qcow2快照原理
关键术语:
cluster 一个Qcow2 img文件由固定大小的单元组成,该单元称为cluster,默认大小为65536bytes/64K
sector 数据块读写的最小单元,大小为512字节
host cluster 位于Host上qcow2 img文件的cluster管理名称
guest cluster Guest所看到的virtual disk的cluster管理名称
Qcow2 Header Qcow2 img的文件头信息,占用第一个cluster
refcount Qcow2内部用于管理cluster的分配而维护的引用计数
refcount table 用于查找refcount的第一级表
refcount block 用于查找refcount的第二级表
L1 table 用于查找guest cluster到host cluster映射的第一级表
L2 table 用于查找guest cluster到host cluster映射的第二级表
IBA image block address
VBA virtual block address
Qcow2 Header
typedef struct QCowHeader {
uint32_t magic;
uint32_t version;
uint64_t backing_file_offset;
uint32_t backing_file_size;
uint32_t cluster_bits;
uint64_t size; / in bytes /
uint32_t crypt_method; / 0 - 未加密;1 - AES加密 /
uint32_t l1_size; / XXX: save number of clusters instead /
uint64_t l1_table_offset;
uint64_t refcount_table_offset;//refcount table在img中的偏移
//refcount table所占用的cluster数目
uint32_t refcount_table_clusters;
//镜像中快照的个数
uint32_t nb_snapshots;
uint64_t snapshots_offset;
/ The following fields are only valid for version >= 3 /
uint64_t incompatible_features;
uint64_t compatible_features;
uint64_t autoclear_features;
uint32_t refcount_order;
uint32_t header_length;
} QEMU_PACKED QCowHeader;
Qcow2 Host cluster management
Qcow2维护refcount用以管理image中cluster的分配和释放,refcount作用等同于引用计数,代表了指定的cluster的使用状态:
0: 表示空闲
1: 表示已使用
大于等于2:表示已使用并且写访问必须执行COW操作
refcounts通过二级表(类似页表)来进行索引,第一级表称为refcount table,其大小可变、连续、占用多个cluster,其表项中每一个条目为指向第二级表的指针(相对于img file的offset),每个条目占64bits。
第二级表称为refcount block,每个refcount block占用1个cluster,表中每个条目为2个字节大小的refcount。
给定一个相对于img file的offset可以通过下面计算关系得到refcount:
refcount_block_entries = (cluster_size / sizeof(uint16_t))
refcount_block_index = (offset / cluster_size) % refcount_block_entries
refcount_table_index = (offset / cluster_size) / refcount_block_entries
refcount_block = load_cluster(refcount_table[refcount_table_index]);
return refcount_block[refcount_block_index];
Qcow2在qemu中的实现是作为块驱动实现,主要代码在:
block/qcow2.c
block/qcow2-refcount.c
block/qcow2-cluster.c
block/qcow2-snapshot.c
block/qcow2-cache.c
实现原理
Qcow2 img的操作在qemu中都是作为一种块设备的blockdriver来实现的,qcow2对应的bdrv_create注册的函数是qcow2_create,创建流程如下:
qcow2_create
qcow2_create2
bdrv_create_file
bdrv_create
bdrv_create_co_entry //qemu协程入口
raw_create
由于qcow2 image是以文件形式存在的,在Qcow2的底层仍需要通过文件操作写入实实在在的数据,在Qcow2管理结构上挂在了一个child管理结构,指向了bdrv_file的block driver,对应的API为raw_create,raw_open等。所以在层次划分上Qcow2 block driver完成了Qcow2内部格式的转换,比如Guest到host的cluster mapping,l1,l2表的建立,索引查找等。
在image file的创建流程上,首先写入header,offset为0,大小为cluster size
blk_pwrite(blk, 0, header, cluster_size);
接着写入一个refcount table和一个refcount block
blk_pwrite(blk, cluster_size, refcount_table, 2 cluster_size);
分配3个cluster,讲上面使用的3个cluster占用
qcow2_alloc_clusters(blk_bs(blk), 3 cluster_size);
最后根据header的最新信息更新image的header
qcow2_update_header(blk_bs(blk));
