基于SkyWalking的分布式跟踪系统 - 环境搭建
前面的几篇文章我们聊了基于Metrics的监控Prometheus,利用Prometheus和Grafana可以全方位监控你的服务器及应用的性能指标,在出现异常时利用Alertmanager告警及时通知运维处理。今天我们聊聊基于Trace的分布式跟踪系统 - SkyWalking
初识SkyWalking
应用场景
随着微服务架构的流行,一些微服务架构下的问题也会越来越突出,比如一个请求会涉及多个服务,而服务本身可能也会依赖其他服务,整个请求路径就构成了一个网状的调用链,而在整个调用链中一旦某个节点发生异常,整个调用链的稳定性就会受到影响,如果没有及时处理很有可能会造成整个系统崩溃。
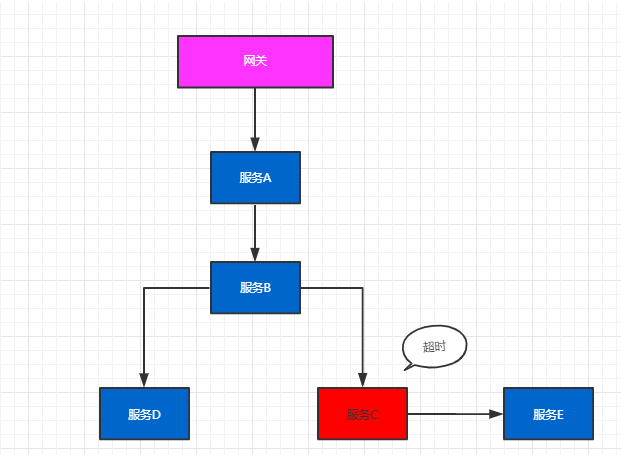
面对以上情况,我们就需要一些可以帮助理解系统行为、用于分析性能问题的工具,以便发生故障的时候,能够快速定位和解决问题。
架构

SkyWalking 逻辑上分为四部分: 探针, 平台后端, 存储和用户界面。
探针
主要负责从客户端收集数据,将数据转换成SkyWalking适用的格式,探针对客户端程序没有任何代码侵入,使用起来简单方便,使用如下命令即可完成对应用的监控
java -javaagent:/path/skywalking-agent.jar -jar youApp.jar平台后端(OAP Server)
主要用于数据聚合, 数据分析以及驱动数据流从探针到用户界面的流程。通过 gRPC/Http 收集客户端Agent的采集信息 ,Http默认端口 12800,gRPC默认端口 11800。存储
SkyWalking支持很多存储:H2(用作演示环境)、MySQL(当数据量大时检索性能下降很厉害)、ES(主流生产级别的存储)用户界面
炫酷的界面,调用请求监控一目了然。
安装配置
安装
直接从官网下载最新的安装包,并上传到服务器解压。解压后的文件如下:
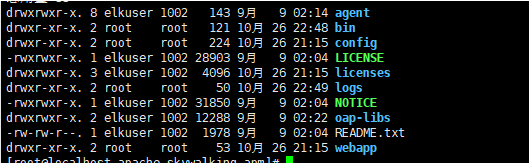
(需要提前准备好JAVA(1.8)和ES(6.x)的环境。)
