推荐系统之基于二部图的个性化推荐系统原理及C++实现
1.引言
许多网站都喜欢让用户点击“喜欢/不喜欢”,“顶/反对”,也正是这种很简单的信息也可以利用起来对用户进行推荐!这里介绍一种基于网络结构的推荐系统!
由于推荐系统深深植根于互联网,用户与用户之间,商品与商品之间,用户与商品之间都存在某种联系,把用户和商品都看作节点,他(它)们之间的联系看作是边,那么就很自然地构建出一个网络图,所以很多研究者利用这个网络图进行个性化推荐,取得了不错的效果!
2.二部图
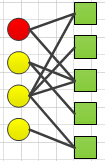
上面就是一个二部图:分为连个部分,圆圈代表的节点为一部分,方块代表的节点为另一部分,二部图的特点:边只存在与不同类之间,同一部分之间的节点之间不存在边连接,正如上图所示,圆圈与圆圈之间没有边,方块与方块之间也没有边,边只存在于圆圈与方块之间.
3.概率传播(probability spreading,ProbS)
本文要实现的基于二部图的推荐系统利用了一种叫做概率传播的机制,这里做一个介绍:
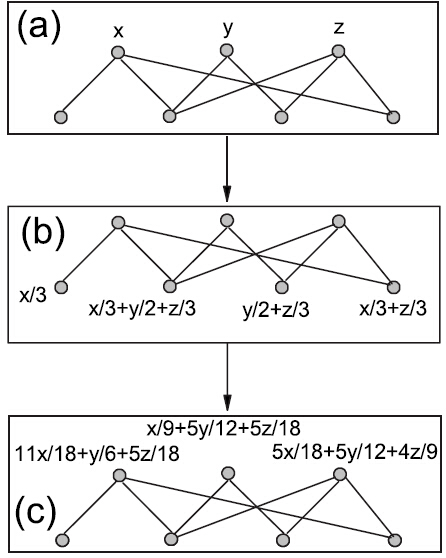
在(a)中,对上面的一部分节点分配初始资源x, y, z, 在(b)中资源以等概率传播的方式,从上面的节点传递给下面的节点,所谓等概率传播,就是每一节点的资源平均传递给它的每一个与它存在边联系的节点,在(c)中资源又以等概率传播的方式传回到上面的节点,可以看出原来三个节点的资源由x, y, z变为11x/18+y/6+5z/18, x/9+5y/12+5z/18, 5x/18+5y/12+4z/9,这样传播的目的是什么呢?
我们知道在二部图中,同一部分节点之间是没有边连接的,那么同一部分之间节点之间的关系就没法直接找到,通过这种二步传播的方式之后,每一个节点的资源都混合有其他节点的资源,把上面三个节点从左到右分别记为A, B, C,A包含了1/6来自于B节点的资源,还包含了5/18来自于C节点的资源,很显然对于A 节点而言, C节点要比B节点重要一些,所以就利用传播后的这些系数来表示同一部分节点之间的关系权重,我们用x', y', z'来表示第二次传播后的资源,则有:
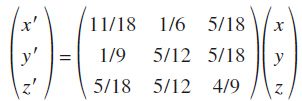
上面的数值矩阵就是节点之间的关系权重矩阵,例如A节点对B节点之间的关系权重为1/6,注意这是一个非对称的:B节点对A节点的关系权重为1/9,怎么理解呢?可以理解为你把一个妹子看作是女神,但是这个妹子心中的Mr Right很可能是另外一个人,这种关系是不对等的. 也正是隐藏的这种不对等关系,正好有利于个性化推荐.
3.利用ProbS产生推荐
还是对未评价过的商品进行预测评分,把评分较高的若干商品推荐给目标用户:
还是以上面的二部图为例,把上面的3个节点看作是商品节点,从左到右分别记作A, B, C,下面的4个节点看作是用户,从左到右分别记作U1, U2, U3, U4, 存在边连接的用户和商品,表示对应的用户喜欢该商品。那么这个二部图用邻接矩阵可以表示为:
| A | B | C | |
| U1 | 1 | 0 | 0 |
| U2 | 1 | 1 | 1 |
| U3 | 0 | 1 | 1 |
| U4 | 1 | 0 | 1 |
现在我们想预测U3对A商品的喜欢程度会如何,已知U3喜欢商品B和C,写出上面推导出的关系权重矩阵:
由此可以知道A商品与B, C商品的关系权重分别为1/6, 5/18,那么预测喜欢程度:
1*1/6 + 1*5/18 = 4/9,
如果有更多未知喜欢程度的商品,都是以这种方式:根据用户已经喜欢的商品与未知喜欢程度商品之间的关系权重来预测这个用户对要预测商品的喜欢程度的评分,根据评分高低,优先向用户推荐高分商品!