下面是snapshot的header信息,每一个snapshot都有一个header,而header中的l1_table_offset标示了该snapshot所使用的l1表。
typedef struct QEMU_PACKED QCowSnapshotHeader {
/ header is 8 byte aligned /
uint64_t l1_table_offset;//该snapshot所使用的l1表
uint32_t l1_size;
uint16_t id_str_size;
uint16_t name_size;
uint32_t date_sec;
uint32_t date_nsec;
uint64_t vm_clock_nsec;
uint32_t vm_state_size;
uint32_t extra_data_size; / for extension /
/ extra data follows /
/ id_str follows /
/ name follows /
} QCowSnapshotHeader;
为了将磁盘镜像地址映射到镜像文件偏移,需要经历以下几步:
- 通过qcow2 header中的l1_table_offset字段获取L1 table的地址;
- 使用高(64 - l2_bits - cluser_bits)位的地址来索引L1 table,L1 table是一个数组,数组元素是一个64位的数;
- 通过L1 table中的表项来获取L2 table的地址;
- 通过L2 table中的表项来获取cluster的地址;
- 剩余的cluster_bits位来索引cluster内的位置。
如果找到的L1 table或L2 table的地址偏移为0,则表示磁盘镜像对应的区域尚未分配。
qcow2_co_preadv
a. qcow2_get_cluster_offset:根据offset获取cluster内的数据,根据offset获取L1表的索引,再获取L2表,继续在获取L2 table表里的存放数据的地址,然后根据该值返回不同的类别。
enum {
QCOW2_CLUSTER_UNALLOCATED, //该cluster为分配
QCOW2_CLUSTER_NORMAL,
QCOW2_CLUSTER_COMPRESSED, //压缩类别
QCOW2_CLUSTER_ZERO //内容为全0
};
b.根据qcow2_get_cluster_offset的返回内别做不同处理:
case QCOW2_CLUSTER_UNALLOCATED:如果存在于back file中则从backfile中获取
case QCOW2_CLUSTER_NORMAL:bdrv_co_preadv直接读取文件对应位置
case QCOW2_CLUSTER_ZERO:直接设为全0
case QCOW2_CLUSTER_COMPRESSED:用qcow2_decompress_cluster读取
c bdrv_co_preadv读取数据
d. 循环a-c直到读取所有cluster
qcow2_co_pwritev
a. qcow2_alloc_cluster_offset:得到一个cluster,对已存在的cluster直接返回文件中的位置,对未分配的
cluster会先分配在返回其位置
|--> handle_alloc:为末分配的区域分配新的cluster或者需要copy-on-write
|-->do_alloc_cluster_offset:根据guest的地址分配cluster
|-->qcow2_alloc_clusters:分配地址,按照cluster偏移
|-->alloc_clusters_noref:分配虚拟地址,如果对应cluster的refcount为0,表示已找到末使 用的cluster
|-->update_refcount:更新索引
b. 若为加密方式则调用qcow2_encrypt_sectors
c. bdrv_co_pwritev写数据
d. 更新L2 Table qcow2_alloc_cluster_link_l2
e. 循环a-d直到写完所有cluster
ref table的管理
qcow2_get_refcount
refcount_block_cache字段的引入在于优化refcount的管理,当cache中数据已存在时不需要在读磁盘
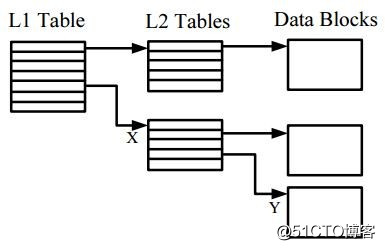
Qcow2 Cluster mapping(Guest->Host)
Guest OS看到的只是virtual disk,操作的是Guest Cluster,所以Qcow2镜像另个重要功能就是管理Guest Cluster到Host Cluster的映射。
Guest Cluster到Host Cluster的映射关系也是通过一个二级表来管理,称为L1表和L2表,L1表大小可变、连续、占用多个cluster,其表项中每一个条目为指向L2的指针(相对于img file的offset),每个条目占64bits。
L2表占用一个cluster,每个条目占64bits.
给定一个相对于virtual disk的offset,可以通过下面计算关系得到Host Cluster offset:
l2_entries = (cluster_size / sizeof(uint64_t))
l1_index = (offset / cluster_size) / l2_entries
l2_index = (offset / cluster_size) % l2_entries
l2_table = load_cluster(l1_table[l1_index]);
cluster_offset = l2_table[l2_index];
return cluster_offset + (offset % cluster_size)
转载于:https://blog.51cto.com/zybcloud/2159376
qcow2快照原理的更多相关文章
- 使用libvirtAPI打快照原理
参考: https://blog.51cto.com/3646344/2096347 https://blog.51cto.com/3646344/2096351(磁盘外部快照) API接口: htt ...
- 基于LVM(逻辑卷管理)的快照原理
一.为甚么不管多大的逻辑卷进行备份,快照都会在几秒之内完成? 快照在拍摄的一瞬间,系统会记录那个时间点逻辑卷的状态.数据等,此时拍下的快照相当于一张白纸.如图所示 快照做好后,随着时间的推移,源卷里的 ...
