Web Scraper 翻页——控制链接批量抓取数据

这是简易数据分析系列的第 5 篇文章。
上篇文章我们爬取了豆瓣电影 TOP250 前 25 个电影的数据,今天我们就要在原来的 Web Scraper 配置上做一些小改动,让爬虫把 250 条电影数据全部爬取下来。
前面我们同时说了,爬虫的本质就是找规律,当初这些程序员设计网页时,肯定会依循一些规则,当我们找到规律时,就可以预测他们的行为,达到我们的目的。
今天我们就找找豆瓣网站的规律,想办法抓取全部数据。今天的规律就从常常被人忽略的网址链接开始。
1.链接分析
我们先看看第一页的豆瓣网址链接:
https://movie.douban.com这个很明显就是个豆瓣的电影网址,没啥好说的top250这个一看就是网页的内容,豆瓣排名前 250 的电影,也没啥好说的?后面有个start=0&filter=,根据英语提示来看,好像是说筛选(filter),从 0 开始(start)

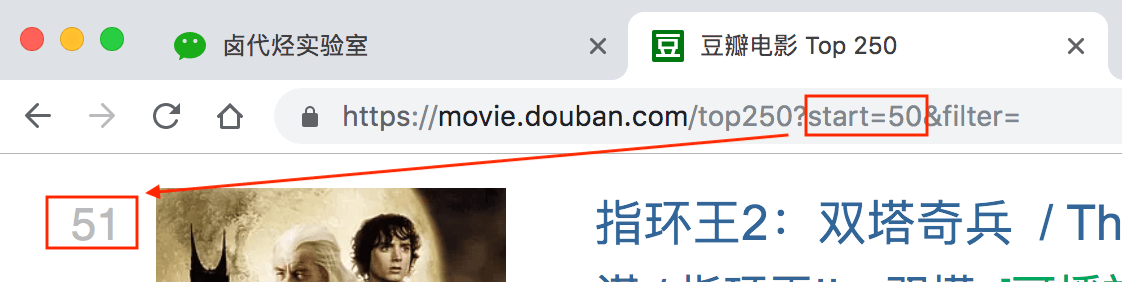
再看看第二页的网址链接,前面都一样,只有后面的参数变了,变成了 start=25,从 25 开始;
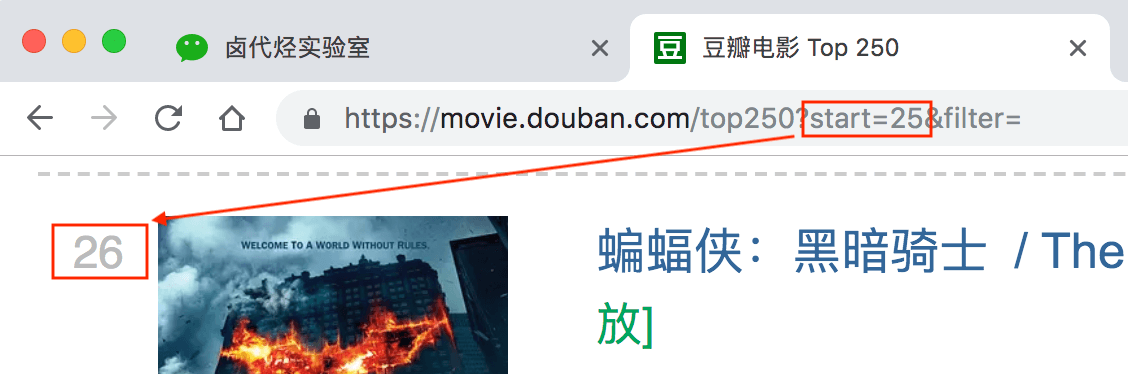
我们再看看第三页的链接,参数变成了 start=50,从 50 开始;
分析 3 个链接我们很容易得出规律:
start=0,表示从排名第 1 的电影算起,展示 1-25 的电影
start=25,表示从排名第 26 的电影算起,展示 26-50 的电影
start=50,表示从排名第 51 的电影算起,展示 51-75 的电影
…...