关于更多详细的介绍请参考:Bipartite_network_projection_and_personal_recommendation.pdf
4.C++实现
由于程序没有优化,在较大数据上运行较慢,所以这里自己随便造了一个数据集,对其为0的地方进行评分预测,但是由于没有测试集,所以就没有测命中率,有兴趣的读者可以自己优化一下程序,然后在movielens.rar数据上运行并测试命中率,这里主要注重原理,如果有读者根据此原理编出更高效得代码欢迎与我交流,多谢!
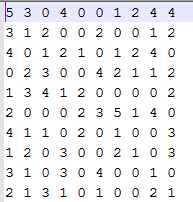
由于该数据集是1-5的评分数据,在程序读取的时候将其处理为喜欢/不喜欢(1/0)的数据集:评分大于等于3的视为喜欢,置为1,否则置为0.
#include <iostream>
#include <fstream>
#include <vector>
#include <string>
#include <vector>
#include <algorithm>
#include <iomanip>
using namespace std; //从TXT中读入数据到矩阵(二维数组)
template <typename T>
vector<vector<T> > txtRead(string FilePath,int row,int col)
{
ifstream input(FilePath);
if (!input.is_open())
{
cerr << "File is not existing, check the path: \n" << FilePath << endl;
exit();
}
vector<vector<T> > data(row, vector<T>(col,));
for (int i = ; i < row; ++i)
{
for (int j = ; j < col; ++j)
{
//因为这里针对的情况是用户只给出对items的喜欢与不喜欢的情况,而movielens
//是一个1-5的评分数据,所以把分数达到3的看作是喜欢,标记为1,小于3的视为
// 不喜欢,置为0
input >> data[i][j];
if (data[i][j] >= )
data[i][j] = ;
else
data[i][j] = ;
}
}
return data;
} //把矩阵中的数据写入TXT文件
template<typename T>
void txtWrite(vector<vector<T> > Matrix, string dest)
{
ofstream output(dest);
vector<vector<T> >::size_type row = Matrix.size();
vector<T>::size_type col = Matrix[].size();
for (vector<vector<T> >::size_type i = ; i < row; ++i)
{
for (vector<T>::size_type j = ; j < col; ++j)
{ output << setprecision()<< Matrix[i][j] << "\t";
}
output << endl;
}
} // 求两个向量的内积
double InnerProduct(std::vector<double> A, std::vector<double> B)
{
double res = ;
for(std::vector<double>::size_type i = ; i < A.size(); ++i)
{
res += A[i] * B[i];
}
return res;
} //矩阵转置操作
template<typename T>//
vector<vector<T> > Transpose(vector<vector<T> > Matrix)
{
unsigned row = Matrix.size();
unsigned col = Matrix[].size();
vector<vector<T> > Trans(col,vector<T>(row,));
for (unsigned i = ; i < col; ++i)
{
for (unsigned j = ; j < row; ++j)
{
Trans[i][j] = Matrix[j][i];
}
}
return Trans;
} //求一个向量中所有元素的和
template<typename T>
T SumVector(vector<T> vec)
{
T res = ; for (vector<T>::size_type i = ; i < vec.size(); ++i)
res += vec[i];
return res;
} //对一个向量中的元素进行降序排列,返回重排后的元素在原来
//向量中的索引
bool IsBigger(double a, double b)
{
return a >= b;
}
vector<unsigned> DescendVector(vector<double> vec)
{
vector<double> tmpVec = vec;
sort(tmpVec.begin(), tmpVec.end(), IsBigger);
vector<unsigned> idx;
for (vector<double>::size_type i = ; i < tmpVec.size(); ++i)
{
for (vector<double>::size_type j = ; j < vec.size(); ++j)
{
if (tmpVec[i] == vec[j])
idx.push_back(j);
}
}
return idx;
} //基于概率传播(ProbS)的二部图的推荐函数,data是训练数据
vector<vector<double> > ProbS(vector<vector<double> > data)
{
auto row = data.size();
auto col = data[].size();
vector<vector<double> > transData = Transpose(data); //第一步利用概率传播机制计算权重矩阵
vector<vector<double> > weights(col, vector<double>(col, ));
for (vector<double>::size_type i = ; i < col; ++i)
{
for (vector<double>::size_type j = ; j < col; ++j)