关注一下几个重要的目录:
- agent:代理模块(探针)
- bin:启动脚本(包括UI和OAP SERVER)
- config:后端相关配置
- webapp:UI界面
配置
- 存储相关配置
打开application.yml,修改storage相关配置。关闭H2,打开ES,然后启动./bin/startup.sh
storage:
elasticsearch:
nameSpace: ${SW_NAMESPACE:"elk-online"}
clusterNodes: ${SW_STORAGE_ES_CLUSTER_NODES:192.168.136.129:9200}
protocol: ${SW_STORAGE_ES_HTTP_PROTOCOL:"http"}
agent 配置
将agent文件夹从服务器上拷贝出来,放在客户端服务器。打开agent\config\agent.config作如下修改agent.service_name修改成你应用名称:blogcollector.backend_service修改成OAP Server地址:192.168.136.129:11800
IDEA配置(可选)
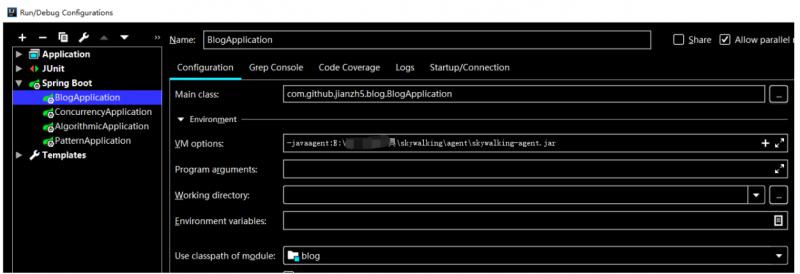
配置完成后启动你的客户端应用。
效果
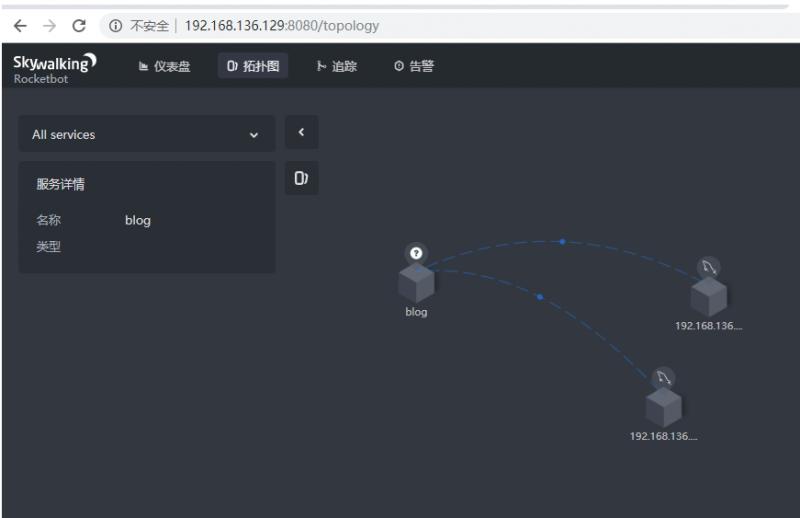
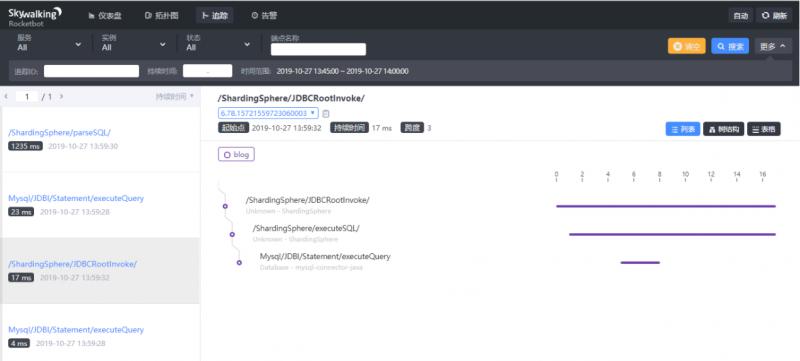
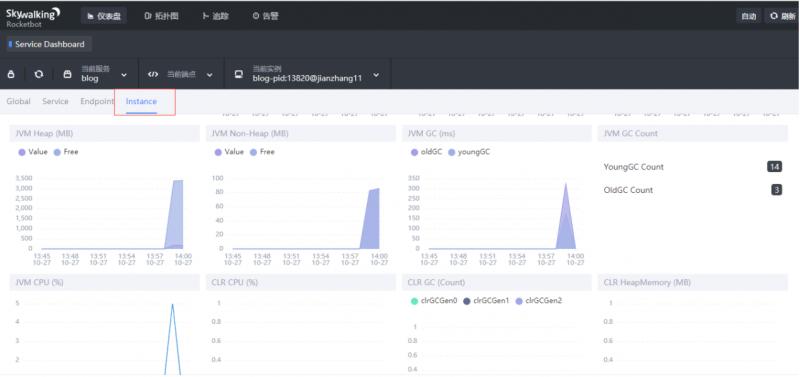
环境搭建好了,下一步就是全面监控你的应用了,咱们下期有缘再见。
三维一体立体化监控
请关注个人公众号:JAVA日知录

基于SkyWalking的分布式跟踪系统 - 环境搭建的更多相关文章
- 基于SkyWalking的分布式跟踪系统 - 微服务监控
上一篇文章我们搭建了基于SkyWalking分布式跟踪环境,今天聊聊使用SkyWalking监控我们的微服务(DUBBO) 服务案例 假设你有个订单微服务,包含以下组件 MySQL数据库分表分库(2台 ...