start=225,表示从排名第 226 的电影算起,展示 226-250 的电影
规律找到了就好办了,只要技术提供支持就行。随着深入学习,你会发现 Web Scraper 的操作并不是难点,最需要思考的其实还是这个找规律。
2.Web Scraper 控制链接参数翻页
Web Scraper 针对这种通过超链接数字分页获取分页数据的网页,提供了非常便捷的操作,那就是范围指定器。
比如说你想抓取的网页链接是这样的:
http://example.com/page/1http://example.com/page/2http://example.com/page/3
你就可以写成 http://example.com/page/[1-3],把链接改成这样,Web Scraper 就会自动抓取这三个网页的内容。
当然,你也可以写成 http://example.com/page/[1-100],这样就可以抓取前 100 个网页。
那么像我们之前分析的豆瓣网页呢?它不是从 1 到 100 递增的,而是 0 -> 25 -> 50 -> 75 这样每隔 25 跳的,这种怎么办?
http://example.com/page/0http://example.com/page/25http://example.com/page/50
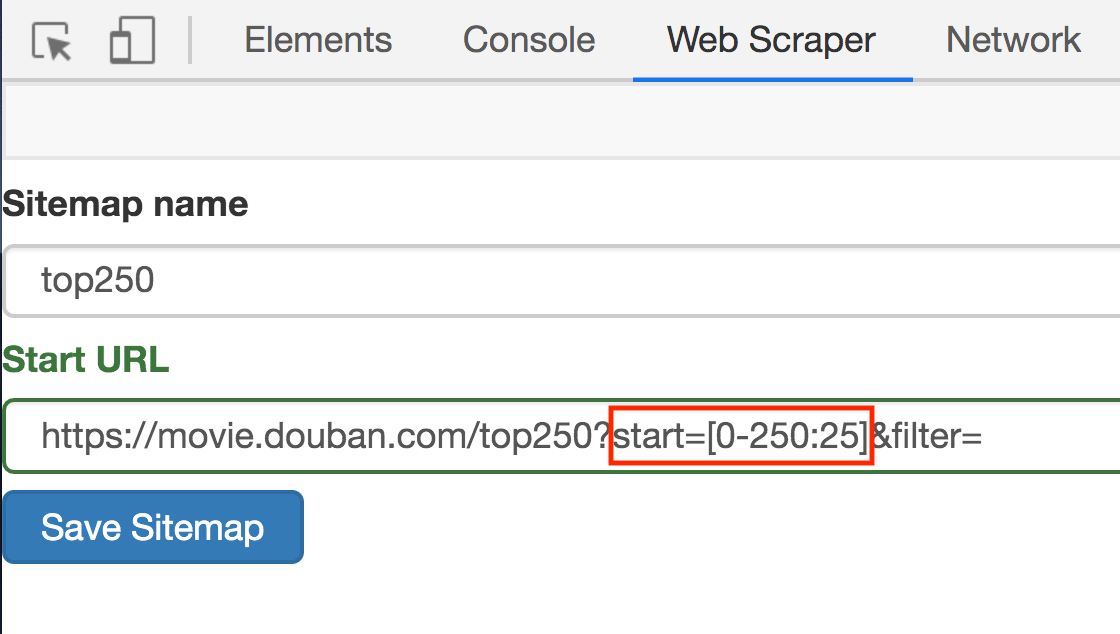
其实也很简单,这种情况可以用 [0-100:25] 表示,每隔 25 是一个网页,100/25=4,爬取前 4 个网页,放在豆瓣电影的情景下,我们只要把链接改成下面的样子就行了;
https://movie.douban.com/top250?start=[0-225:25]&filter=
