Spark —— 高可用集群搭建
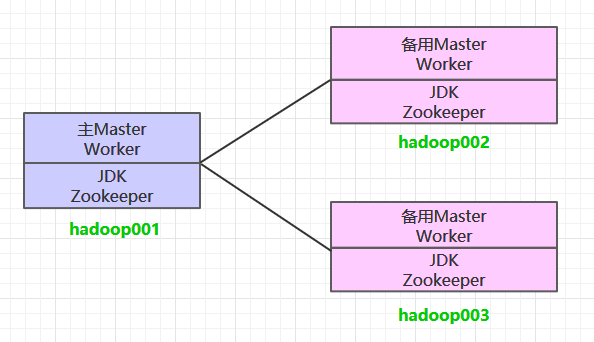
一、集群规划
这里搭建一个3节点的Spark集群,其中三台主机上均部署Worker服务。同时为了保证高可用,除了在hadoop001上部署主Master服务外,还在hadoop002和hadoop003上分别部署备用的Master服务,Master服务由Zookeeper集群进行协调管理,如果主Master不可用,则备用Master会成为新的主Master。
二、前置条件
搭建Spark集群前,需要保证JDK环境、Zookeeper集群和Hadoop集群已经搭建,相关步骤可以参阅:
三、Spark集群搭建
3.1 下载解压
下载所需版本的Spark,官网下载地址:http://spark.apache.org/downloads.html
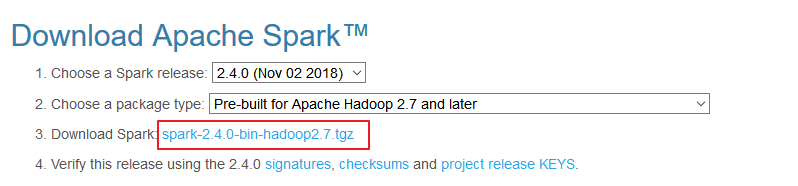
下载后进行解压:
# tar -zxvf spark-2.2.3-bin-hadoop2.6.tgz
3.2 配置环境变量
# vim /etc/profile
添加环境变量:
export SPARK_HOME=/usr/app/spark-2.2.3-bin-hadoop2.6
export PATH=${SPARK_HOME}/bin:$PATH
使得配置的环境变量立即生效:
# source /etc/profile
3.3 集群配置
进入${SPARK_HOME}/conf目录,拷贝配置样本进行修改:
1. spark-env.sh
cp spark-env.sh.template spark-env.sh
# 配置JDK安装位置
JAVA_HOME=/usr/java/jdk1.8.0_201
# 配置hadoop配置文件的位置
HADOOP_CONF_DIR=/usr/app/hadoop-2.6.0-cdh5.15.2/etc/hadoop
# 配置zookeeper地址
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop001:2181,hadoop002:2181,hadoop003:2181 -Dspark.deploy.zookeeper.dir=/spark"
2. slaves
cp slaves.template slaves
配置所有Woker节点的位置:
hadoop001
hadoop002
hadoop003
3.4 安装包分发
将Spark的安装包分发到其他服务器,分发后建议在这两台服务器上也配置一下Spark的环境变量。
scp -r /usr/app/spark-2.4.0-bin-hadoop2.6/ hadoop002:usr/app/
scp -r /usr/app/spark-2.4.0-bin-hadoop2.6/ hadoop003:usr/app/
四、启动集群
4.1 启动ZooKeeper集群
分别到三台服务器上启动ZooKeeper服务:
zkServer.sh start
