Tensorf实战第九课(自编码AutoEncoder)
本节我们将了解神经网络进行非监督形式的学习,即autoencoder自编码
假设图片经过神经网络后再输出的过程,我们看作是图片先被压缩然后解压的过程。那么在压缩的时候,原有的图片质量被缩减,解压时用信息量小却包含所有关键信息的文件恢复出原本的图片。
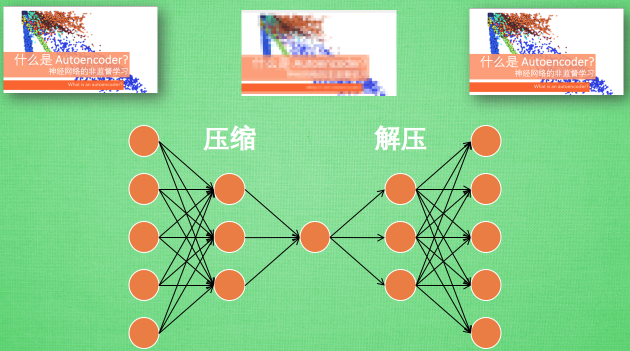
为什么要这么做呢?
因为当神经网络接收大量信息时,神经网络在成千上万个信息源中学习是一件比较吃力的事。所以进行压缩,从原图片中提取最具代表性的信息,减小输入信息量,再把缩减过后的信息放进神经网络学习,这样学习起来简单轻松许多。
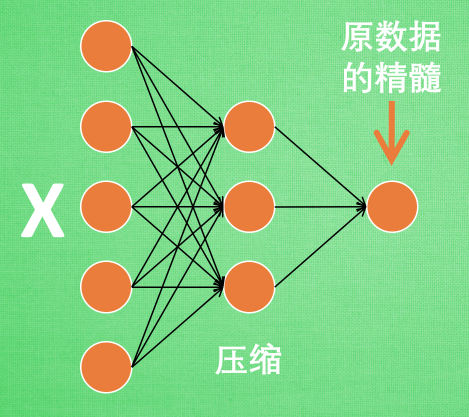
如下图所示,将原数据白色的X压缩,解压还原成黑色的X,求出预测误差,进行反向传递,逐步提升自编码的准确性。训练好的自编码中间一部分就是能够总结原数据的精髓。可以看出,从头到尾,我么值用到看输入数据X,并没有用到X对应的数据标签,所以可以说自编码是一种非监督学习。到了真正使用自编码的时候,通常只会用到自编码的前半部分。

如下图,这部分也叫作encoder编码器,编码器能得到元数据的精髓我们只需要创建一个小的神经网络学习这个精髓的数据,不仅能减少神经网络的负担,同样能达到很好的效果。
至于Decoder解码器,解压器在训练的时候是要将精髓信息解压成原始信息,那么这就提供了一个解压器的作用,甚至我们可以认为是一个生成器。做这件事的一种特殊编码叫做variational autoencoders,其例子就是让它能模仿生成手写数字。

-----------------------------------------------------------------------
自编码 Autoencoder (非监督学习)
我们会首先通过Feature的压缩并解压,将结果与原始数据进行对比,观察处理后的数据是不是如逾期跟原始数据很相像。(这里会用到MNIST数据)
然后我们只看Encoder压缩过程,使用它将一个数据集压缩到只有两个Feature时,将数据放入一个二维坐标系内,特征压缩的效果如下(同样颜色的点,代表分到同一类的数据):

Autoencoder
采用的数据依然是MNIST手写数据集
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt #import mnist data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/",one_hot=False)
参数
# Parameter
learning_rate = 0.01
training_epochs = 5 # 五组训练
batch_size = 256
display_step = 1
examples_to_show = 10
MNIST数据,每张图片的大小是28*28pix,即784Features:
# Network Parameters
n_input = 784 # MNIST data input (img shape: 28*28)
- 在压缩环节,我们要把这个feature不断压缩,经过第一个隐藏层压缩至256个features,在经过第二个隐藏层压缩至128个。
- 在解压环节:我们将128个features还原至256个,在经过一步还原至784个
- 在对比环节:比较原始数据与还原后的拥有的784个features的数据进行cost的对比,跟据cost来提升我们的autoencoder的准确率,下面是两个隐藏层的weights和biases的定义:
# hidden layer settings
n_hidden_1 = 256 # 1st layer num features
n_hidden_2 = 128 # 2nd layer num features
weights = {
'encoder_h1':tf.Variable(tf.random_normal([n_input,n_hidden_1])),
'encoder_h2': tf.Variable(tf.random_normal([n_hidden_1,n_hidden_2])),
'decoder_h1': tf.Variable(tf.random_normal([n_hidden_2,n_hidden_1])),
'decoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_input])),
}
biases = {
'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'decoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'decoder_b2': tf.Variable(tf.random_normal([n_input])),
}
接下来定义的是Encoder和Decoder,使用的Activation function是sigmoid,压缩后的值应该在[0,1]这个范围内。在decoder过程中,通常使用对应于encoder的Activation function:
# Building the encoder
def encoder(x):
# Encoder Hidden layer with sigmoid activation #1
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']),
biases['encoder_b1']))
# Decoder Hidden layer with sigmoid activation #2
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']),
biases['encoder_b2']))
return layer_2 # Building the decoder
def decoder(x):
# Encoder Hidden layer with sigmoid activation #1
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']),
biases['decoder_b1']))
# Decoder Hidden layer with sigmoid activation #2
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']),
biases['decoder_b2']))
return layer_2
实现Encoder和Decoder输出结果:
