【并发编程】使用BlockingQueue实现<多生产者,多消费者>
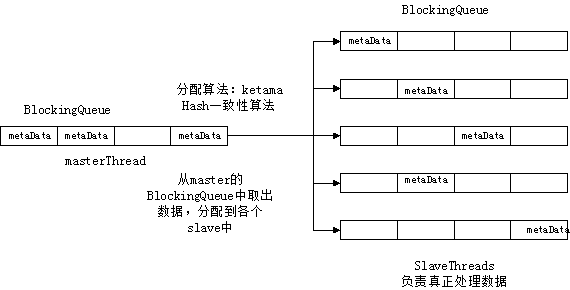
- 持有一个BlockingQueue队列,用于并发接收存储MetaData对象;
- 使用Hash一致性算法ketama,来选择SlaveThread节点;
- 从BlockingQueue队列中,取出MetaData对象,分配给各SlaveThread节点;
- SlaveThread节点负责真正处理MetaData对象;
- 持有一个BlockingQueue队列,用于存储MetaData对象;
- 负责真正处理MetaData对象;
- 假设处理每个MetaData对象需要耗时0.5秒,需要处理500个MetaData对象;
- 若是串行处理,则需要0.5*500=250秒;
- 使用上图所示的master/slave算法,则可以5秒内完成;

MasterThread.java



SlaveThread.java


测试


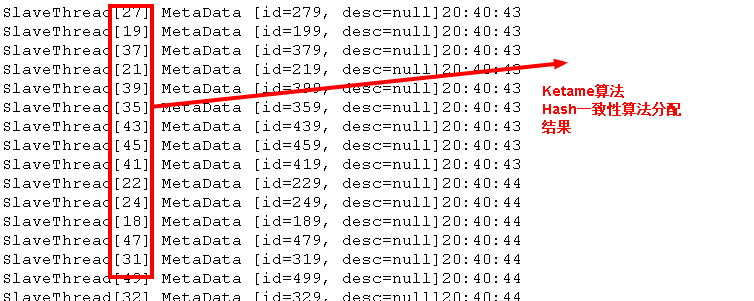

完整程序
package ll.concurrent.BlockingQueue.Ketama;import java.io.UnsupportedEncodingException;import java.security.MessageDigest;import java.security.NoSuchAlgorithmException;public enum HashAlgorithm {KETAMA_HASH;private static final String UTF_8 = "UTF-8";private static final String MD5 = "MD5";public long hash(byte[] digest, int nTime) {long rv = ((long) (digest[3 + nTime * 4] & 0xFF) << 24)| ((long) (digest[2 + nTime * 4] & 0xFF) << 16)| ((long) (digest[1 + nTime * 4] & 0xFF) << 8)| (digest[0 + nTime * 4] & 0xFF);return rv & 0xffffffffL; /* Truncate to 32-bits */}public byte[] computeMd5(String key) {MessageDigest md5;try {md5 = MessageDigest.getInstance(MD5);} catch (NoSuchAlgorithmException e) {throw new RuntimeException("MD5 not supported", e);}md5.reset();byte[] keyBytes = null;try {keyBytes = key.getBytes(UTF_8);} catch (UnsupportedEncodingException e) {throw new RuntimeException("Unknown string :" + key, e);}md5.update(keyBytes);return md5.digest();}}
package ll.concurrent.BlockingQueue.Ketama;import java.util.Collection;import java.util.TreeMap;/*** 一致性Hash算法:是一种分布式算法,常用于负载均衡;** @param <T>*/public final class KetamaNodeLocator<T> {private TreeMap<Long, T> ketamaNodes;private HashAlgorithm hashAlg;private int numReps = 160;public KetamaNodeLocator(Collection<T> nodes) {this(nodes, HashAlgorithm.KETAMA_HASH);}public KetamaNodeLocator(Collection<T> nodes, HashAlgorithm alg) {this(nodes, HashAlgorithm.KETAMA_HASH, 160);}public KetamaNodeLocator(Collection<T> nodes, HashAlgorithm alg,int nodeCopies) {hashAlg = alg;ketamaNodes = new TreeMap<Long, T>();numReps = nodeCopies;for (T node : nodes) {for (int i = 0; i < numReps / 4; i++) {byte[] digest = hashAlg.computeMd5(node.toString() + i);for (int h = 0; h < 4; h++) {long m = hashAlg.hash(digest, h);ketamaNodes.put(m, node);}}}}public T getNode(final String k) {byte[] digest = hashAlg.computeMd5(k);T rv = getNodeForKey(hashAlg.hash(digest, 0));return rv;}T getNodeForKey(long hash) {if (ketamaNodes.isEmpty()) {return null;}if (!ketamaNodes.containsKey(hash)) {Object ceilValue = ((TreeMap<Long, T>) ketamaNodes).ceilingKey(hash);if (ceilValue != null) {try {hash = Long.valueOf(ceilValue.toString());} catch (NumberFormatException e) {e.printStackTrace();hash = 0;}}if (ceilValue == null || hash == 0) {hash = ketamaNodes.firstKey();}}return ketamaNodes.get(hash);}}