4.2 启动Hadoop集群
# 启动dfs服务
start-dfs.sh
# 启动yarn服务
start-yarn.sh
4.3 启动Spark集群
进入hadoop001的${SPARK_HOME}/sbin目录下,执行下面命令启动集群。执行命令后,会在hadoop001上启动Maser服务,会在slaves配置文件中配置的所有节点上启动Worker服务。
start-all.sh
分别在hadoop002和hadoop003上执行下面的命令,启动备用的Master服务:
# ${SPARK_HOME}/sbin 下执行
start-master.sh
4.4 查看服务
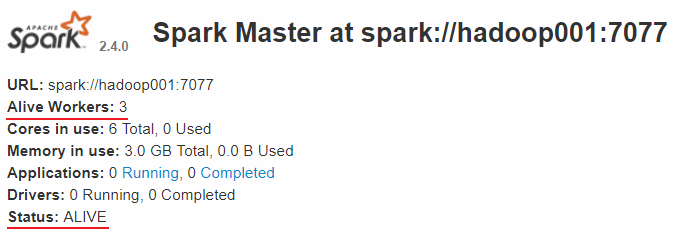
查看Spark的Web-UI页面,端口为8080。此时可以看到hadoop001上的Master节点处于ALIVE状态,并有3个可用的Worker节点。
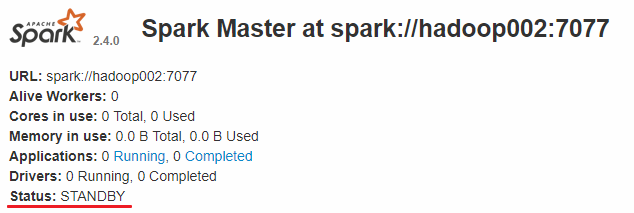
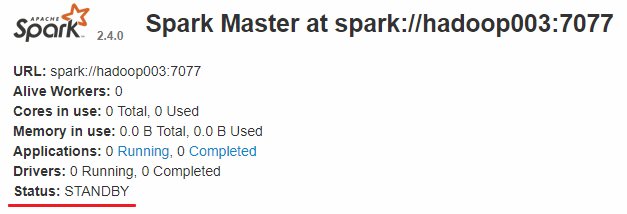
而hadoop002和hadoop003上的Master节点均处于STANDBY状态,没有可用的Worker节点。
五、验证集群高可用
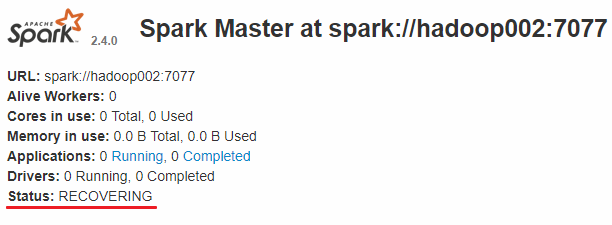
此时可以使用kill命令杀死hadoop001上的Master进程,此时备用Master会中会有一个再次成为主Master,我这里是hadoop002,可以看到hadoop2上的Master经过RECOVERING后成为了新的主Master,并且获得了全部可以用的Workers。
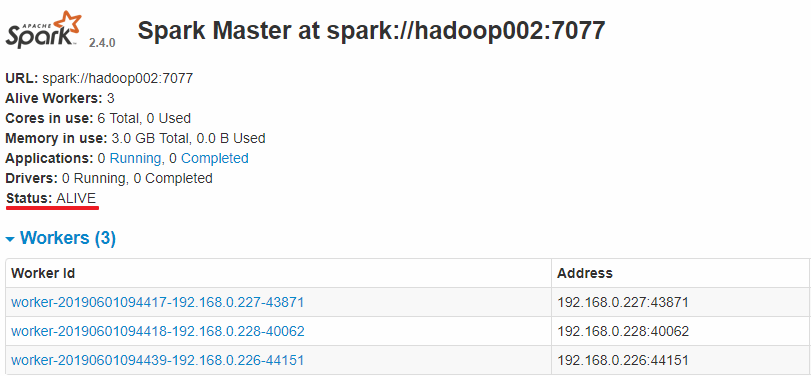
Hadoop002上的Master成为主Master,并获得了全部可以用的Workers。
此时如果你再在hadoop001上使用start-master.sh启动Master服务,那么其会作为备用Master存在。
六、提交作业
和单机环境下的提交到Yarn上的命令完全一致,这里以Spark内置的计算Pi的样例程序为例,提交命令如下:
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--executor-memory 1G \
--num-executors 10 \
/usr/app/spark-2.4.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.0.jar \
100
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Spark —— 高可用集群搭建的更多相关文章
- Spark高可用集群搭建
Spark高可用集群搭建 node1 node2 node3 1.node1修改spark-env.sh,注释掉hadoop(就不用开启Hadoop集群了),添加如下语句 export ...
