新闻网大数据实时分析可视化系统项目——18、Spark SQL快速离线数据分析
1.Spark SQL概述
1)Spark SQL是Spark核心功能的一部分,是在2014年4月份Spark1.0版本时发布的。
2)Spark SQL可以直接运行SQL或者HiveQL语句

3)BI工具通过JDBC连接SparkSQL查询数据
4)Spark SQL支持Python、Scala、Java和R语言

5)Spark SQL不仅仅是SQL

6)Spark SQL远远比SQL要强大

7)Spark SQL处理数据架构
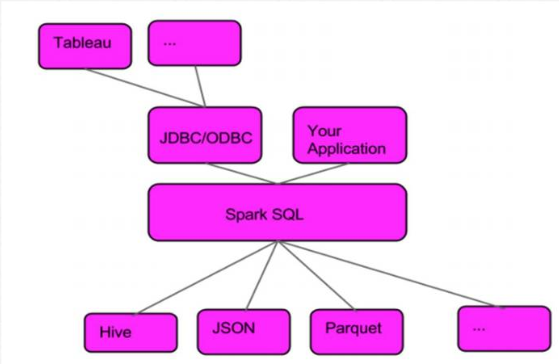
8)Spark SQL简介
Spark SQL is a Spark module for structured data processing

9)Spark SQL的愿景
a)Write less code
对不同的数据类型使用统一的接口来读写。

b)Read less data
提升大数据处理速度最有效的方法就是忽略无关的数据。
(1)使用列式存储(columnar formats),比如Parquet、ORC、RCFile
(2)使用分区裁剪(partitioningpruning),比如按天分区,按小时分区等
(3)利用数据文件中附带的统计信息进行剪枝:例如每段数据都带有最大值、最小值和NULL值等统计信息,当某一数据段肯定不包含查询条件的目标数据时,可以直接跳过这段数据。(例如字段age某段最大值为20,但查询条件是>50岁的人时,显然可以直接跳过这段)
(4)将查询源中的各种信息下推至数据源处,从而充分利用数据源自身的优化能力来完成剪枝、过滤条件下推等优化。
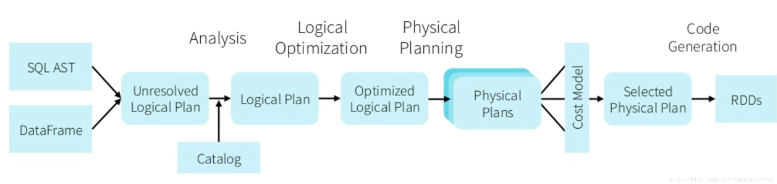
c)Let the optimizer do the hard work
Catalyst优化器对SQL语句进行优化,从而得到更有效的执行方案。即使我们在写SQL的时候没有考虑这些优化的细节,Catalyst也可以帮我们做到不错的优化结果。
2.Spark SQL服务架构

3.Spark SQL 与Hive集成(spark-shell)
1)需要配置的项目
a)将hive的配置文件hive-site.xml拷贝到spark conf目录,同时添加metastore的url配置。
vi hive-site.xml
<property>
<name>hive.metastore.uris</name>
<value>thrift://bigdata-pro01.kfk.com:9083</value>
</property>
b)拷贝hive中的mysql jar包到spark的jar目录下
cp hive-0.13.1-bin/lib/mysql-connector-java-5.1.27-bin.jar spark-2.2-bin/jars/
c)检查spark-env.sh 文件中的配置项
vi spark-env.sh
HADOOP_CONF_DIR=/opt/modules/hadoop-2.5.0/etc/hadoop
2)启动服务
a)检查mysql是否启动
#查看状态
service mysqld status
#启动
service mysqld start
b)启动hive metastore服务
bin/hive --service metastore
c)启动hive
bin/hive
show databases;
create database kfk;
create table if not exists test(userid string,username string)ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS textfile;
load data local inpath "/opt/datas/kfk.txt" into table test;
本地kfk.txt文件
more /opt/datas/kfk.txt
0001 spark
0002 hive
0003 hbase
0004 hadoop
d)启动spark-shell
bin/spark-shell
spark.sql("select * from kfk.test").show
0001 spark
0002 hive
0003 hbase
0004 hadoop
4.Spark SQL 与Hive集成(spark-sql)
启动spark-sql
bin/spark-sql
#查看数据库
show databases;
default
kfk
#使用数据库
use kfk
#查看表
show tables;
test
#查看表数据
select * from test;
5.Spark SQL之ThriftServer和beeline使用
1)启动ThriftServer
sbin/start-thriftserver.sh
2)启动beeline
bin/beeline
!connect jdbc:hive2://bigdata-pro02.kfk.com:10000
#查看数据库
show databases;
#查看表数据
select * from kfk.test;
6.Spark SQL与MySQL集成
启动spark-shell
sbin/spark-shell
:paste
val jdbcDF = spark
.read
.format("jdbc")
.option("url", "jdbc:mysql://bigdata-pro01.kfk.com:3306/test")
.option("dbtable", "spark1")
.option("user", "root")
.option("password", 123456)
.load()
ctr+d
#打印读取数据
jdbcDF.show
7.Spark SQL与HBase集成
Spark SQL与HBase集成,其核心就是Spark Sql通过hive外部表来获取HBase的表数据。
1)拷贝HBase的包和hive包到spark 的jars目录下