{
double degree = SumVector<double>(transData[j]);
double sum = ;
for (vector<double>::size_type k = ; k < row; ++k)
{
sum += transData[i][k] * transData[j][k] / SumVector<double>(data[k]);
}
if (degree)
weights[i][j] = sum / degree;
}
} //第二步利用权重矩阵和训练数据集针对每个用户对每一个item评分
vector<vector<double> > scores(row, vector<double>(col, ));
for (vector<double>::size_type i = ; i < row; ++i)
{
for (vector<double>::size_type j = ; j < col; ++j)
{
//等于0的地方代表user i 还木有评价过item j,需要预测
if ( == data[i][j])
scores[i][j] = InnerProduct(weights[j],data[i]);
}
}
return scores;
} //计算推荐结果的命中率:推荐的items中用户确实喜欢的items数量/推荐的items数量
//用户确实喜欢的items是由测试集给出,length表示推荐列表最长为多少,这里将测出
//推荐列表长度由1已知增加到length过程中,推荐命中率的变化
vector<vector<double> > ComputeHitRate(vector<vector<double> > scores, vector<vector<double> > test,
unsigned length)
{
auto usersNum = test.size();
auto itemsNum = test[].size(); vector<vector<unsigned> > sortedIndex;
//因为只是对测试集中的用户和items进行测试,于是选取与测试集大小一样的预测数据
vector<vector<double> > selectedScores(usersNum, vector<double>(itemsNum,));
vector<double> line;
for (unsigned i = ; i < usersNum; ++i)
{
for (unsigned j = ; j < itemsNum; ++j)
{
line.push_back(scores[i][j]);
}
sortedIndex.push_back(DescendVector(line));
line.clear();
}
//hitRate的第一列存储推荐列表的长度,第二列存储对应的命中率
vector<vector<double> > hitRate(length);
for (unsigned k = ; k <= length; ++k)
{
hitRate[k-].push_back(k);
double Counter = ;
for (unsigned i = ; i < usersNum; ++i)
{
for (unsigned j = ; j < k; ++j)
{
unsigned itemIndex = sortedIndex[i][j];
if (test[i][itemIndex])
++Counter;
}
}
hitRate[k-].push_back(Counter / (k * usersNum));
}
return hitRate;
}
int main()
{
string FilePath1("data.txt");
//string FilePath2("E:\\Matlab code\\recommendation system\\data\\movielens\\test.txt"); int row = ;
int col = ;
cout << "数据读取中..." << endl;
vector<vector<double> > train = txtRead<double>(FilePath1, row, col);
//vector<vector<double> > test = txtRead<double>(FilePath2, 462, 1591); cout << "利用二部图网络进行评分预测..." << endl;
vector<vector<double> > predictScores = ProbS(train);
txtWrite(predictScores, "predictScores.txt");
/*
cout << "计算命中率..." << endl;
vector<vector<double> > hitRate = ComputeHitRate(predictScores, test, 1591); txtWrite(hitRate, "hitRate.txt");
cout << "命中率结果保存完毕!" << endl;
*/
return ;
}
5.运行
预测结果:
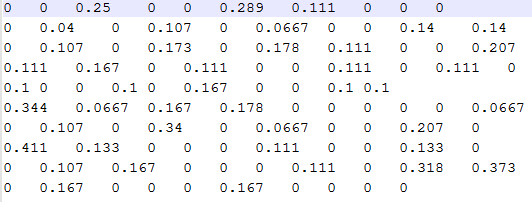
说明:预测为0的地方是在训练集中已经标记为1的地方,即明确了用户喜欢对应的商品,所以就没有必要对其进行预测,由于初始化预测评分的时候,全部初始化为0,所以没有必要预测的的元素为0.用户已经喜欢的是商品就没有必要再推荐给他(她)了,为了增加销售额,必须向用户尽可能推荐他(她)曾经不太注意的新商品,有了这些评分,系统就可以按照评分高低对用户推荐相应的商品了!比如上面的预测结果,对于第一个用户就要优先推荐第6个商品,其次推荐第3个商品,以此类推。
推荐系统之基于二部图的个性化推荐系统原理及C++实现的更多相关文章
- Paper Reading:个性化推荐系统的研究进展
论文:个性化推荐系统的研究进展 发表时间:2009 发表作者:刘建国,周涛,汪秉宏 论文链接:论文链接 本文发表在2009,对经典个性化推荐算法做了基本的介绍,是非常好的一篇中文推荐系统方面的文章. ...
- 基于baseline、svd和stochastic gradient descent的个性化推荐系统
文章主要介绍的是koren 08年发的论文[1], 2.3部分内容(其余部分会陆续补充上来).koren论文中用到netflix 数据集, 过于大, 在普通的pc机上运行时间很长很长.考虑到写文章目 ...