这样 Web Scraper 就会抓取 TOP250 的所有网页了。
3.抓取数据
解决了链接的问题,接下来就是如何在 Web Scraper 里修改链接了,很简单,就点击两下鼠标:
1.点击 Stiemaps,在新的面板里点击 ID 为 top250 的这列数据;

2.进入新的面板后,找到 Stiemap top250 这个 Tab,点击,再点击下拉菜单里的 Edit metadata;
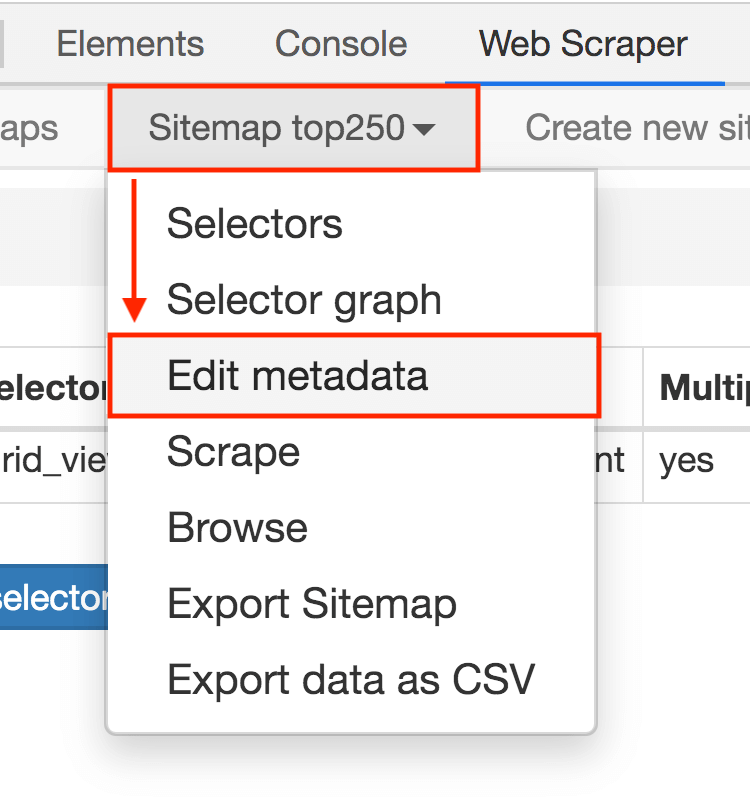
3.修改原来的网址,图中的红框是不同之处:
修改好了超链接,我们重新抓取网页就好了。操作和上文(URL)一样,我这里就简单复述一下:
点击
Sitemap top250下拉菜单里的Scrape按钮新的操作面板的两个输入框都输入 2000
点击
Start scraping蓝色按钮开始抓取数据抓取结束后点击面板上的
refresh蓝色按钮,检测我们抓取的数据
如果你操作到这里并抓取成功的话,你会发现数据是全部抓取下来了,但是顺序都是乱的。
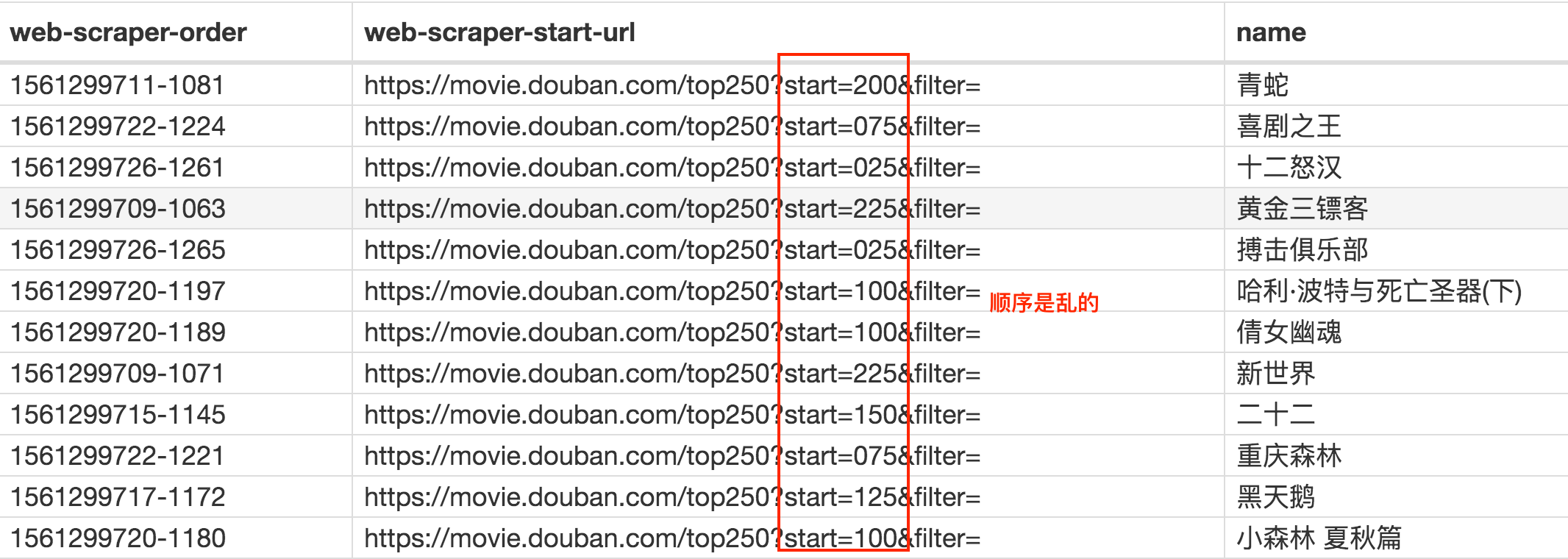
我们这里先不管顺序问题,因为这个属于数据清洗的内容了,我们现在的专题是数据抓取。先把相关的知识点讲完,再攻克下一个知识点,才是更合理的学习方式。
这期讲了通过修改超链接的方式抓取了 250 个电影的名字。下一期我们说一些简单轻松的内容换换脑子,讲讲 Web Scraper 如何导入别人写好的爬虫文件,导出自己写好的爬虫软件。
Web Scraper 翻页——控制链接批量抓取数据的更多相关文章
