scrapy框架抓取表情包/(python爬虫学习)
抓取网址:https://www.doutula.com/photo/list/?page=1
1.创建爬虫项目:scrapy startproject biaoqingbaoSpider
2.创建爬虫文件:scrapy genspider biaoqingbao doutula.com
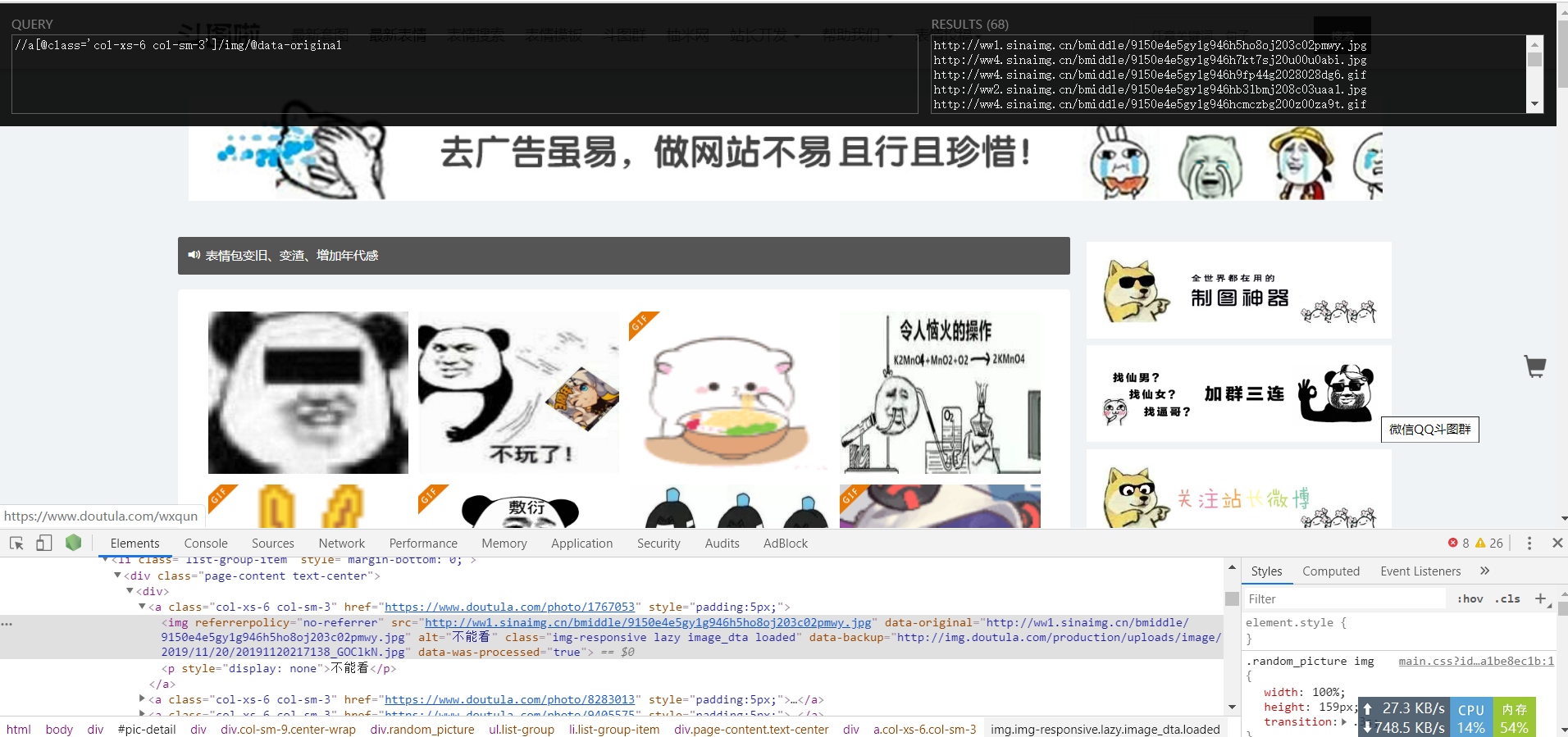
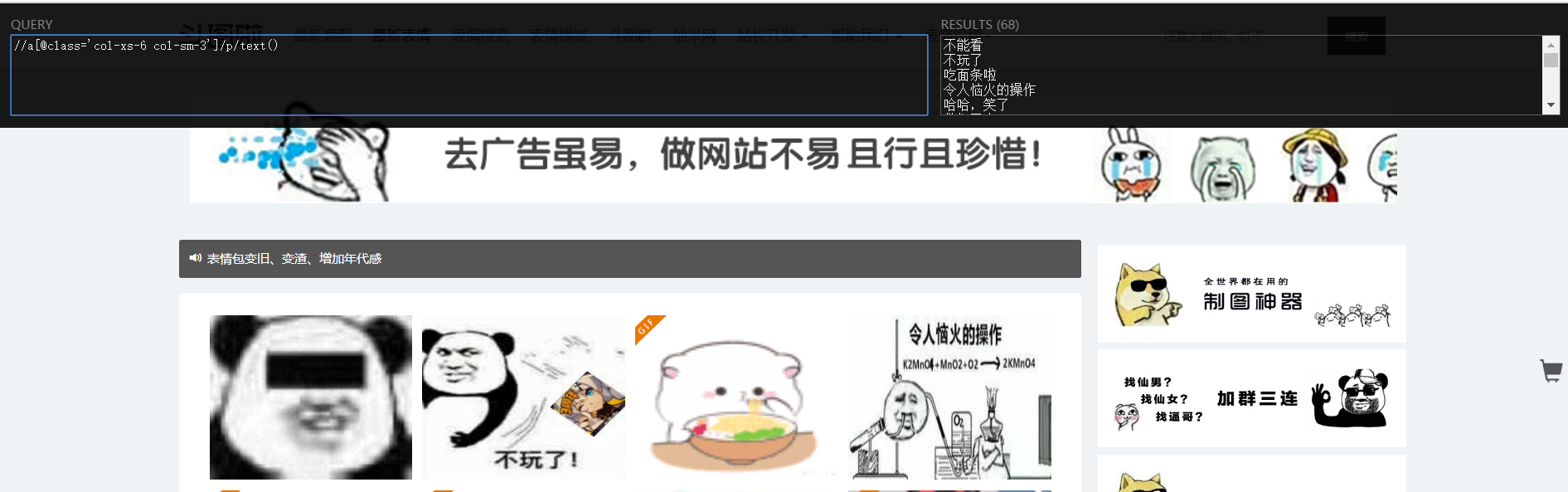
- xpath提取图片链接和名字:
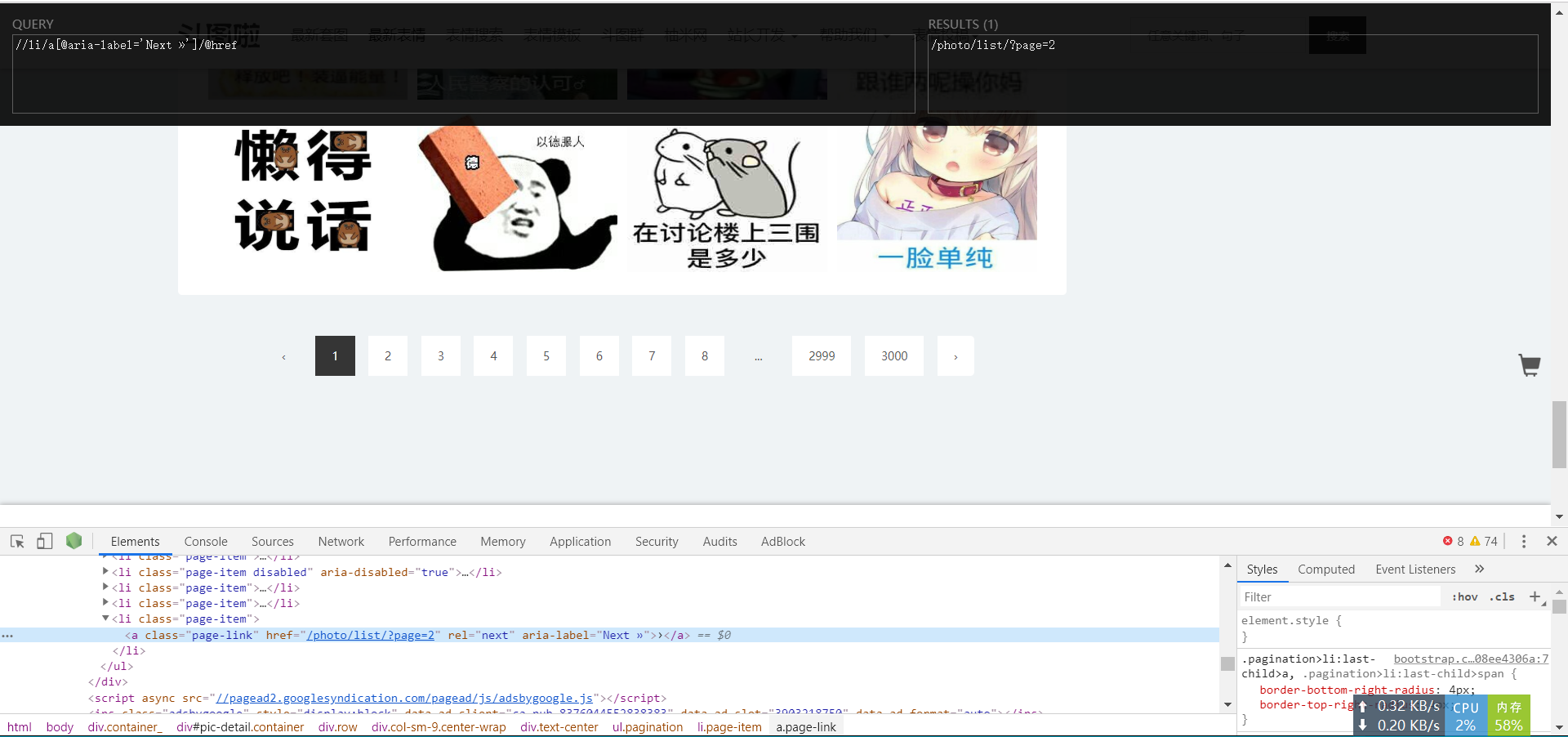
- 提取网址后缀,用于实现自动翻页
3.编写爬虫文件:
# -*- coding: utf-8 -*-
import scrapy
import requests class BiaoqingbaoSpider(scrapy.Spider):
name = 'biaoqingbao'
allowed_domains = ['doutula.com']