- 基于Spark的电影推荐系统(推荐系统~7)
基于Spark的电影推荐系统(推荐系统~7) 22/100 发布文章 liuge36 第四部分-推荐系统-实时推荐 本模块基于第4节得到的模型,开始为用户做实时推荐,推荐用户最有可能喜爱的5部电影. ...
- 基于Mahout的电影推荐系统
基于Mahout的电影推荐系统 1.Mahout 简介 Apache Mahout 是 Apache Software Foundation(ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域 ...
- 个性化推荐系统(七)--- ABTest ab测试平台
个性化推荐系统.搜索引擎.广告系统,这些系统都需要在线上不断上线,不断优化,优化之后怎么确定是好是坏.这时就需要ABTest来确定,最近想的办法.优化的算法.优化的逻辑数据是正向的,是有意义的,是提升 ...
- 基于pytorch的电影推荐系统
本文介绍一个基于pytorch的电影推荐系统. 代码移植自https://github.com/chengstone/movie_recommender. 原作者用了tf1.0实现了这个基于movie ...
- 【论文笔记】基于图机构的推荐系统:Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba
论文:https://arxiv.org/abs/1803.02349 题外话: 阿里和香港理工联合发布的这篇文章,整体来说,还挺有意思的. 刚开始随便翻翻看看结构图的时候,会觉得:这也能发文章 ...
- 基于Spark的电影推荐系统(电影网站)
第一部分-电影网站: 软件架构: SpringBoot+Mybatis+JSP 项目描述:主要实现电影网站的展现 和 用户的所有动作的地方 技术选型: 技术 名称 官网 Spring Boot 容器 ...
- 基于Spark的电影推荐系统(实战简介)
写在前面 一直不知道这个专栏该如何开始写,思来想去,还是暂时把自己对这个项目的一些想法 和大家分享 的形式来展现.有什么问题,欢迎大家一起留言讨论. 这个项目的源代码是在https://github. ...
随机推荐
- C#中的局部类
什么是局部类型? C# 2.0 引入了局部类型的概念.局部类型允许我们将一个类.结构或接口分成几个部分,分别实现在几个不同的.cs文件中. 局部类型适用于以下情况: (1) 类型特别大,不宜放在一个文 ...
- 用python3破解wingIDE
值得注意的是,python2的整除/在python3中变成了//,sha方法细化成了sha1和sha256,所以破解文件需要更改加密方式和整除部分的编码方式,经过修改后,这个文件可以完美演算出破解码, ...
- 发现第三方资源,chrome控制台
for(var i=0,tags=document.querySelectorAll('iframe[src],frame[src],script[src],link[rel=stylesheet], ...
- Win7桌面快捷方式全变成某个软件的图标,然后所有快捷方式都只打开这个图标的软件
电脑真是用到老学老好,之前没有遇到的情况,今天终于碰上了. 由于电脑桌面搜狗浏览器图标总不显示,于是选择快捷方式的打开方式为搜狗浏览器,结果,尼玛呀,全部快捷图标都变成搜狗的. 上网找了一下,双击就搞 ...
- bzoj 3270 博物馆(高斯消元)
[题意] 两人起始在s,t点,一人pi概率选择留在i点或等概率移动,问两人在每个房间相遇的概率. [思路] 把两个合并为一个状态,(a,b)表示两人所处的状态,设f[i]为两人处于i状态的概率.则有转 ...
- web.xml 配置介绍
这个不是原创,有点早了,具体从哪里来的已经记不得了.但是东西是实实在在的. 1.启动一个WEB项目的时候,WEB容器会去读取它的配置文件web.xml,读取<listener>和<c ...
- 快速入门linux系统的iptables防火墙 1 本机与外界的基本通信管理
概述 iptables是一种运行在linux下的防火墙组件,下面的介绍可以快速的学习iptables的入门使用. 特点(重要) 它的工作逻辑分为 链.表.规则三层结构. 数据包通过的时候,在对应表中, ...
- Cocos本地存储LocalStorage
HTML5 LocalStorage 本地存储 //存档 var stopResumeMenu4 = cc.MenuItemFont.create("存档", this.onSav ...
- 第三百二十五天 how can I 坚持
任何事情都是相对的,以后禁止专牛角尖. 今天在家堕落了一天,说好的把天气应用,照葫芦画瓢弄好,结果什么也没弄. 和你 有个毛线关系啊,哈哈,太逗了. 准备睡觉,一切随缘,反正想也没什么用,自己也搞不懂 ...
- 转】MyEclipse使用总结——在MyEclipse中设置jsp页面为默认utf-8编码
原博文出自于:http://www.cnblogs.com/xdp-gacl/p/3496161.html 感谢! 在MyEclispe中创建Jsp页面,Jsp页面的默认编码是"ISO-88 ...