文链接:https://blog.thinkeridea.com/201910/go/efficient_string_truncation.html 最近我在 Go Forum 中发现了 [SOL ...
- Shiro learning - 认证流程(3)
Shiro认证流程 在学习认证流程之前,你应该先了解Shiro的基本使用流程 认证 身份认证: 证明用户是谁.用户需要提供相关的凭证principals(身份标识)和Credentials (凭证,证 ...
- CentOS7 下升级Python版本
来博客园的第一篇博客,以后要坚持养成记录.分享的习惯啊,这样生活才会有痕迹~ 服务器版本:CentOS 7.3 64位 旧Python版本:2.7.5 新Python版本:3.8.0 说明:本次配置使 ...
- 追查Could not get a databaseId from dataSource
Mybatis 创建连接池的时候报错: ERROR 2017-03-15 00:44:50,333 commons.JakartaCommonsLoggingImpl:38 Could not get ...
- 基于SEER的区块链版赛亚麻将游戏Pre alpha版本内测啦!
游戏基于SEER测试网络文体平台模块(Culture and Sports Platform,CSP),正在进行数据调试等工作,大家可以尝鲜体验. 此游戏账户和资金等核心系统完全基于区块链,但目前运行 ...
- 你编写的Java代码是咋跑起来的?
如果你是一名 Java 开发人员,你肯定指定 Java 代码有很多种不同的运行方式.比如说可以在开发工具(IDEA.Eclipse等)中运行,可以双击执行 jar 文件运行,也可以在命令行中运行,甚至 ...
- AI Conference 2018人工智能大会 参会总结
主 题:AI Conference 2018人工智能大会 时 间:2018.04.11-4.13 地 点:北京国际饭店会议中心 发起人:O'Reilly 和 Intel 参与部门:研发设计部 参会人员 ...
- ulua、tolua原理解析
在聊ulua.tolua之前,我们先来看看Unity热更新相关知识. 什么是热更新 举例来说: 游戏上线后,玩家下载第一个版本(70M左右或者更大),在运营的过程中,如果需要更换UI显示,或者修改游戏 ...
- 一道国外前端面试题引发的Coding...
刚刚看到CSDN微信公众号一篇文章,关于国外程序员面试前端遇到的一道测试题,有点意思,遂写了下代码,并记录一下~ 题目是这样的: ['Tokyo', 'London', 'Rome', 'Donlon ...
- python items和setdefault函数
items() dict = {'runoob': '菜鸟教程', 'google': 'Google 搜索'} print("Value : %s" % dict.setdefa ...