2)启动spark-shell
bin/spark-shell
val df =spark.sql("select count(1) from weblogs").show
新闻网大数据实时分析可视化系统项目——18、Spark SQL快速离线数据分析的更多相关文章
- 新闻网大数据实时分析可视化系统项目——2、linux环境准备与设置
1.Linux系统常规设置 1)设置ip地址 使用界面修改ip比较方便,如果Linux没有安装操作界面,需要使用命令:vi /etc/sysconfig/network-scripts/ifcfg-e ...
- 新闻网大数据实时分析可视化系统项目——19、Spark Streaming实时数据分析
1.Spark Streaming功能介绍 1)定义 Spark Streaming is an extension of the core Spark API that enables scalab ...
- 新闻网大数据实时分析可视化系统项目——14、Spark2.X环境准备、编译部署及运行
1.Spark概述 Spark 是一个用来实现快速而通用的集群计算的平台. 在速度方面, Spark 扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理 ...
- 新闻网大数据实时分析可视化系统项目——21、大数据Web可视化分析系统开发
1.基于业务需求的WEB系统设计 2.下载Tomcat并创建Web工程并配置相关服务 下载tomcat,解压并启动tomcat服务. 1)新建web app项目 创建好之后的效果 2)对tomcat进 ...
- 新闻网大数据实时分析可视化系统项目——15、基于IDEA环境下的Spark2.X程序开发
1.Windows开发环境配置与安装 下载IDEA并安装,可以百度一下免费文档. 2.IDEA Maven工程创建与配置 1)配置maven 2)新建Project项目 3)选择maven骨架 4)创 ...
- 新闻网大数据实时分析可视化系统项目——13、Cloudera HUE大数据可视化分析
1.Hue 概述及版本下载 1)概述 Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python ...
- 新闻网大数据实时分析可视化系统项目——8、Flume数据采集准备
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并 ...
- 新闻网大数据实时分析可视化系统项目——7、Kafka分布式集群部署
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cloudera.Apache Storm.Spa ...
- 新闻网大数据实时分析可视化系统项目——4、Zookeeper分布式集群部署
ZooKeeper 是一个针对大型分布式系统的可靠协调系统:它提供的功能包括:配置维护.名字服务.分布式同步.组服务等: 它的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效.功能稳定的 ...
随机推荐
- 最全BT磁力搜索引擎索引(整理分享,每日更新)
btaa.xyz:http://www.veee.xyz/(可以访问,知名的BT磁力搜索,资源多,建议手机访问) 以下无法访问 idope.se:https://idope.se/(无法访问,资源丰富 ...
- PLSQL报错: ORA-12170:TNS connect timeout occurred
本人的问题已解决,先在安装oracle的服务器上黑窗口输入tnsping,提示说no listener,这是监听服务没有打开. 打开服务后还是不行,最后原因是服务器的网络有防火墙的问题,关掉防火墙连接 ...
- python面试题手动总结答案锦集
数据类型 字符串 1.列举python中的基本数据类型 数字:int 布尔值:bool 字符串:str 列表:list 元组:tuple 字典:dict 集合:set 然后我们需要了解一些运算符,应为 ...
- 二 Spring的IOC入门,环境搭建,Spring测试类
IOC:inversion of Control 控制反转,Spring框架的核心.削减计算机程序的耦合问题,把对象(例如JDBC)的创建权交给Spring. IOC的两种类型: 依赖注入: 依赖查 ...
- npm安装包时报错:Error: EPERM: operation not permitted, rename
解决方法:先执行 npm cache clean -force在安装需要的包.
- Eclipse上将maven项目部署到tomcat,本地tomcat下,webapps下,web-inf下lib下没有jar包决绝方案
右键项目选择properties ,选择Deployment Assembly , 右边点击Add 然后选择 Java Build Path Entries ,,,next , 选择Mave ...
- 吴裕雄--天生自然PythonDjangoWeb企业开发:学员管理系统- 前台
开发首页 做一个简单的用户提交申请的表单页面. 首先在student/views.py文件中编写下面的代码: # -*- coding: utf-8 -*- from __future__ impor ...
- day 10 作业
# 2.写函数,接收n个数字,求这些参数数字的和. def sum_func(*args): total = 0 for i in args: total += i return total prin ...
- jdk 档案库(包含历史版本)
http://java.sun.com/products/archive/ 参考:https://blog.csdn.net/shiluyong8068/article/details/7894747 ...
- Ionic3记录之核心代码分析
app.module.ts app的根模块,一些插件的引用需要在这里声明,告诉APP如何组装应用: app.componet.ts app的根组件,主要用来APP启动时和启动后的操作;