start_urls = ['http://www.doutula.com/photo/list/?page=1'] def parse(self, response):
#提取地址和图片名称
pictureUrls = response.xpath("//a[@class='col-xs-6 col-sm-3']/img/@data-original").extract()
pictureName = response.xpath("//a[@class='col-xs-6 col-sm-3']/p/text()").extract() #提取网址后缀,用于实现自动翻页
next_page = response.xpath("//li/a[@aria-label='Next »']/@href").extract_first() for i in range(len(pictureUrls)):
url = pictureUrls[i]
name = pictureName[i]
self.getPicture(url=url, name=name) #对每个图片调用getPicture下载图片并命名 #自动翻页
if next_page:
next_url = response.urljoin(next_page) #返回新的网址
yield scrapy.Request(next_url, callback=self.parse) #回调函数 #自定义函数,用于下载图片,因为刚学太菜,就只有先用requests下载了
def getPicture(self, url, name):
response = requests.get(url)
suffix = url.split(".")[-1] #提取图片链接地址的后缀,因为有jpg和gif图片格式
#二进制格式写入图片
with open("biaoqingbaoSpider/spiders/images/"+name+ "." + suffix, "wb") as fp:
fp.write(response.content)
4.执行爬虫文件:scrapy crawl biaoqingbao
- 切记:觉得爬差不多ctrl + c中止,不中止它会自动爬取到最后一页(3000页),当然也可以自己在代码里设置爬取多少页
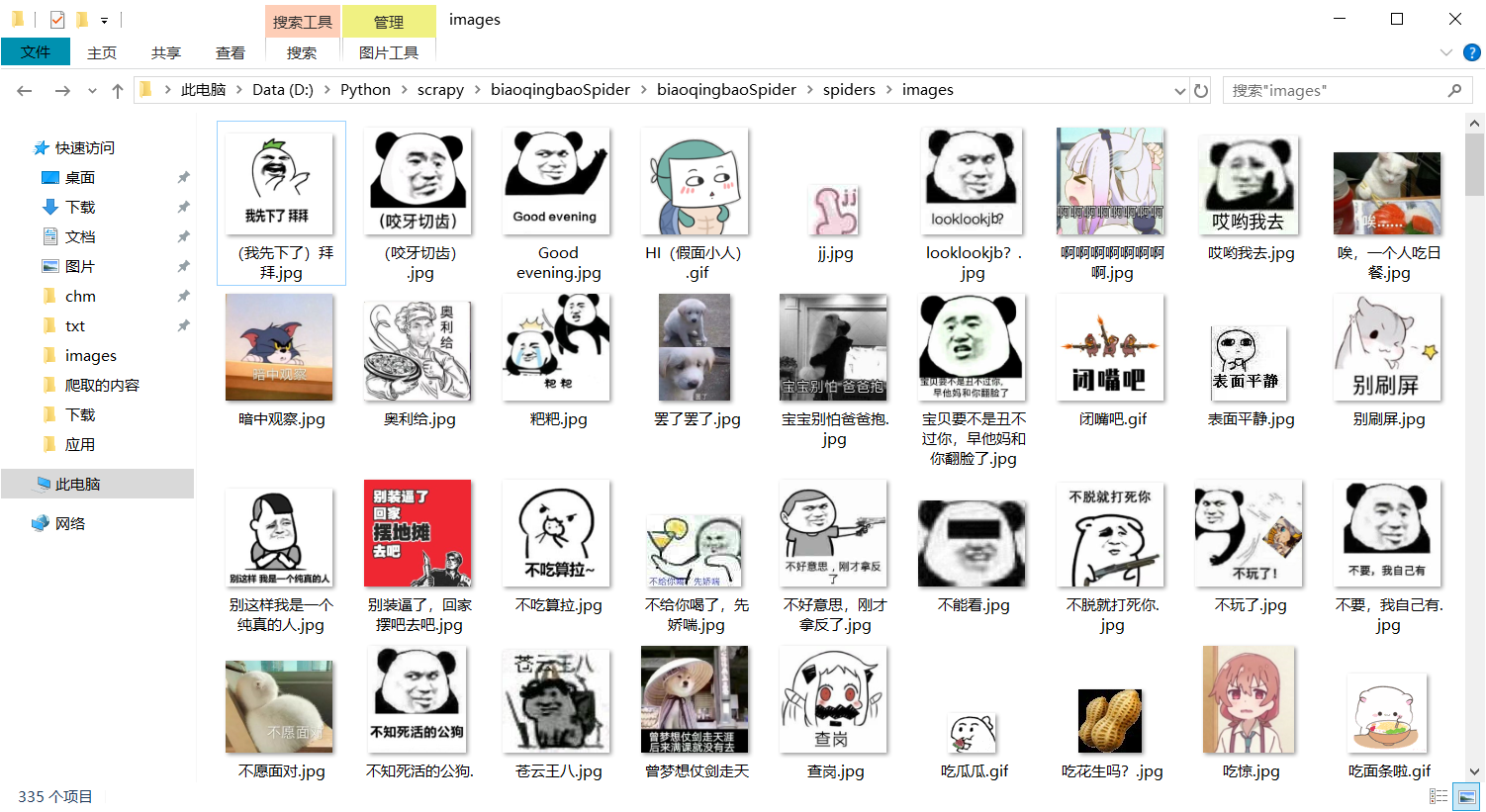
5.结果:
scrapy框架抓取表情包/(python爬虫学习)的更多相关文章
- 利用python scrapy 框架抓取豆瓣小组数据
因为最近在找房子在豆瓣小组-上海租房上找,发现搜索困难,于是想利用爬虫将数据抓取. 顺便熟悉一下Python. 这边有scrapy 入门教程出处:http://www.cnblogs.com/txw1 ...
- scrapy框架简介和基础应用(python爬虫)
一.什么是scrapy? scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍,所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,持久化等)的具有 ...
- Python爬虫学习==>第十章:使用Requests+正则表达式爬取猫眼电影
学习目的: 通过一个一个简单的爬虫应用,初窥门径. 正式步骤 Step1:流程框架 抓取单页内容:利用requests请求目标站点,得到单个页面的html代码,返回结果: 正则表达式分析:根据html ...