package ll.concurrent.BlockingQueue;import java.util.HashMap;import java.util.Map;import java.util.concurrent.BlockingQueue;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.concurrent.LinkedBlockingQueue;import ll.concurrent.BlockingQueue.Ketama.KetamaNodeLocator;/*** <pre>* MasterThread:* 1. 持有一个BlockingQueue队列,用于并发接收存储MetaData对象;* 2. 使用Hash一致性算法ketama来选择SlaveThread节点;* 3. 从BlockingQueue队列中,取出MetaData对象,分配给SlaveThread节点;* 4. SlaveThread节点负责真正处理MetaData对象;** SlaveThread:* 1. 持有一个BlockingQueue队列,用于存储MetaData对象;* 2. 负责真正处理MetaData对象;* </pre>*/public class MasterThread {private static int SLAVE_ENGINE_NUMBER_MAX = 100;private static int _BLOCKSIZE = 5000;private static MasterThread masterThread;private BlockingQueue<MetaData> metaDataQueue;private SlaveEngineThread slaveEngineThread;public static synchronized MasterThread getInstance() {if (masterThread == null) {masterThread = new MasterThread();}return masterThread;}private MasterThread() {metaDataQueue = new LinkedBlockingQueue<MetaData>(_BLOCKSIZE);startSlaveThreadEngine();}private void startSlaveThreadEngine() {slaveEngineThread = new SlaveEngineThread(SLAVE_ENGINE_NUMBER_MAX);slaveEngineThread.start();}public synchronized void put(MetaData object) {if (object == null)return;if (!metaDataQueue.offer(object)) {System.err.println("BlockingQueue is up to max size:"+ metaDataQueue.size());}}private class SlaveEngineThread extends Thread {private ExecutorService executorService;private Map<Integer, SlaveThread> slaveThreadMap;//本示例采用一致性Hash算法,选择SlaveThreadprivate KetamaNodeLocator<Integer> nodeLocator;public SlaveEngineThread(final int nThreads) {slaveThreadMap = new HashMap<Integer, SlaveThread>();// 创建线程池,并发执行SlaveThreadexecutorService = Executors.newFixedThreadPool(nThreads);for (int i = 0; i < nThreads; i++) {SlaveThread command = new SlaveThread(i);executorService.execute(command);slaveThreadMap.put(i, command);}nodeLocator = new KetamaNodeLocator<Integer>(slaveThreadMap.keySet());}@Overridepublic void run() {while (true) {MetaData metaData = null;try {// 堵塞获取metaData = metaDataQueue.take();// 通过hash算法获取slaveThread编号Integer nodeNumber = nodeLocator.getNode(metaData.getId());SlaveThread slaveThread = slaveThreadMap.get(nodeNumber);if (slaveThread != null) {// 将MetaData存入SlaveThread处理slaveThread.put(metaData);}} catch (InterruptedException e) {executorService.shutdown();System.err.println("SlaveEngineThread is Interrupted ... ");break;} catch (Exception e) {System.err.println("failed to handle meta data" + e);}}System.err.println("Master Thread exit...");}}public void exit() {stopSlaveEngineThread();}private void stopSlaveEngineThread() {slaveEngineThread.interrupt();}}
