python数据拼接: pd.concat
1.concat
concat函数是在pandas底下的方法,可以将数据根据不同的轴作简单的融合
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False)
参数说明
objs: series,dataframe或者是panel构成的序列lsit
axis: 需要合并链接的轴,0是行,1是列
join:连接的方式 inner,或者outer
其他一些参数不常用,用的时候再补上说明。
1.1 相同字段的表首尾相接
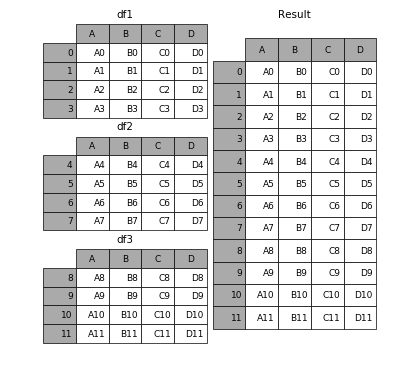
# 现将表构成list,然后在作为concat的输入
In [4]: frames = [df1, df2, df3] In [5]: result = pd.concat(frames)
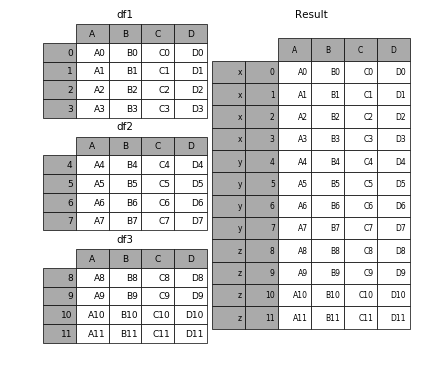
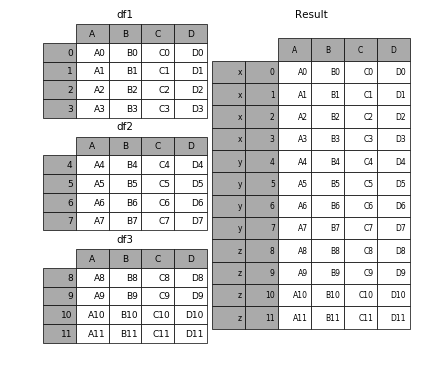
要在相接的时候在加上一个层次的key来识别数据源自于哪张表,可以增加key参数
In [6]: result = pd.concat(frames, keys=['x', 'y', 'z'])
效果如下
1.2 横向表拼接(行对齐)
1.2.1 axis
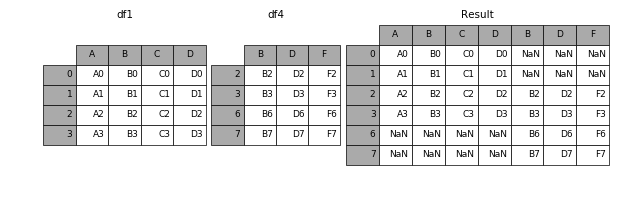
当axis = 1的时候,concat就是行对齐,然后将不同列名称的两张表合并
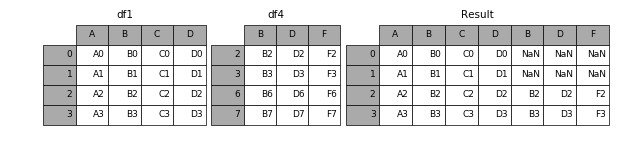
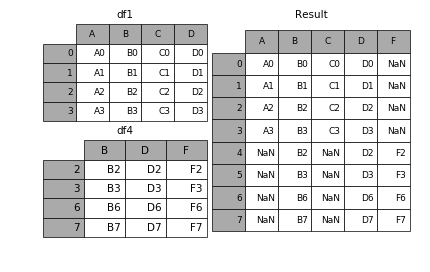
In [9]: result = pd.concat([df1, df4], axis=1)
1.2.2 join
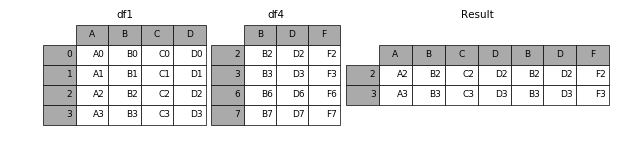
加上join参数的属性,如果为’inner’得到的是两表的交集,如果是outer,得到的是两表的并集。
In [10]: result = pd.concat([df1, df4], axis=1, join='inner')
1.2.3 join_axes
如果有join_axes的参数传入,可以指定根据那个轴来对齐数据
例如根据df1表对齐数据,就会保留指定的df1表的轴,然后将df4的表与之拼接
In [11]: result = pd.concat([df1, df4], axis=1, join_axes=[df1.index])
1.3 append
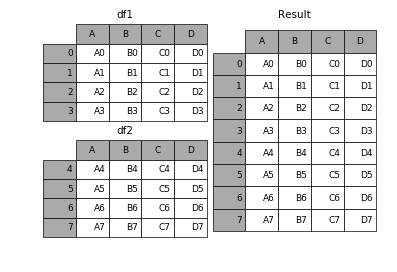
append是series和dataframe方法,使用它就是默认沿着列进行拼接(axis=0,列对齐)