- Web Scraper 翻页——控制链接批量抓取数据(Web Scraper 高级用法)| 简易数据分析 05
这是简易数据分析系列的第 5 篇文章. 上篇文章我们爬取了豆瓣电影 TOP250 前 25 个电影的数据,今天我们就要在原来的 Web Scraper 配置上做一些小改动,让爬虫把 250 条电影数据 ...
- 简易数据分析 12 | Web Scraper 翻页——抓取分页器翻页的网页
这是简易数据分析系列的第 12 篇文章. 前面几篇文章我们介绍了 Web Scraper 应对各种翻页的解决方法,比如说修改网页链接加载数据.点击"更多按钮"加载数据和下拉自动加载 ...
- 简易数据分析 08 | Web Scraper 翻页——点击「更多按钮」翻页
这是简易数据分析系列的第 8 篇文章. 我们在Web Scraper 翻页--控制链接批量抓取数据一文中,介绍了控制网页链接批量抓取数据的办法. 但是你在预览一些网站时,会发现随着网页的下拉,你需要点 ...
- Web Scraper 翻页——利用 Link 选择器翻页 | 简易数据分析 14
这是简易数据分析系列的第 14 篇文章. 今天我们还来聊聊 Web Scraper 翻页的技巧. 这次的更新是受一位读者启发的,他当时想用 Web scraper 爬取一个分页器分页的网页,却发现我之 ...
- 简易数据分析 10 | Web Scraper 翻页——抓取「滚动加载」类型网页
这是简易数据分析系列的第 10 篇文章. 友情提示:这一篇文章的内容较多,信息量比较大,希望大家学习的时候多看几遍. 我们在刷朋友圈刷微博的时候,总会强调一个『刷』字,因为看动态的时候,当把内容拉到屏 ...