# Construct model
encoder_op = encoder(X) # 128 Features
decoder_op = decoder(encoder_op) # 784 Features # Prediction
y_pred = decoder_op # After
# Targets (Labels) are the input data.
y_true = X # Before
在通过我们得监督学习进行对照,对“原始的784 features的数据集”和“通过‘prediction’得出的有784features的数据集”进行最小二乘法的计算,并且使cost最小化:
# Define loss and optimizer, minimize the squared error
cost = tf.reduce_mean(tf.pow(y_true - y_pred, 2))
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost)
最后,通过Matploylib的pyplot模块将结果显示出来,注意在输出时MNIST数据集经过压缩之后x的最大值是1,而不是255:
#launch the graph
with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
total_batch = int(mnist.train.num_examples/batch_size)
# Training cycle
for epoch in range(training_epochs):
# Loop over all batches
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size) # max(x) = 1, min(x) = 0
# Run optimization op (backprop) and cost op (to get loss value)
_, c = sess.run([optimizer, cost], feed_dict={X: batch_xs})
# Display logs per epoch step
if epoch % display_step == 0:
print("Epoch:", '%04d' % (epoch+1),
"cost=", "{:.9f}".format(c)) print("Optimization Finished!") # # Applying encode and decode over test set
encode_decode = sess.run(
y_pred, feed_dict={X: mnist.test.images[:examples_to_show]})
# Compare original images with their reconstructions
f, a = plt.subplots(2, 10, figsize=(10, 2))
for i in range(examples_to_show):
a[0][i].imshow(np.reshape(mnist.test.images[i], (28, 28)))
a[1][i].imshow(np.reshape(encode_decode[i], (28, 28)))
plt.show()
完整代码如下:
#autoencoder import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt #import mnist data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/",one_hot=False) #Visualize decoder setting /可视化解码器
#parameters /参数
learning_rate = 0.01
training_epochs = 20 #五组训练
batch_size = 256
display_step = 1
examples_to_show = 10 #network parameters
n_input = 784 #mnist data input(img shape:28*28) #tf Graph input(only picture)
X = tf.placeholder("float",[None,n_input]) #hideen layer setting
n_hidden_1 = 256 #1st layer num features
n_hidden_2 = 128 #2nd layer num features
weights = {
'encoder_h1':tf.Variable(tf.random_normal([n_input,n_hidden_1])),
'encoder_h2':tf.Variable(tf.random_normal([n_hidden_1,n_hidden_2])),
'decoder_h1':tf.Variable(tf.random_normal([n_hidden_2,n_hidden_1])),
'decoder_h2':tf.Variable(tf.random_normal([n_hidden_1,n_input])), }
biases = {
'encoder_b1':tf.Variable(tf.random_normal([n_hidden_1])),
'encoder_b2':tf.Variable(tf.random_normal([n_hidden_2])),
'decoder_b1':tf.Variable(tf.random_normal([n_hidden_1])),
'decoder_b2':tf.Variable(tf.random_normal([n_input])), } #building the encoder
def encoder(x):
#encoder hidden layer with sigmoid activation #1
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x,weights['encoder_h1']),
biases['encoder_b1']))
#decoder hidden layer with sigmoid activation #2
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1,weights['encoder_h2']),
biases['encoder_b2']))
return layer_2 #building the decoder
def decoder(x):
#encoder hidden layer with sigmoid activation #1
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x,weights['decoder_h1']),
biases['decoder_b1']))
#decoder hidden layer with sigmoid activation #2
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1,weights['decoder_h2']),
biases['decoder_b2']))
return layer_2 #construct model
encoder_op = encoder(X)
decoder_op = decoder(encoder_op) #prediction
y_pred = decoder_op
#targets(labels) are the input data
y_true = X #define loss and optimizer ,minize the squared error
cost = tf.reduce_mean(tf.pow(y_true-y_pred,2))
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost) #launch the graph
with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
total_batch = int(mnist.train.num_examples/batch_size)
# Training cycle
for epoch in range(training_epochs):
# Loop over all batches
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size) # max(x) = 1, min(x) = 0
# Run optimization op (backprop) and cost op (to get loss value)
_, c = sess.run([optimizer, cost], feed_dict={X: batch_xs})
# Display logs per epoch step
if epoch % display_step == 0:
print("Epoch:", '%04d' % (epoch+1),
"cost=", "{:.9f}".format(c)) print("Optimization Finished!") # # Applying encode and decode over test set
encode_decode = sess.run(
y_pred, feed_dict={X: mnist.test.images[:examples_to_show]})
# Compare original images with their reconstructions
f, a = plt.subplots(2, 10, figsize=(10, 2))
for i in range(examples_to_show):
a[0][i].imshow(np.reshape(mnist.test.images[i], (28, 28)))
a[1][i].imshow(np.reshape(encode_decode[i], (28, 28)))
plt.show()
通过20个epoch的训练,我们的结果如下所示:

Tensorf实战第九课(自编码AutoEncoder)的更多相关文章
- 9.windows-oracle实战第九课--plsql
一.oracle的pl/sql的概念 pl/sql是oracle在标准的sql语言上的扩展,不仅允许嵌入sql,还允许定义变量和常量,允许使用条件语句和循环语句,允许使用例外处理各种错误,这样使得它的 ...
