Elastic search集群新增节点(同一个集群,同一台物理机,基于ES 7.4)
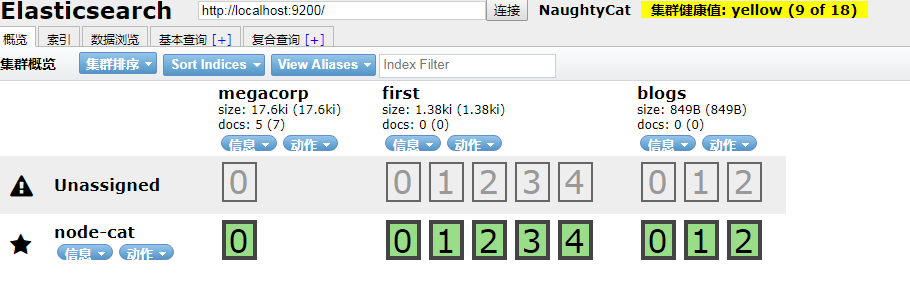
一开始,在电脑上同一个集群新增节点(node)怎么试也不成功,官网guide又语焉不详?集群健康值yellow(表示主分片全部可用,部分复制分片不可用)。关于集群和多节点,有什么好处呢?
集群和多个节点,可以提高可用性,一个挂了,可从另外一个恢复,主节点挂了,会自动从剩余节点选举出一个主节点,并且当恢复主节点时,会自动拷贝主节点失效期间,新的更新数据;同时可以负载均衡,提高吞吐率(在多台物理机布置多个节点和集群的情况下)
最后,在stackoverflow上找到了答案。国内CSDN和博客园的方法都不行,还各种照抄错误答案,真是鄙视国内大部分水货。英语好,太重要。具体解决步骤如下:
- 修改配置文件“elasticsearch.yml”
新增如下信息:
http.port:9200-9299
transport.tcp.port:9300-9399
node.max_local_storage_nodes:2
注:不能在同一个端口上,运行多个节点;并且设置了,本地最多可以存储2个节点
- 启动第一个节点
.\bin\elasticsearch
- 启动第二个节点
.\bin\elasticsearch -Enode.name=NodeTwo -Enode.master=false
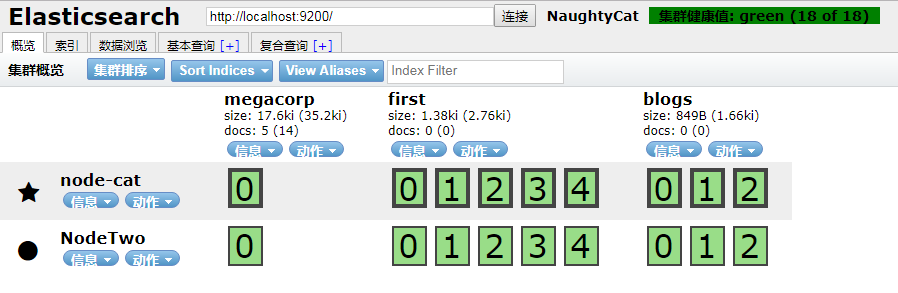
最后,好开心鸭,集群健康值为green(表示主分片和复制分片全部可用;red,则表示部分主分片也不可用)了,附图如下:
附:
1)参考 https://stackoverflow.com/questions/13477303/multiple-nodes-in-elasticsearch/13478781#
2)主节点只能有一个,剩下的作为数据节点 (基于elastic search 7.4实现)
Elastic search集群新增节点(同一个集群,同一台物理机,基于ES 7.4)的更多相关文章
- CDH5.16.1集群新增节点
如果是全新安装集群的话,可以参考<Ubuntu 16.04上搭建CDH5.16.1集群> 下面是集群新增节点步骤: 1.已经存在一个集群,有两个节点 192.168.100.19 hado ...
- redis 集群新增节点,slots槽分配,删除节点, [ERR] Calling MIGRATE ERR Syntax error, try CLIENT (LIST | KILL | GET...
redis reshard 重新分槽(slots) https://github.com/antirez/redis/issues/5029 redis 官方已确认该bug redis 集群重新(re ...
- Spark集群新增节点方法
Spark集群处理能力不足需要扩容,如何在现有spark集群中新增新节点?本文以一个实例介绍如何给Spark集群新增一个节点. 1. 集群环境 现有Spark集群包括3台机器,用户名都是cdahdp, ...