In [12]: result = df1.append(df2)
1.4 无视index的concat
如果两个表的index都没有实际含义,使用ignore_index参数,置true,合并的两个表就会根据列字段对齐,然后合并。最后再重新整理一个新的index。
1.5 合并的同时增加区分数据组的键
前面提到的keys参数可以用来给合并后的表增加key来区分不同的表数据来源
1.5.1 可以直接用key参数实现
In [27]: result = pd.concat(frames, keys=['x', 'y', 'z'])
1.5.2 传入字典来增加分组键
In [28]: pieces = {'x': df1, 'y': df2, 'z': df3}
In [29]: result = pd.concat(pieces)
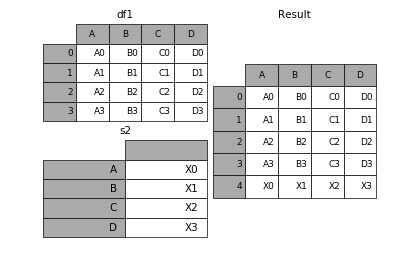
1.6 在dataframe中加入新的行
append方法可以将series和字典中的数据作为dataframe的新的一行插入。
In [34]: s2 = pd.Series(['X0', 'X1', 'X2', 'X3'], index=['A', 'B', 'C', 'D']) In [35]: result = df1.append(s2, ignore_index=True)
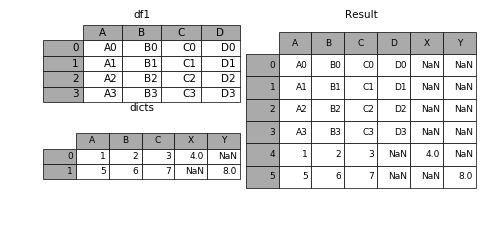
1.7 表格列字段不同的表合并
如果遇到两张表的列字段本来就不一样,但又想将两个表合并,其中无效的值用nan来表示。那么可以使用ignore_index来实现。
In [36]: dicts = [{'A': 1, 'B': 2, 'C': 3, 'X': 4},
....: {'A': 5, 'B': 6, 'C': 7, 'Y': 8}]
....:
In [37]: result = df1.append(dicts, ignore_index=True)
转载于https://blog.csdn.net/mr_hhh/article/details/79488445
python数据拼接: pd.concat的更多相关文章
- pandas中,dataframe 进行数据合并-pd.concat()
``# 通过数据框列向(左右)合并 a = pd.DataFrame(X_train) b = pd.DataFrame(y_train) # 合并数据框(合并前需要将数据设置成DataFrame格式 ...
- 两表拼接 pd.concat
a = pd.DataFrame([[1,2,3], [4,5,6], [7,8,9]],columns=['a','b','c']) b = pd.DataFrame([[11,23,45], [2 ...