- 【C语言探索之旅】 第二部分第九课: 实战"悬挂小人"游戏 答案
内容简介 1.课程大纲 2.第二部分第九课: 实战"悬挂小人"游戏 答案 3.第二部分第十课预告: 安全的文本输入 课程大纲 我们的课程分为四大部分,每一个部分结束后都会有练习题, ...
- 【C语言探索之旅】 第一部分第九课:函数
内容简介 1.课程大纲 2.第一部分第九课:函数 3.第一部分第十课预告: 练习题+习作 课程大纲 我们的课程分为四大部分,每一个部分结束后都会有练习题,并会公布答案.还会带大家用C语言编写三个游戏. ...
- NeHe OpenGL教程 第九课:移动图像
转自[翻译]NeHe OpenGL 教程 前言 声明,此 NeHe OpenGL教程系列文章由51博客yarin翻译(2010-08-19),本博客为转载并稍加整理与修改.对NeHe的OpenGL管线 ...
- Python第九课学习
Python第九课学习 数据结构: 深浅拷贝 集合set 函数: 概念 创建 参数 return 定义域 www.cnblogs.com/yuanchenqi/articles/5782764.htm ...
- Pytorch中的自编码(autoencoder)
Pytorch中的自编码(autoencoder) 本文资料来源:https://www.bilibili.com/video/av15997678/?p=25 什么是自编码 先压缩原数据.提取出最有 ...
- Elasticsearch7.X 入门学习第九课笔记-----聚合分析Aggregation
原文:Elasticsearch7.X 入门学习第九课笔记-----聚合分析Aggregation 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. ...
- kubebuilder实战之五:operator编码
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- 如何用three.js搭建处理3D园区、3D楼层、3D机房管线(机房升级版)-第九课(二)
接着上一篇文章,<如何用webgl(three.js)搭建处理3D园区.3D楼层.3D机房管线问题(机房升级版)-第九课(一)> 继续讲解关于三维数据中心管线可视化的解决方案. 上一篇我们 ...
随机推荐
- JAVA之StringUtils工具类
StringUtils 方法的操作对象是 java.lang.String 类型的对象,是对 JDK 提供的 String 类型操作方法的补充,并且是 null 安全的(即如果输入参数 String ...
- windows安装解压版postgresql
1.postgresql解压版下载 2.将下载的postgresql-12.1-1-windows-x64-binaries.zip解压 data文件夹后面初始化数据库时手动创建的 3.初始化数据库 ...
- P1427 小鱼的数字游戏
输入格式: 一行内输入一串整数,以0结束,以空格间隔. 输出格式: 一行内倒着输出这一串整数,以空格间隔. 直接上代码: #include<iostream> using namespac ...
- Maven-项目管理(一)_认识Maven
Maven是什么? Maven是Apache下的项目管理工具,它由纯Java语言开发,可以帮助我们更方便的管理和构建Java项目. 为什么要使用Maven? 1. jar包管理: a) 从Maven中 ...
- Spring Boot 线程池的使用和扩展 - 转载
转载:http://blog.csdn.net/boling_cavalry/article/details/79120268 1.实战环境 windowns10: jdk1.8: springboo ...
- Java-AESUtil
在线版 http://tool.chacuo.net/cryptaes 要使用 AES/CBC/PKCS7Padding 模式需要添加依赖 <!--AES/CBC/PKCS7Padding--& ...
- airflow当触发具有多层subDAG的任务的时候,出现[Duplicate entry ‘xxxx’ for key dag_id]的错误的问题处理
当触发一个具有多层subDAG的任务时,会发现执行触发的task任务运行失败,但是需要触发的目标DAG已经在运行了,dag log 错误内容: [2019-11-21 17:47:56,825] {b ...
- 如何查看 SELinux状态及关闭SELinux
查看SELinux状态: 1./usr/sbin/sestatus -v ##如果SELinux status参数为enabled即为开启状态 SELinux status: ...
- LC 712. Minimum ASCII Delete Sum for Two Strings
Given two strings s1, s2, find the lowest ASCII sum of deleted characters to make two strings equal. ...
- 综合开源框架之RxJava/RxAndroid
* 一种帮助做异步的框架. 类似于 AsyncTask. 但其灵活性和扩展性远远强于前者. * 主页: https://github.com/ReactiveX/RxJava * 中文资料: * ht ...