- k8s集群新增节点
节点为centos7.4 一.node节点基本环境配置 1.配置主机名 2.配置hosts文件(master和node相互解析) 3.时间同步 ntpdate pool.ntp.org date ec ...
- 黑群晖NAS安装方法(收集)/物理机/VMware虚拟机/KVM虚拟机(转)
群晖NAS系统的特点: 1.正版的群晖分为两部分,启动引导和系统文件,其中启动引导是一个闪盘,镶嵌在群晖的主板上,而系统文件是现成下载然后倒入的pat文件. 2.黑群晖破解的主要是启动引导,其实能兼容 ...
- redis 集群环境搭建-redis集群管理
集群架构 (1)所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽. (2)节点的fail是通过集群中超过半数的节点检测失效时才生效. (3)客户端与redi ...
- hadoop进阶----hadoop经验(一)-----生产环境hadoop部署在超大内存服务器的虚拟机集群上vs几个内存较小的物理机
生产环境 hadoop部署在超大内存服务器的虚拟机集群上 好 还是 几个内存较小的物理机上好? 虚拟机集群优点 虚拟化会带来一些其他方面的功能. 资源隔离.有些集群是专用的,比如给你三台设备只跑一个 ...
- Elastic Search快速上手(2):将数据存入ES
前言 在上手使用前,需要先了解一些基本的概念. 推荐 可以到 https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.htm ...
- 初识Elastic search—附《Elasticsearch权威指南—官方guide的译文》
本文作为Elastic search系列的开篇之作,简要介绍其简要历史.安装及基本概念和核心模块. 简史 Elastic search基于Lucene(信息检索引擎,ES里一个index—索引,一个索 ...
随机推荐
- more,less,head,tail
当用cat,tac命令查看文件时,文件的所有内容都会被刷出来,因为缓存有限,被刷过去的内容可能就留不住了.用cat查看个小文件还可以,查看大文件时就用到下面的命令. more (选项)(参数) ...
- Eclipse导入别人项目爆红叉
1.导入项目之前,请确认工作空间编码已设置为utf-8:window->Preferences->General->Wrokspace->Text file encoding- ...
- iOS渠道分包2种模式之包内注入文件分包
解决问题:商业模式中会存在这样的形式1款app需要不同的运用团队(工会)去分包推广,谁推广的包下载的人数都会在服务器记录,不同渠道的标示唯一来区分. iOS渠道分包模式有两种 一.IDFA模式 IDF ...
- 【windows】远程桌面 把远程服务器的explorer.exe进程关掉了,咋办?
在操作windows2008R2服务器时不小心把explorer.exe进程关闭了,瞬间整个界面就蓝色了. 重启,做不到,各种快捷键用不了,最后发现Alt+Tab可以用,刚好打开了IIS, 打开其中一 ...
- 大神都在用的yum源
本文原创首发于公众号:编程三分钟 yum 命令的使用 yum命令天天都在用,都快用烂了,但是很多人不知道为什么只要联网,yum命令就能像老奶奶手中的魔法棒一样,随心所欲的下载到想到的包. 比如你想装个 ...
- 深入理解SpringCloud之Gateway
虽然在服务网关有了zuul(在这里是zuul1),其本身还是基于servlet实现的,换言之还是同步阻塞方式的实现.就其本身来讲它的最根本弊端也是再此.而非阻塞带来的好处不言而喻,高效利用线程资源进而 ...
- Python多任务之进程
Process多进程 进程的概念 程序是没有运行的代码,静态的: 进程是运行起来的程序,进程是一个程序运行起来之后和资源的总称: 程序只有一个,但同一份程序可以有多个进程:例如,电脑上多开QQ: 程序 ...
- 禅道部署(基于Linux)
部署步骤: 1. 查看Linux服务器是32位还是64位的 #getconf LONG_BIT 2. 禅道开源版安装包下载 下载站点1:#wget http://sourceforge.net/ ...
- eclipse常用快捷键即项目操作
快捷键: 1.代码提示:Alt+/ 2.撤销上一步操作:Ctrl+z:取消撤销:Ctrl+y: 3.如何注销一整段代码?☞▲第一种注释方法是每行代码前加//:先选中,然后按Ctrl+/:取消注销方法一 ...
- [NOIp2013] luogu P1970 花匠
scy居然开网了. 题目描述 你有一个序列 aaa,你需要保留尽量多的数,使得剩下的数满足以下条件中的一个: ∀x∈[2,n−1]∩N∗\forall x\in[2,n-1]∩\N^*∀x∈[2,n− ...