- 9-Pandas之数据合并与轴向连接(pd.concat()的详解)
数据合并:由于数据可能是不同的格式,且来自不同的数据源,为了方便之后的处理与加工,需要将不同的数据转换成一个DataFrame. Numpy中的concatenate().vstack().hstac ...
- python基础2 数据类型、数据拼接、数据转换
一.数据类型 1.字符串 字符串英文string,简写str,只要是被[单/双/三引号]这层皮括起来的内容,不论那个内容是中文.英文.数字甚至火星文.只要是被括起来的,就表示是字符串类型 如:prin ...
- python书籍推荐:Python数据科学手册
所属网站分类: 资源下载 > python电子书 作者:today 链接:http://www.pythonheidong.com/blog/article/448/ 来源:python黑洞网 ...
- 预测python数据分析师的工资
前两篇博客分别对拉勾中关于 python 数据分析有关的信息进行获取(https://www.cnblogs.com/lyuzt/p/10636501.html)和对获取的数据进行可视化分析(http ...
- pd.concat/merge/join
pandas的拼接分为两种: 级联:pd.concat, pd.append 合并:pd.merge, pd.join 一.回顾numpy.concatenate 生成1个6*3的矩阵,一个2*3的矩 ...
- python数据分组运算
摘要: pandas 的 GroupBy 功能可以方便地对数据进行分组.应用函数.转换和聚合等操作. # 原作者:lionets GroupBy 分组运算有时也被称为 “split-apply-c ...
- 干货!小白入门Python数据科学全教程
前言 本文讲解了从零开始学习Python数据科学的全过程,涵盖各种工具和方法 你将会学习到如何使用python做基本的数据分析 你还可以了解机器学习算法的原理和使用 说明 先说一段题外话.我是一名数据 ...
随机推荐
- centos7下yourcompleteme安装
以前装过一回,没成功,现在再来一次 yourcompleteme git https://github.com/ycm-core/YouCompleteMe#installation 检查软件版本 v ...
- R WLS矫正方差非齐《回归分析与线性统计模型》page115
rm(list = ls()) A = read.csv("data115.csv") fm = lm(y~x1+x2,data = A) coef(fm) A.cooks = c ...
- kubernetes 1.17.2 结合 Ceph 13.2.8 实现 静态 动态存储 并附带一个实验
关于部署和相关原理 请自行搜索 这里 给出我的操作记录和排查问题的思路 这一节对后面的学习有巨大的作用!!! [root@bs-k8s-ceph ~]# ceph -s cluster: -1a9a- ...
- python二维图像输出操作大全(非常全)!
//2019.07.141.matplotlib模块输出函数图像应用时主要用的是它的ptplot模块,因此在导入使用该模块时可以直接用以下语句:import matplotlib.pyplot as ...
- 洛谷 P1934 封印
题目传送门 解题思路: f[i]表示打到第i层的最小值 AC代码: #include<iostream> #include<cstdio> using namespace st ...
- Vue - 项目配置 ( element , 安装路由 , 创建路由 )
1,安装element : vue add element 2,安装路由 : vue add router 3,创建路由的过程 : (1) 新建 vu ...
- 指令——less
一.Liunx系统下的一般命令格式. 命令——实际上就是在Liunx终端中,在命令行中输入的内容. Liunx中一个命令的完整格式为: #指令主体(空格) [选项](空格) [操作对象] 指令主体—— ...
- C#验证码 使用GDI绘制验证码
首先展示一下效果图如下: C#中的GDI特别方便,很多方法我们只要简单的调用就可以实现很复杂的功能.具体实现过程如下: 首先创建一个windows窗体应用(测试使用,实际开发winform程序时在需要 ...
- 75.Python中ORM聚合函数详解:Sum
Sum:某个字段的总和. 1. 求图书的销售总额,示例代码如下: from django.http import HttpResponse from django.db import connecti ...
- mitmproxy(TLS错误)
一.原来的基础上添加代码 """ This inline script allows conditional TLS Interception based on a us ...