- 基于SkyWalking的分布式跟踪系统 - 异常告警
通过前面2篇文章我们搭建了SW的基础环境,监控了微服务,能了解所有服务的运行情况.但是当出现服务响应慢,接口耗时严重时我们需要立即定位到问题,这就需要我们今天的主角--监控告警,同时此篇也是SW系列的 ...
- Spring+Shiro搭建基于Redis的分布式权限系统(有实例)
摘要: 简单介绍使用Spring+Shiro搭建基于Redis的分布式权限系统. 这篇主要介绍Shiro如何与redis结合搭建分布式权限系统,至于如何使用和配置Shiro就不多说了.完整实例下载地址 ...
- 微服务之分布式跟踪系统(springboot+zipkin+mysql)
通过上一节<微服务之分布式跟踪系统(springboot+zipkin)>我们简单熟悉了zipkin的使用,但是收集的数据都保存在内存中重启后数据丢失,不过zipkin的Storage除了 ...
- ELK +Nlog 分布式日志系统的搭建 For Windows
前言 我们为啥需要全文搜索 首先,我们来列举一下关系型数据库中的几种模糊查询 MySql : 一般情况下LIKE 模糊查询 SELECT * FROM `LhzxUsers` WHERE UserN ...
- Spark 1.6.1分布式集群环境搭建
一.软件准备 scala-2.11.8.tgz spark-1.6.1-bin-hadoop2.6.tgz 二.Scala 安装 1.master 机器 (1)下载 scala-2.11.8.tgz, ...
- 基于HBase Hadoop 分布式集群环境下的MapReduce程序开发
HBase分布式集群环境搭建成功后,连续4.5天实验客户端Map/Reduce程序开发,这方面的代码网上多得是,写个测试代码非常容易,可是真正运行起来可说是历经挫折.下面就是我最终调通并让程序在集群上 ...
- ZooKeeper 完全分布式集群环境搭建
1. 搭建前准备 示例共三台主机,主机IP映射信息如下: 192.168.32.101 s1 192.168.32.102 s2 192.168.32.103 s3 2.下载ZooKeeper, 以 ...
- Hadoop完全分布式集群环境搭建
1. 在Apache官网下载Hadoop 下载地址:http://hadoop.apache.org/releases.html 选择对应版本的二进制文件进行下载 2.解压配置 以hadoop-2.6 ...
随机推荐
- OAuth2.0 RFC 6749 中文
英文原版:https://tools.ietf.org/html/rfc6749 转自:https://github.com/jeansfish/RFC6749.zh-cn 一.简介 在传统的客户端- ...
- mysql重新设置递增值
alter table table_name AUTO_INCREMENT=value;
- 转:int整数除以int整数一定得到的是int整数(易忽视)
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/u014053368/article/de ...
- 品Spring:SpringBoot和Spring到底有没有本质的不同?
现在的Spring相关开发都是基于SpringBoot的. 最后在打包时可以把所有依赖的jar包都打进去,构成一个独立的可执行的jar包.如下图13: 使用java -jar命令就可以运行这个独立的j ...
- 基于RDD实现简单的WordCount程序
写在前面 因为觉得自己的代码量实在是太少了,所以,想着,每周至少写5个小的demo程序.现在的想法是,写一些Spark,Storm,MapReduce,Flume,kafka等等单独或组合使用的一些小 ...
- ETL-Kettle学习笔记(入门,简介,简单操作)
KETTLE Kettle:简介 ETL:简介 ETL(Extract-Transform-Load的缩写,即数据抽取.转换.装载的过程),对于企业或行业应用来说,我们经常会遇到各种数据的处理,转换, ...
- java异常类的妙用
异常类的妙用 以往在使用异常时,只是知道通过异常类的构造方法设置一些出错信息,此外最多就是把引起该异常的原因通过Throwable类的子类一同设置进去.今天在分析springSecurity3.0 ...
- .NetCore技术研究-.NET Core迁移前的准备工作
前段时间迁移.NET Core做了大量的试水和评估,今天整理一下分享给大家.大致有以下几个部分: 1. .NET Core的由来 2. 为什么要迁移.NET Core 3. .NET Core3.X主 ...
- map转换成com.google.gson.JsonObject
String json =new Gson().toJson(map); JsonObject jsonObject =new JsonParser().parse(json).getAsJsonOb ...
- Java 8 时间日期使用
一.日期时间 Java 8通过发布新的Date-Time API (JSR 310)来进一步加强对日期与时间的处理.java.util.Date和SimpleDateFormatter都不是线程安全的 ...