Python爬取《冰雪奇缘2》豆瓣影评
前言
文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 刘铨@CCIS Lab
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
一、分析URL
1、分析豆瓣影评URL
首先在豆瓣中,找到我们想要爬取的电影《冰雪奇缘2》

2、查看影片评论

二、爬取评论
分析网页源码
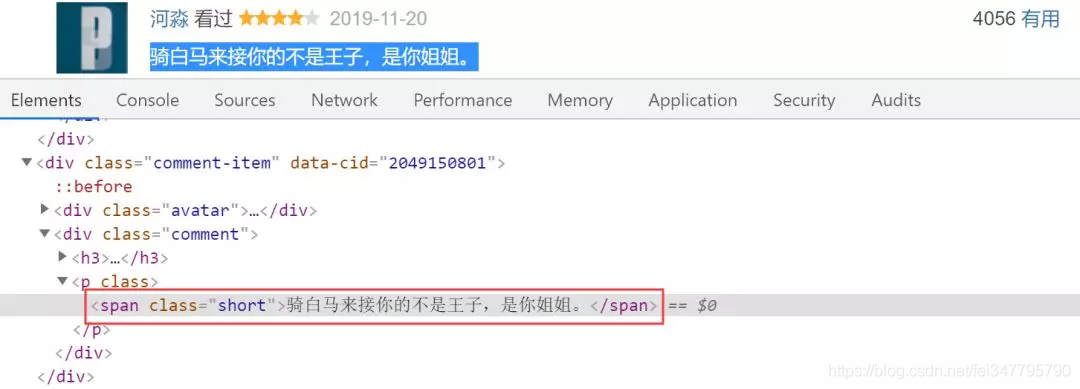
分析源码,可以看到评论在<span class="short">这个标签中,即代码为:
import urllib.request
from bs4 import BeautifulSoup
def getHtml(url):
"""获取url页面"""
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'}
req = urllib.request.Request(url,headers=headers)
req = urllib.request.urlopen(req)
content = req.read().decode('utf-8')
return content
def getComment(url):
"""解析HTML页面"""
html = getHtml(url)
soupComment = BeautifulSoup(html, 'html.parser')
comments = soupComment.findAll('span', 'short')
onePageComments = []
for comment in comments:
onePageComments.append(comment.getText()+'\n')
return onePageComments
if __name__ == '__main__':
f = open('冰雪奇缘2.txt', 'w', encoding='utf-8')
for page in range(10): # 豆瓣爬取多页评论需要验证。
url = 'https://movie.douban.com/subject/25887288/comments?start=' + str(20*page) + '&limit=20&sort=new_score&status=P'
print('第%s页的评论:' % (page+1))
print(url + '\n')
for i in getComment(url):
f.write(i)
print(i)
print('\n')
这里要注意的是,未登录用户只能查看前十页的评论,爬取更多评论需要先模拟登录。
三、进行词云展示
数据抓取下来之后,我们就来使用词云分析一下这部电影:
1、使用结巴分词
因为我们下载的影评是一段一段的文字,而我们做的词云是统计单词出现的次数,所以需要先分词。
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from scipy.misc import imread
import jieba
text = open("冰雪奇缘2.txt","rb").read()
#结巴分词
wordlist = jieba.cut(text,cut_all=False)
wl = " ".join(wordlist)
2、使用词云分析
#设置词云
wc = WordCloud(background_color = "white", #设置背景颜色
mask = imread('black_mask.png'), #设置背景图片
max_words = 2000, #设置最大显示的字数
stopwords = ["的", "这种", "这样", "还是","就是", "这个", "没有" , "一个" , "什么", "电影", "一部","第一部", "第二部"], #设置停用词
font_path = "C:\Windows\Fonts\simkai.ttf", # 设置为楷体 常规
#设置中文字体,使得词云可以显示(词云默认字体是“DroidSansMono.ttf字体库”,不支持中文)
max_font_size = 60, #设置字体最大值
random_state = 30, #设置有多少种随机生成状态,即有多少种配色方案
)
myword = wc.generate(wl)#生成词云
wc.to_file('result.png')
#展示词云图
plt.imshow(myword)
plt.axis("off")
plt.show()
 最终结果:
最终结果:  .
.