- Web自动化框架LazyUI使用手册(4)--控件抓取工具Elements Extractor详解(批量抓取)
概述 前面的一篇博文详细介绍了单个控件抓取的设计思路&逻辑以及使用方法,本文将详述批量控件抓取功能. 批量抓取:打开一个web页面,遍历页面上所有能被抓取的元素,获得每个元素的iframe.和 ...
- python实现列表页数据的批量抓取练手练手的
python实现列表页数据的批量抓取,练手的,下回带分页的 #!/usr/bin/env python # coding=utf-8 import requests from bs4 import B ...
- web scraper 抓取数据并做简单数据分析
其实 web scraper 说到底就是那点儿东西,所有的网站都是大同小异,但是都还不同.这也是好多同学总是遇到问题的原因.因为没有统一的模板可用,需要理解了 web scraper 的原理并且对目标 ...
- Python3利用BeautifulSoup4批量抓取站点图片的代码
边学边写代码,记录下来.这段代码用于批量抓取主站下所有子网页中符合特定尺寸要求的的图片文件,支持中断. 原理很简单:使用BeautifulSoup4分析网页,获取网页<a/>和<im ...
随机推荐
- wpf datagrid设置右键菜单打开时选中项的背景色
原文:wpf datagrid设置右键菜单打开时选中项的背景色 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/huangli321456/artic ...
- Highcharts纯js图表库,以后可以跟客户说,你跟阿里云ECS用的图表库是同款
Highcharts是一款纯javascript编写的图表库,能够很简便的在Web网站或Web应用中添加交互性的图表,Highcharts目前支持直线图.曲线图.面积图.柱状图.饼图.散点图等多达18 ...
- AR研究-Demo集
原文:AR研究-Demo集 之前研究了图像处理.图像识别及AR 等相关技术,下载了很多开源源码进行学习和尝试引用,包括c++.c#.Opengl.Emgu. Aforge.OpenCV. ...
- ASP.NET Core 配置身份验证
以AspUser的Password为例,去掉最少1个大写字母,1个小写字母等等坑爹的要求在Startup的ConfigureServices中进行配置 services.Configure<Id ...
- 2-21-源码编译安装LAMP
编译安装LAMP所需要及其所使用的源码版本: httpd version:httpd-2.4.16 apr version:apr-1.5.2 pcre version:pcre-8.37 apr ...
- 赵伟国辞去TCL集团董事等职位,紫光参与TCL定增浮盈已超7亿
集微网消息,TCL 集团于8月9日晚间发布公告称,公司董事会于近日收到董事赵伟国先生的书面辞职报告,赵伟国先生因个人原因申请辞去公司董事及公司战略委员会委员职务.辞任后,赵伟国先生不再担任公司任何职务 ...
- SingletonBaseTemplate
public static byte[] writeValueAsZipByte(List<CraneDataDtls> dtls) { ObjectMapper mapper = new ...
- 【C#】解决MouseHook捕获鼠标动作,在有些电脑上SetWindowsHookEx失败返回0的问题
原文:[C#]解决MouseHook捕获鼠标动作,在有些电脑上SetWindowsHookEx失败返回0的问题 最近在debug鼠标位置捕获的功能时发现在其中的一台开发电脑上,SetWindowsHo ...
- 在IE浏览器 使用PHPExcel导出文件时时 文件名中文乱码
1.当我们使用IE内核的浏览器下在PHPExcel报表时(谷歌.火狐浏览器正常, IE浏览器,360浏览器的兼容模式报错),会出现如下错误: 2.解决办法: 在下载文件时,对当前的浏览器进行判断, 如 ...
- win32界面程序开发,自制一个会自动销毁的提示框
思路:创建线程里面启动窗口,设置定时器关闭该窗口. 创建窗口几个步骤和一般窗口无异,注册.然后createwindow,之后showwinodw,然后消息循环. 在createwindow之后,获取到 ...