- mysql备份时的快照原理
实际上实验的结果表明,这里的 the first such read指的是:对同一个表或者不同表进行的第一次select语句建立了该事务中一致性读的snapshot. 其它update, delete ...
- Redis快照原理详解
本文对Redis快照的实现过程进行介绍,了解Redis快照实现过程对Redis管理很有帮助. Redis默认会将快照文件存储在Redis当前进程的工作目录中的dump.rdb文件中,可以通过配置dir ...
- lvm之创建/扩容/缩容/快照及关闭的全部流程操作记录
基本介绍Linux用户安装Linux 操作系统时遇到的一个最常见的难以决定的问题就是如何正确地给评估各分区大小,以分配合适的硬盘空间.随着 Linux的逻辑盘卷管理功能的出现,这些问题都迎刃而解, l ...
- QEMU 使用的镜像文件:qcow2 与 raw
qcow2 的基本原理 qcow2 镜像格式是 QEMU 模拟器支持的一种磁盘镜像.它也是可以用一个文件的形式来表示一块固定大小的块设备磁盘.与普通的 raw 格式的镜像相比,有以下特性: 更小的空间 ...
- hadoop之快照
在hadoop第前几个版本中是没有快照功能的,2.x中是有这个特性的 Hadoop 2.x HDFS新特性 HDFS快照 HDFS快照 在2.x终于实现了快照 设置一个目录为可快照 ...
- sqlserver 关于快照
数据库快照:是数据库某一时间点的视图,快照涉及最初目的是为了报表服务,快照还可以和镜像结合来达到读写分离的目的 数据库快照:是sqlserver数据库的只读静态视图快照的作用:1 提供了一个静态的视图 ...
- Redis的两种持久化方式-快照持久化和AOF持久化
Redis为了内部数据的安全考虑,会把本身的数据以文件形式保存到硬盘中一份,在服务器重启之后会自动把硬盘的数据恢复到内存(redis)的里边,数据保存到硬盘的过程就称为"持久化"效 ...
随机推荐
- PTA数据结构与算法题目集(中文) 7-43字符串关键字的散列映射 (25 分)
PTA数据结构与算法题目集(中文) 7-43字符串关键字的散列映射 (25 分) 7-43 字符串关键字的散列映射 (25 分) 给定一系列由大写英文字母组成的字符串关键字和素数P,用移位法定义 ...
- Python 参数使用总结
Python 中参数的传递非常灵活,不太容易记住理解,特整理如下备忘: 普通参数 即按照函数所需的参数,对应位置传递对应的值,可以对应 Java 中的普通参数 def max(a, b): if a ...
- Shell:Day03笔记
编程原理:1.编程结束 驱动 硬件默认是不能使用的 CPU控制硬件 不同的厂家硬件设备之间需要进行指令沟通,就需要驱动程序来进行“翻译” 编程语言的分类: 高级语言.超高级语言需要翻 ...
- stdio.h file not found mac catalina clion 头文件 找不到
问题:mac update catalina 版本之后引发的include文件问题 近期Mac 版本升级到catalina版本,使用CLion调试c/c++程序,莫名其妙的发现,有些头文件incl ...
- C语言 文件复制
有很多人会问,学会C语言能干啥?,就只能控制台敲个数学题,做个界面都没有的贪吃蛇么? 刚开始的我,也是这样想的,但慢慢深入C语言后,我才领略到C的强大,C的万能.小到游戏破解,加解密算法,大到设备驱动 ...
- Python常见数据结构-Set集合
集合基本特点 集合是无序的,且集合内无重复值. 集合不支持索引和切片 集合常见操作及方法 s1 = {1,2,3} s2 = {2,3,4} s1.add(4) #.add()方法添加一个元素 s1. ...
- 实战if-else 过多详解
1.本文实例代码仅仅是俩个小例子. package com.example.demo.pattern.ifElse; import java.util.HashMap; import java.uti ...
- Codeup 25594 Problem H 例题5-8 Fibonacci数列
题目描述 输入一个正整数n,求Fibonacci数列的第n个数.Fibonacci数列的特点:第1,2个数为1,1.从第3个数开始,概述是前面两个数之和.即: 1,1,2,3,5,8,13,21 - ...
- AJ学IOS(21)UIApplication设置程序图标右上⾓红⾊数字_联⺴指⽰器等
AJ分享,必须精品 效果简介 UIApplication的运用,有很多相如:进⾏行⼀一些应⽤用级别的操作等等,打开网页,打开电话拨号和信息等.. 什么是UIApplication ● UIApplic ...
- day01,了解gcc
今天主要是学一下gcc 功能选项: 一. 1. gcc -E:表示预处理,把指令处理掉 2.gcc -o:改变目标文件名称 3. gcc -c: 表示只编译不链接(也就是不生成a.out) 4. g ...