Python爬取《冰雪奇缘2》豆瓣影评的更多相关文章
- Python爬取豆瓣《复仇者联盟3》评论并生成乖萌的格鲁特
代码地址如下:http://www.demodashi.com/demo/13257.html 1. 需求说明 本项目基于Python爬虫,爬取豆瓣电影上关于复仇者联盟3的所有影评,并保存至本地文件. ...
- Python爬取豆瓣指定书籍的短评
Python爬取豆瓣指定书籍的短评 #!/usr/bin/python # coding=utf-8 import re import sys import time import random im ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- Python爬虫教程-17-ajax爬取实例(豆瓣电影)
Python爬虫教程-17-ajax爬取实例(豆瓣电影) ajax: 简单的说,就是一段js代码,通过这段代码,可以让页面发送异步的请求,或者向服务器发送一个东西,即和服务器进行交互 对于ajax: ...
- Python爬取豆瓣电影top
Python爬取豆瓣电影top250 下面以四种方法去解析数据,前面三种以插件库来解析,第四种以正则表达式去解析. xpath pyquery beaufifulsoup re 爬取信息:名称 评分 ...
- Python爬取《你好李焕英》豆瓣短评并基于SnowNLP做情感分析
爬取过程在这里: Python爬取你好李焕英豆瓣短评并利用stylecloud制作更酷炫的词云图 本文基于前文爬取生成的douban.txt,基于SnowNLP做情感分析. 依赖库: 豆瓣镜像比较快: ...
- python爬取豆瓣电影Top250(附完整源代码)
初学爬虫,学习一下三方库的使用以及简单静态网页的分析.就跟着视频写了一个爬取豆瓣Top250排行榜的爬虫. 网页分析 我个人感觉写爬虫最重要的就是分析网页,找到网页的规律,找到自己需要内容所在的地方, ...
- python爬取《龙岭迷窟》的数据,看看质量剧情还原度到底怎么样
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:简单 PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行 ...
- python爬取信息到数据库与mysql简单的表操作
python 爬取豆瓣top250并导入到mysql数据库中 import pymysql import requests import re url='https://movie.douban.co ...
- Python 爬取所有51VOA网站的Learn a words文本及mp3音频
Python 爬取所有51VOA网站的Learn a words文本及mp3音频 #!/usr/bin/env python # -*- coding: utf-8 -*- #Python 爬取所有5 ...
随机推荐
- jQuery 源码分析(二十一) DOM操作模块 删除元素 详解
本节说一下DOM操作模块里的删除元素模块,该模块用于删除DOM里的某个节点,也可以理解为将该节点从DOM树中卸载掉,如果该节点有绑定事件,我们可以选择保留或删除这些事件,删除元素的接口有如下三个: e ...
- vuex动态引入store modules
主要解决的问题每次建一个module需要自己去主index.js里面去注册 为了偷懒,也为了避免团队开发时同时对index.js 进行修改引发冲突 所以在index.js中 动态的对子目录和模块进行注 ...
- ASP.NET中的身份验证
身份验证方式windows passport form none授权allow 允许deny 拒绝特殊符号 *代表所有用户 ?代表匿名用户跳转配置<system.web><autho ...
- PAT 1005 Spell It Right 字符串处理
Given a non-negative integer N, your task is to compute the sum of all the digits of N, and output e ...
- oracle产销存的写法
with TEMP as (select sum(MMT.TRANSACTION_QUANTITY) QTY_QC, MMT.INVENTORY_ITEM_ID --,CAH.Legal_Entity ...
- Ionic实现路由ion-tabs
1.导包 <meta name="viewport" content="initial-scale=1, maximum-scale=1, user-scalabl ...
- Angular回顾(1)
一.前端基础 HTML:超文本标记语言,文档排版. DOM:文档对象模型. JS: 脚本语言,解释执行:动态操作DOM,服务器交互,用户交互. CSS:层叠样式表. 二.Angular前提 TypeS ...
- bay——巡检RAC操作.txt
Oracle Cluster Software 包括下列组件:Event Management (EVM)Cluster Synchronization Services (CSS)Cluster R ...
- [Linux] ubuntu环境安装和使用elasticsearch
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -apt-get install ap ...
- Codeforces Round #603 (Div. 2)
传送门 感觉脑子还是转得太慢了QAQ,一些问题老是想得很慢... A. Sweet Problem 签到. Code /* * Author: heyuhhh * Created Time: 2019 ...