- 使用scrapy框架爬取自己的博文(2)
之前写了一篇用scrapy框架爬取自己博文的博客,后来发现对于中文的处理一直有问题- - 显示的时候 [u'python\u4e0b\u722c\u67d0\u4e2a\u7f51\u9875\u76 ...
- tcpdump抓取HTTP包
tcpdump抓取HTTP包 tcpdump -XvvennSs 0 -i eth0 tcp[20:2]=0x4745 or tcp[20:2]=0x4854 0x4745为"GET&quo ...
- 利用Fiddler抓取websocket包
一.利用fiddler抓取websockt包 打开Fiddler,点开菜单栏的Rules,选择Customize Rules... 这时会打开CustomRules.js文件,在class Handl ...
- 使用wireshark抓取TCP包分析1
使用wireshark抓取TCP包分析1 前言 介绍 目的 准备工作 传输 创建连接 握手 生成密钥 发送数据 断开连接 结论 前言 介绍 本篇文章是使用wireshrak对某个https请求的tcp ...
- 【转载】ASP.NET以Post方式抓取远程网页内容类似爬虫功能
使用HttpWebRequest等Http相关类,可以在应用程序中或者网站中模拟浏览器发送Post请求,在请求带入相应的Post参数值,而后请求回远程网页信息.实现这一功能也很简单,主要是依靠Http ...
- 手机通过Charles抓取https包
因为fiddler不能在mac上使用,而Charles是跨平台的,可以在mac上使用,所以需要了解一下Charles的使用 安装破解版Charles 下载破解版包,先启动一次未破解版的Ch ...
随机推荐
- flex弹性布局没有生效
display: -webkit-flex; /* 新版本语法: Chrome 21+ */ display: -webkit-box; /* 老版本语法: Safari, iOS, Android ...
- 微信小程序访问webservice(wsdl)+ axis2发布服务端(Java)
0.主要思路:使用axis2发布webservice服务端,微信小程序作为客户端访问.步骤如下: 1.服务端: 首先微信小程序仅支持访问https的url,且必须是已备案域名.因此前期的服务器端工作需 ...
- Python对文件的读写操作
Python使用open函数来读写文件,open函数的第一个参数是文件名,第二个参数是可选的,有4种常见模式:(1)r 打开一个文件来读数据,这是默认模式:(2)w 打开一个文件来写数据,如果文件已有 ...
- 关于APICloud与DCloud的我的一些看法
最近因为项目需要,研究了一下市场较为流行的四种移动开发平台:Wex5.APPcan.Dcloud.APICloud,Wex5因为界面UI较为老旧,且语法和js有较大出入,APPcan不开源等缘故,主要 ...
- CodeForces - 1007A (思维+双指针)
题意 https://vjudge.net/problem/CodeForces-1007A 对一个序列重排,使得新的数比原来的数大对应的位置个数最多. 思路 举个栗子,比如1 2 2 3 3 3 3 ...
- Ubuntu18.04 安装TensorFlow 和 Keras
TensorFlow和Keras是当前两款主流的深度学习框架,Keras被采纳为TensorFlow的高级API,平时做深度学习任务,可以使用Keras作为深度学习框架,并用TensorFlow作为后 ...
- MATLAB粒子群优化算法(PSO)
MATLAB粒子群优化算法(PSO) 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 一.介绍 粒子群优化算法(Particle Swarm Optim ...
- 9.Java基础_for/while/do-while循环
/* for循环(同C++) 初始化变量的作用域为循环体 出了循环体,初始化的局部变量消失 for(初始化;条件判断;条件控制){ 循环体; } while循环 while(条件判断){ 循环体; } ...
- G1 垃圾收集器架构和如何做到可预测的停顿(阿里)
CMS垃圾回收机制 参考:图解 CMS 垃圾回收机制原理,-阿里面试题 CMS与G1的区别 参考:CMS收集器和G1收集器优缺点 写这篇文章是基于阿里面试官的一个问题:众所周期,G1跟其他的垃圾回收算 ...
- RabbitMQ学习笔记(一、消息中间件基础)
目录: 什么是消息中间件 消息中间件的作用 JMS规范 AMQP协议 RabbitMQ简介 Hello World 什么是消息中间件: 消息中间件(Message Queue Middleware,简 ...