- spark高可用集群搭建及运行测试
文中的所有操作都是在之前的文章spark集群的搭建基础上建立的,重复操作已经简写: 之前的配置中使用了master01.slave01.slave02.slave03: 本篇文章还要添加master0 ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- hadoop高可用集群搭建小结
hadoop高可用集群搭建小结1.Zookeeper集群搭建2.格式化Zookeeper集群 (注:在Zookeeper集群建立hadoop-ha,amenode的元数据)3.开启Journalmno ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- MongoDB高可用集群搭建(主从、分片、路由、安全验证)
目录 一.环境准备 1.部署图 2.模块介绍 3.服务器准备 二.环境变量 1.准备三台集群 2.安装解压 3.配置环境变量 三.集群搭建 1.新建配置目录 2.修改配置文件 3.分发其他节点 4.批 ...
- RabbitMQ高级指南:从配置、使用到高可用集群搭建
本文大纲: 1. RabbitMQ简介 2. RabbitMQ安装与配置 3. C# 如何使用RabbitMQ 4. 几种Exchange模式 5. RPC 远程过程调用 6. RabbitMQ高可用 ...
- spring cloud 服务注册中心eureka高可用集群搭建
spring cloud 服务注册中心eureka高可用集群搭建 一,准备工作 eureka可以类比zookeeper,本文用三台机器搭建集群,也就是说要启动三个eureka注册中心 1 本文三台eu ...
- MongoDB 3.4 高可用集群搭建(二)replica set 副本集
转自:http://www.lanceyan.com/tech/mongodb/mongodb_repset1.html 在上一篇文章<MongoDB 3.4 高可用集群搭建(一):主从模式&g ...
随机推荐
- VS2015编译环境下CUDA安装配置
CUDA下载 CUDA是NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题,CUDA只支持NVIDIA自家的显卡,过旧的版本型号也不被支持. 下载地址:https://devel ...
- HPC —— 高性能计算
CUDA,目前只有 NVIDIA 支持: OpenCL,CUDA Tesla 卡很贵: 1. 术语及概念 SMP:"对称多处理"(Symmetrical Multi-Process ...
- 第1讲:The nature of Testing--測试的本质
*********声明:本系列课程为Cem Kanner的软件黑盒測试基础的笔记版************** What's A COMPUTER PROGRAM? Textbooks often d ...
- OpenGL(三) RGBA颜色设置
OpenGL支持两种颜色模式:一种是RGBA,一种是颜色索引模式. 像素点附加颜色信息之后,就必须为每一个像素点额外分配一个内存空间保存该点的颜色信息,对于RGBA颜色模式,保存的数据直接代表了颜色, ...
- CefSharp部分效果实现
CefSharp For WPF隐藏滚动条 CefSharp For WPF自定义右键菜单栏 CefSharp For WPF响应页面点击事件
- 芯片超Intel,盈利比肩Apple,三星成科技界"全民公敌"
原标题:芯片超英特尔,盈利比肩苹果:三星现在是科技界“全民公敌”了 当人们津津乐道于三星的手机业务或者是电视业务时,它已静悄悄的拿下了芯片行业的第一,并且凭借着在芯片上的巨大获利让它的老对手们眼红 ...
- WPF应用无法使用Snoop分析的解决办法
如果WPF程序是以管理员身份启动的,Snoop不是用管理员身份启动,那就不行. 用管理员身份启动snoop,就可以了. 管理员身份启动cmd,然后启动snoop,ok.
- [原译]实现IEnumerable接口&理解yield关键字
原文:[原译]实现IEnumerable接口&理解yield关键字 著作权声明:本文由http://leaver.me 翻译,欢迎转载分享.请尊重作者劳动,转载时保留该声明和作者博客链接,谢谢 ...
- SQLServer 进程无法向表进行大容量复制(错误号: 22018 20253)
原文:SQLServer 进程无法向表进行大容量复制 我的环境:SQL SERVER 2008 R2:发布者 ->SQL SERVER 2017 订阅者 进程无法向表“"dbo&quo ...
- SQLServer 服务器架构迁移
原文:SQLServer 服务器架构迁移 最近服务器架构迁移,将原来的服务器架构迁移到新的服务器,新的服务器在硬件方面比之前更好!原来服务器使用双向同步,并且为水平划分到多个数据库服务器.迁移过程中, ...