package ll.concurrent.BlockingQueue;import java.text.SimpleDateFormat;import java.util.concurrent.BlockingQueue;import java.util.concurrent.LinkedBlockingQueue;public class SlaveThread implements Runnable {private BlockingQueue<MetaData> msgQueue = new LinkedBlockingQueue<MetaData>(200);private int slaveThreadID;public SlaveThread() {}public SlaveThread(int slaveThreadID) {super();this.slaveThreadID = slaveThreadID;}public void run() {while (true) {MetaData metaData = null;try {// 堵塞获取metaData = msgQueue.take();handleMetaData(metaData);} catch (InterruptedException e) {System.err.println("SlaveThread[" + this.slaveThreadID + "] is Interrupted...");break;} catch (Exception e) {System.err.println("failed to handle meta data" + e);}}System.err.println("SlaveThread[" + this.slaveThreadID + "] exit...");}public void put(MetaData object) {if (object == null)return;if (!msgQueue.offer(object)) {System.err.println("SlaveThread BlockingQueue up to max size");}}private void handleMetaData(MetaData metaData) throws Exception {// 模拟处理,耗时500毫秒Thread.sleep(500);System.out.println("SlaveThread["+ this.slaveThreadID + "] "+ metaData.toString()+ new SimpleDateFormat("HH:mm:ss").format(System.currentTimeMillis()));}}
package ll.concurrent.BlockingQueue;public class MetaData {private String id;private String desc;public MetaData() {super();}public MetaData(String id) {super();this.id = id;}public MetaData(String id, String desc) {super();this.id = id;this.desc = desc;}public String getId() {return id;}public void setId(String id) {this.id = id;}public String getDesc() {return desc;}public void setDesc(String desc) {this.desc = desc;}@Overridepublic String toString() {return "MetaData [id=" + id + ", desc=" + desc + "]";}}
package ll.concurrent.BlockingQueue;import java.text.SimpleDateFormat;public class TestCase {public static void main(String[] args) throws InterruptedException {MasterThread masterThread = MasterThread.getInstance();System.out.println("Start time:"+ new SimpleDateFormat("HH:mm:ss").format(System.currentTimeMillis()));/*** 每个MetaData都需要0.5S的处理时间,如果串行执行,则需要500*0.5=250;* 现采用并行处理,只需要很短的时间即可执行完;*/for (int i = 0; i < 500; i++) {MetaData metaData = new MetaData(i + "");masterThread.put(metaData);}}}
【并发编程】使用BlockingQueue实现<多生产者,多消费者>的更多相关文章
- Java并发编程虚假唤醒问题(生产者和消费者关系)
何为虚假唤醒: 当一个条件满足时,很多线程都被唤醒了,但是只有其中部分是有用的唤醒,其它的唤醒都是无用功:比如买货:如果商品本来没有货物,突然进了一件商品,这是所有的线程都被唤醒了,但是只能一个人买, ...
- 转: 【Java并发编程】之十三:生产者—消费者模型(含代码)
转载请注明出处:http://blog.csdn.net/ns_code/article/details/17249321 生产者消费者问题是线程模型中的经典问题:生产者和消费者在同一时间段内共用同一 ...
- 【Java并发编程】之十三:生产者—消费者模型
生产者消费者问题是线程模型中的经典问题:生产者和消费者在同一时间段内共用同一存储空间,生产者向空间里生产数据,而消费者取走数据. 这里实现如下情况的生产--消费模型: 生产者不断交替地生产两组 ...
- python并发编程-进程间通信-Queue队列使用-生产者消费者模型-线程理论-创建及对象属性方法-线程互斥锁-守护线程-02
目录 进程补充 进程通信前言 Queue队列的基本使用 通过Queue队列实现进程间通信(IPC机制) 生产者消费者模型 以做包子买包子为例实现当包子卖完了停止消费行为 线程 什么是线程 为什么要有线 ...
- 并发编程 06—— CompletionService :Executor 和 BlockingQueue
Java并发编程实践 目录 并发编程 01—— ThreadLocal 并发编程 02—— ConcurrentHashMap 并发编程 03—— 阻塞队列和生产者-消费者模式 并发编程 04—— 闭 ...
- 并发编程 01—— ThreadLocal
Java并发编程实践 目录 并发编程 01—— ThreadLocal 并发编程 02—— ConcurrentHashMap 并发编程 03—— 阻塞队列和生产者-消费者模式 并发编程 04—— 闭 ...
- 并发编程 20—— AbstractQueuedSynchronizer 深入分析
Java并发编程实践 目录 并发编程 01—— ThreadLocal 并发编程 02—— ConcurrentHashMap 并发编程 03—— 阻塞队列和生产者-消费者模式 并发编程 04—— 闭 ...
- 并发编程 02—— ConcurrentHashMap
Java并发编程实践 目录 并发编程 01—— ThreadLocal 并发编程 02—— ConcurrentHashMap 并发编程 03—— 阻塞队列和生产者-消费者模式 并发编程 04—— 闭 ...
- 并发编程 04——闭锁CountDownLatch 与 栅栏CyclicBarrier
Java并发编程实践 目录 并发编程 01—— ThreadLocal 并发编程 02—— ConcurrentHashMap 并发编程 03—— 阻塞队列和生产者-消费者模式 并发编程 04—— 闭 ...
- 并发编程 05—— Callable和Future
Java并发编程实践 目录 并发编程 01—— ThreadLocal 并发编程 02—— ConcurrentHashMap 并发编程 03—— 阻塞队列和生产者-消费者模式 并发编程 04—— 闭 ...
随机推荐
- lesson4-图像分类-小象cv
CNN网络进化:AlexNet->VGG->GoogleNet->ResNet,深度8->19->22->152GoogleNet:Lsplit->trans ...
- HDU 1875:畅通工程再续(最小生成树)
畅通工程再续 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total Sub ...
- HDU2019数列有序!
Problem Description 有n(n<=100)个整数,已经按照从小到大顺序排列好,现在另外给一个整数x,请将该数插入到序列中,并使新的序列仍然有序. Input 输入数据包含多个测 ...
- doc四则运算
import java.io.File; import java.io.FileNotFoundException; import java.io.FileReader; import java.ut ...
- 相对和绝对路径 mkdir cd rm 等命令
1. 绝对路径和相对路径 个人理解: 绝对路径-----即从根目录开始一直到你需要找的文件或目录的路径 (即任何情况下都以根目录为起点) 相对路径------即从当前目录开始一直找到你需要找的 ...
- 《DSP using MATLAB》Problem 7.1
只有春节那么几天才能和家人团聚,看着爸爸妈妈一年比一年老,自己还是一无所有,照顾好自己尚且惭愧,真是悲从中来,又能怎么办呢, 唯有奋发努力,时不我待,多想想怎么赚钱,加油. 代码: function ...
- Windows下安装pymssql
准备用Python接入Sql Server数据库,因此准备用pymssql模块. 安装有点纠结. 64位win10系统,python3.6 步骤: 首先需要配置一下freetds: 在这里下载:htt ...
- 使用Maven插件启动tomcat服务
新建maven web项目,首先保证maven环境OK,maven项目能正常install1.pom.xml文件配置如下: <build> <pluginManagement> ...
- PyMongo 常见问题
PyMongo是线程安全的吗PyMongo是线程安全的,并且为多线程应用提供了内置的连接池 PyMongo是进程安全的吗PyMongo不是进程安全的,如果你在fork()中使用MongoClient实 ...
- 生产环境部署MongoDB副本集(带keyfile安全认证以及用户权限)
本文同步于个人Github博客:https://github.com/johnnian/Blog/issues/8,欢迎留言. 安装软件包:mongodb-linux-x86_64-3.4.1.tgz ...